朱辉(茶水): Linux Kernel iowait 时间的代码原理
linux阅码场1 人气:6本文系转载,著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者: 朱辉(茶水)
来源: 微信公众号linux阅码场(id: linuxdev)

作者介绍
朱辉,个人主页 http://teawater.github.io/,微信公众号茶水侃山(cschatcs)。
做过几年模拟器,做过几年GDB,在小米电视做过几年Linux内核优化,主要围绕MM。
现在在HyperHQ当软件工程师。
更新记录
2017.12.15:
对扩展文章的问题描述进行了精确化。
2017.12.10:
根据张骁和宋宝华老师的建议,将结尾的错误进行了修正。
增加一篇扩展阅读。
增加了对CPU负载均衡问题的讲解。
之前在我热爱的公众号Linux阅码场看到The precise meaning of I/O wait time in Linux 这篇文章,感觉写的不错,就是没有落实到源码上感觉稍微有点晦涩,于是自己读了一下代码。
当task发生iowait的时候,内核对他们的处理方法是将task切换出去,让可运行的task先运行,而在切换出去前,会将其in_iowait设置为1,再次被唤醒的时候in_iowait被设置为原值。相关函数io_schedule,io_schedule_timeout,mutex_lock_io,mutex_lock_io_nested。
例如:
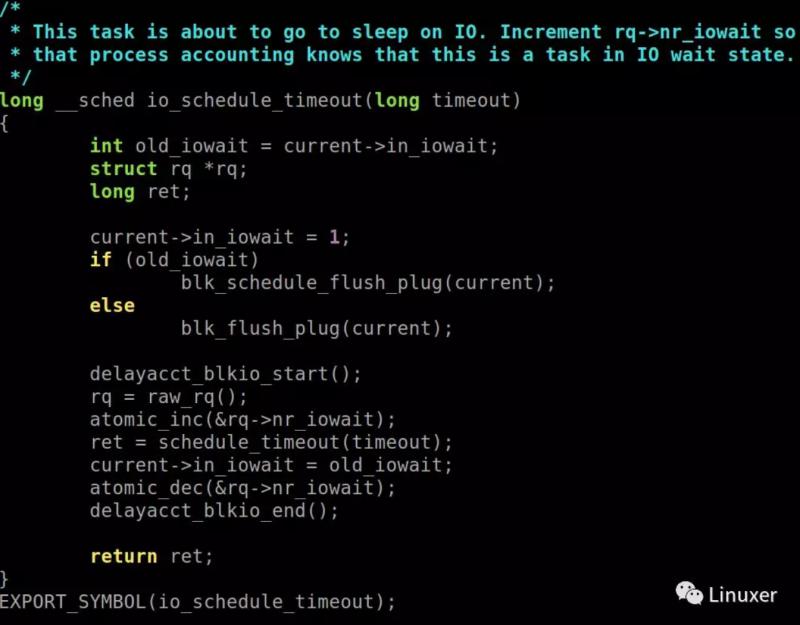
由此可见in_iowait表明了这个task是否在iowait。
另外要注意的是,这几个切换函数除了mutex_lock_io,mutex_lock_io_nested会设置task运行状态为TASK_UNINTERRUPTIBLE外,内核在调用io_schedule,io_schedule_timeout前都会设置task运行状态TASK_UNINTERRUPTIBLE。
在进程切换函数__schedule在切换task的时候,如果被切换出的task的in_iowait为真,则会对这个CPU的运行队列rq结构中的nr_iowait加1。
因为前面对task已经被设置为TASK_UNINTERRUPTIBLE,则task需要被唤醒,对nr_iowait的减少操作也是在task唤醒函数来做的。
由此可见nr_iowait可以表明某CPU上是否有task在iowait,以及数量。
因为处于iowait的task是TASK_UNINTERRUPTIBLE状态,其并不在就绪队列中,所以其也没有被CPU负载均衡到其他CPU的可能,所以nr_iowait也不需要处理负载均衡问题。
当累加系统idle时间的时候,如果CPU的nr_iowait为真,也就是当前这个cpu有task在等待iowait,则记录为iowait时间。
在打开NO_HZ的内核中,相关代码在update_ts_time_stats。
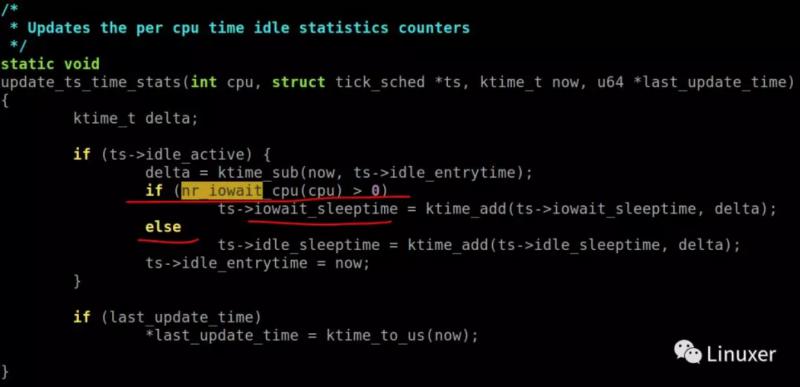
而没打开的则在 account_idle_time。

当相关/proc/stat接口被访问时,get_iowait_time就会访问这个时间并返回。
综上所述,iowait时间就是CPU idle时间,但是这时候CPU上不是完全没TASK需要运行,而是休眠的task中有一个或者若干个是iowait的task。
当然idle和iowait的时候CPU上还有idle task。
最后推荐一篇阿里内核组的文章作为扩展阅读Kernel Documents/new iowait calculation (http://link.zhihu.com/?target=http%3A//kernel.taobao.org/index.php%3Ftitle%3DKernel_Documents/new_iowait_calculation)
比较有意思是这里:
+ wait_event_interruptible_hrtimeout(ctx->wait,
+ aio_read_events(ctx, min_nr, nr, event, &ret), until);无论超时值until是什么值,都会调用wait_event_interruptible_hrtimeout,虽然是hrtimer实时性已经很高,但是在用来实际处理wait的宏__wait_event_hrtimeout可以看到hrtimer初始化使用的是:
hrtimer_start_range_ns(&__t.timer, timeout,\
current->timer_slack_ns,\
HRTIMER_MODE_REL);\其中第三个参数current->timer_slack_ns是传递给hrtimer的触发范围,因为hrtimer实时性高,但是频繁触发系统显然受不了,所以每次hrtimer触发都会将时间范围内的timer都处理掉(见__hrtimer_run_queues)。所以timeout+current->timer_slack_ns才是设置的hrtimer的最后触发时间,current->timer_slack_ns的默认值是50000,也就是代表50000纳秒。也就是这个时钟最久会在50000纳秒后触发,当然也可能被之前的hrtimer触发。
所以在wait_event_interruptible_hrtimeout中,一旦ctx->wait未能就绪,即使设置超时时间为0,也很可能要调用一次schedule,这导致iowait时间相差很大,也还很大幅度伤害了性能。
而这个问题也被5f785de588735306ec4d7c875caf9d28481c8b21进行了修复,这段代码改成了:
- wait_event_interruptible_hrtimeout(ctx->wait,
- aio_read_events(ctx, min_nr, nr, event, &ret), until);
+ if (until.tv64 == 0)
+ aio_read_events(ctx, min_nr, nr, event, &ret);
+ else
+ wait_event_interruptible_hrtimeout(ctx->wait,
+ aio_read_events(ctx, min_nr, nr, event, &ret),
+ until);
从而在until为0的时候,直接调用aio_read_events。应该就不会再有那么明显的iowait问题了,另外也因此这个修复让io_getevents的调用得到了超过百倍的性能提升。
当然这个iowait不够精确的原因还是存在,一旦因为需要发生task切换,还是会有不够精确的问题。
最后要吐槽一下aio的设计,都aio了还需要wait吗?
更多精彩更新中……欢迎关注微信公众号:linux阅码场(id: linuxdev)
加载全部内容