Python实现获取弹幕的两种方式分享
松鼠爱吃饼干 人气:0前言
弹幕可以给观众一种“实时互动”的错觉,虽然不同弹幕的发送时间有所区别,但是其只会在视频中特定的一个时间点出现,因此在相同时刻发送的弹幕基本上也具有相同的主题,在参与评论时就会有与其他观众同时评论的错觉。
在国内的视频网站里,弹幕先是从A站被大家知道,随后B站发扬光大,导致现在全部视频平台和部分漫画平台都有弹幕功能,在欣赏动漫的同时,还能看一下大家的看法,也是一件非常有趣的事。
现在,弹幕文化成为了很多人看视频的习惯,今天就教大家如何获取弹幕的数据
环境
- python 3.8
- pycharm
- requests
- re
获取方式一: <简单, 但是弹幕很少>
先打开网站,找到你想要的视频,然后在网址bili前加个i,这样你就可以直接的找到弹幕的地址
复制地址打开,你就可以看到你想要的弹幕数据,写代码时直接请求这个地址就可以了
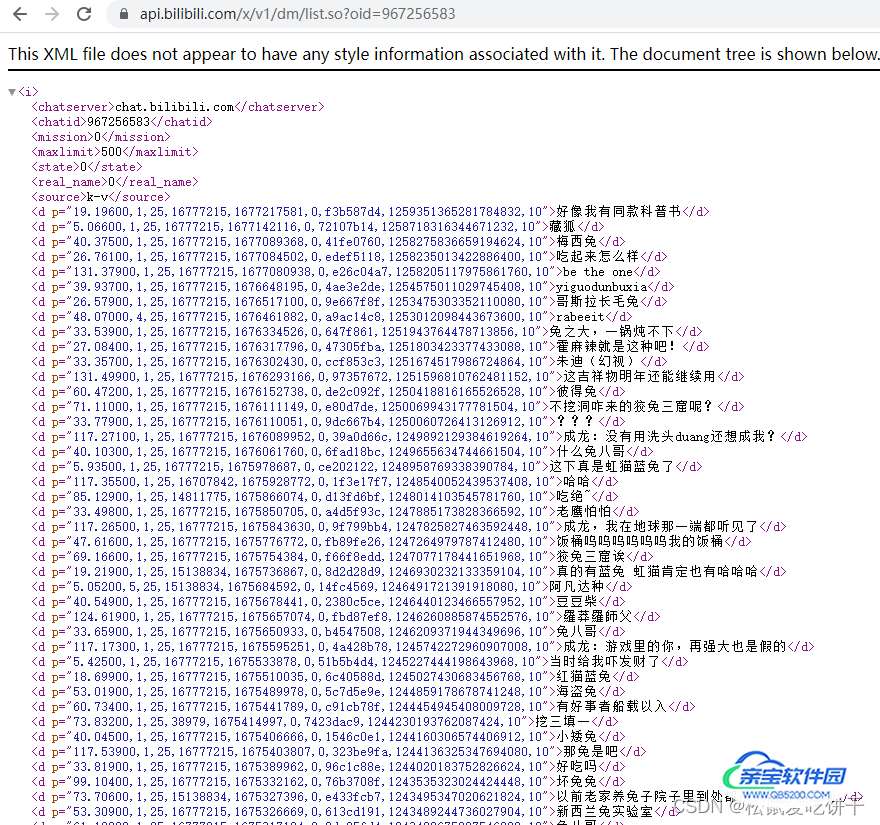
请求数据
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=967256583'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response)

获取数据
response.encoding = 'utf-8' print(response.text)
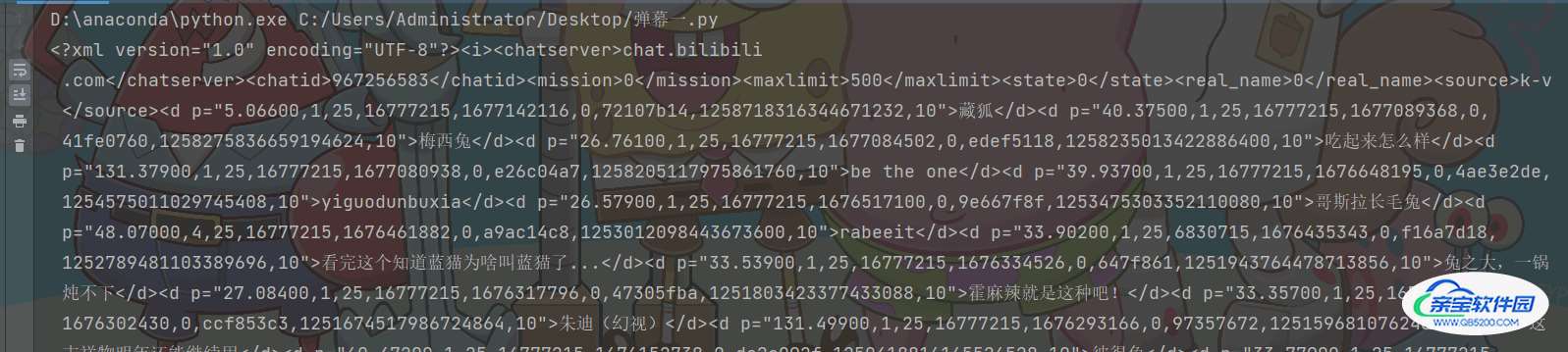
解析数据
content_list = re.findall('<d p=".*?">(.*?)</d>', response.text)
content = '\n'.join(content_list)
print(content_list)

保存数据
with open('方式一.txt', mode='a', encoding='utf-8') as f:
f.write(content)
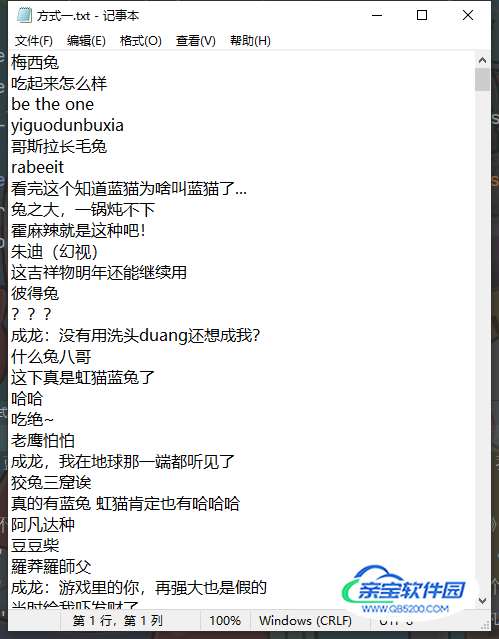
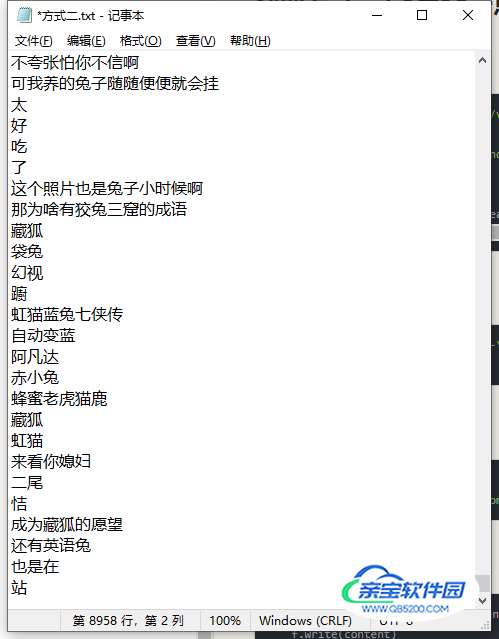
获取方式二: <复杂一点点, 弹幕比较多,按日期来>
先回到视频播放地址,打开开发者工具,选择其他日期天数,然后会出现带有当天日期的数据包,右边就是我们要找的url地址

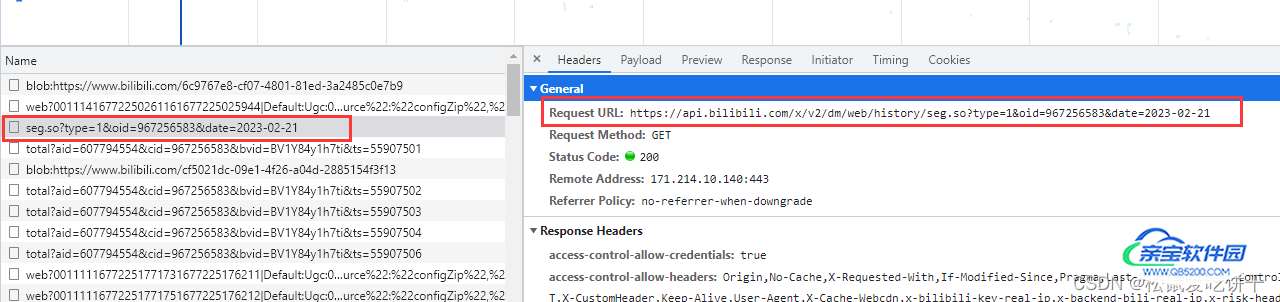
也出现了乱码的弹幕数据

请求数据
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=967256583&date=2023-02-23'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
'cookie': '加自己的'
}
response = requests.get(url=url, headers=headers)
解析数据
content_list = re.findall('[\u4e00-\u9fa5]+', response.text)
content = '\n'.join(content_list)
翻页
for page in range(1, 24):
url = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=967256583&date=2023-02-{page}'
保存数据
with open('方式二.txt', mode='a', encoding='utf-8') as f:
f.write(content)
print(content_list)
加载全部内容