C++ vector的基本使用示例详解
rygttm 人气:0一、vector和string的联系与不同
1.
vector底层也是用动态顺序表实现的,和string是一样的,但是string默认存储的就是字符串,而vector的功能较为强大一些,vector不仅能存字符,理论上所有的内置类型和自定义类型都能存,vector的内容可以是一个自定义类型的对象,也可以是一个内置类型的变量。
2.
vector在使用时需要进行类模板的实例化,因为传递的模板参数不同,则vector存储的元素类型就会有变化,所以在使用vector的时候要进行类模板的显式实例化。
类模板的第二个参数是空间配置器,这个学到后面再说,而且这个参数是有缺省值的,我们只用这个缺省值就欧克了,所以在使用vector时,只需要关注第一个参数即可。

void test_vector1()
{
string s;
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//string和vector底层都是用数组实现的,所以他们都支持迭代器、范围for、下标+[]的遍历方式
for (size_t i = 0; i < v.size(); i++)
{
cout << v[i] << " ";//string和vector的底层都是数组,所以可以使用[],但list就不能使用[]了,所以万能的方法是迭代器。
}
cout << endl;
vector<int>::iterator it = v.begin();//iterator实际是某种类型的重定义,在使用时要指定好类域。
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : v)//不就是迭代器吗?
{
cout << e << " ";
}
cout << endl;
cout << v.max_size() << endl;//int是10亿多,因为int占4个字节,42亿÷4。
cout << s.max_size() << endl;//max_size的大小是数据的个数,我的编译器的char是21亿多。不用管他,这接口没价值。
//vector<char> vstr;
//string str;
//vector<char>不能替代string,即使两者都是字符数组也不行,因为string有\0
}
二、vector的扩容操作
1.resize() (缺省值为匿名对象)&& reserve()
1.
对于string和vector,reserve和resize是独有的,因为他们的底层都是动态顺序表实现的,list就没有reserve和resize,因为他底层是链表嘛。
2.
对于reserve这个函数来说,官方并没有将其设定为能够兼容实现缩容的功能,明确规定这个函数在其他情况下,例如预留空间要比当前小的情况下,这个函数的调用是不会引起空间的重新分配的,也就是说容器vector的capacity是不会被影响的。

3.
有的人可能认为缩容只要丢弃剩余的空间就好了,但其实没有那么简单,你从C语言阶段free空间不能分两次free进行释放就可以看出来,一块已经申请好的空间就是一块儿独立的个体,不能说你保留空间的一部分丢弃剩余的一部分,这样是不行的,本质上和操作系统的内存管理有关系,如果对这部分知识有兴趣,可以下去研究一下。
4.
但值得注意的是缩容表面看起来是降低了空间的使用率,想要提高程序的效率,但实际上并未提高效率,缩容是需要异地缩容的,需要重新开空间和拷贝数据,代价不小,所以平常不建议对空间进行缩容。

5.
vector的resize和string的resize同样具有三种情况,但vector明显功能比string要更健壮一些,string类型只能针对于字符,而vector在使用resize进行初始化空间数据时,对内置类型和自定义类型均可以调用对应的拷贝构造来初始化,所以其功能更为健壮,默认将整型类型初始化为0,指针类型初始化为空指针。

void test_vector2()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
//resize和reserve对于vector和string是独有的,对于list而言,就没有reserve和resize
cout << v.capacity() << endl;
v.reserve(10);
cout << v.capacity() << endl;
v.reserve(4);
cout << v.capacity() << endl;//并不会缩容,缩容并不会提高效率,缩容是有代价的,某种程度上就是以空间换时间。
v.resize(8);//int、指针这些内置类型的默认构造就把他们初始化为0和空指针这些。
v.resize(15, 1);
v.resize(3);//不缩容,也是采用惰性删除的方式,将size调整为3就可以了,显示数组内容的时候按照size大小显示就可以了。
}2.reserve在g++和vs上的扩容机制
1.
在vs上扩容机制采用1.5倍的大小,g++上采用2倍的大小,对于空间的扩容,如果开大了会造成空间浪费,开小了不够用,又会导致频繁扩容带来性能的损耗,而2倍的大小可以说是刚刚好,至于微软的工程师为什么选择1.5来进行扩容,是由于内存的某种对其因素导致。

void test_vector_expand()//扩容机制大概是1.5倍进行扩容
{
size_t sz;
vector<int> v;
//v.reserve(100);//已知开辟空间大小时,我们应该调用reserve来提前预留空间,进行扩容。
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}3.reserve异地扩容和shrink_to_fit异地缩容的设计理念
1.
对于reserve的设计理念就是不去缩容,就算手动调用reserve进行缩容,编译器也不会理你,空间的大小始终都不会变,capacity的值一直是不动的,这样的设计理念本质上就是用空间来换时间,因为异地缩容需要开空间和拷贝数据,比较浪费时间。
2.
相反shrink_to_fit就是缩容函数,强制性的将capacity的大小降低到适配size大小的值,它的设计理念就是以空间来换时间,但日常人们所使用的手机或者PC空间实际上是足够的,不够的是时间,所以这种函数还是不要使用的为好,除非说你后面肯定不会插入数据了,不再进行任何modify操作,那你可以试着将空间还给操作系统,减少空间的使用率。
void test_vector7()
{
vector<int> v;
v.reserve(10);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
cout << v.size() << endl;
cout << v.capacity() << endl;
//C++不会太推荐使用malloc来进行空间的初始化了,因为很有可能存在自定义类型对象没有初始化的问题,如果用new会自动调用构造。
//设计理念就是不去缩容,因为异地缩容的代价很大,所以就算你用reserve或是resize调整大小以改变capacity,但编译器不会管你。
// 因为它的设计理念不允许它这么做,而遇到shrink_to_fit就没辙了,因为他是缩容函数!!!
//---不动空间,不去缩容,以空间换时间的设计理念,因为缩容虽然空间资源多了,但是时间就长了,为了提高时间,就用空间换。
//shrink_to_fit就是反面的函数,进行了缩容。
v.reserve(3);
cout << v.size() << endl;
cout << v.capacity() << endl;
//设计理念:以时间换空间,一般缩容都是异地缩容,代价不小,一般不要轻易使用。通常情况下,我们是不缺空间的,缺的是时间。
v.shrink_to_fit();//缩容函数,代价很大,通常的缩容的方式,就是找一块新的较小的空间,然后将原有数据拷贝进去
v.resize(3);
cout << v.size() << endl;
cout << v.capacity() << endl;
v.clear();//clear都是不动空间的
}
4.vector和malloc分别实现动态开辟的二维数组
1.
对于C语言实现的话,需要一个返回值和两个输出型参数来返回到后台接口里面,第一个参数代表二维数组的大小,这道题我们知道返回的二维数组的大小,但其他题是有可能不知道的,而leetcode的后台测试用例是统一设计的,为了兼容其他不知道返回数组大小的题目,这里统一使用了输出型参数来控制。第二个参数的原因也是如此。
2.
二维数组、二维数组里面的元素、需要返回二维数组里面的一维数组的元素个数,这些数组都需要malloc出来。
//后台实现的地方:int returnSize=0;int returnColumnSizes[];
//grenerate(num,&returnSize,&returnColumnSizes);//函数调用
int** generate(int numRows, int* returnSize, int** returnColumnSizes)
{
int** p = (int**)malloc(numRows * sizeof(int*));
*returnSize = numRows;
*returnColumnSizes = (int*)malloc(sizeof(int) * numRows);
for (int i = 0; i < numRows; i++)
{
p[i] = (int*)malloc(sizeof(int) * (i + 1));//给每一个二维数组的元素动态开辟一个空间
(*returnColumnSizes)[i] = i + 1;
p[i][0] = p[i][i] = 1;
//for(int j = i; j < i + 1; j++)//条件控制有问题
//for (int j = 0; j < i + 1 ; j++)
for (int j = 1; j < i ; j++)
{
if (p[i][j]!=1)
{
p[i][j]=p[i-1][j-1]+p[i-1][j];
}
}
}
return p;
}3.
对于vector来讲的话,动态开辟就不需要我们自己做,通过resize就可以控制容器的空间大小,不用malloc动态开辟了,所以对于动态开辟的二维数组来讲,vector实际上要简便许多。
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows);
//第二个参数不传就是匿名对象,会自动调用容器中元素的构造函数。内置类型或自定义类型的构造。
for(size_t i=0; i<vv.size(); i++)
{
vv[i].resize(i+1, 0);//给每一个vector<int>容器预留好空间并进行初始化
vv[i][0] = vv[i][vv[i].size() - 1] = 1;
}
for(int i=0; i<vv.size(); i++)
{
for(int j=0; j<vv[i].size(); j++)
{
if(vv[i][j]==0)
{
vv[i][j]=vv[i-1][j]+vv[i-1][j-1];
}
}
}
return vv;
}
};三、vector的元素访问操作
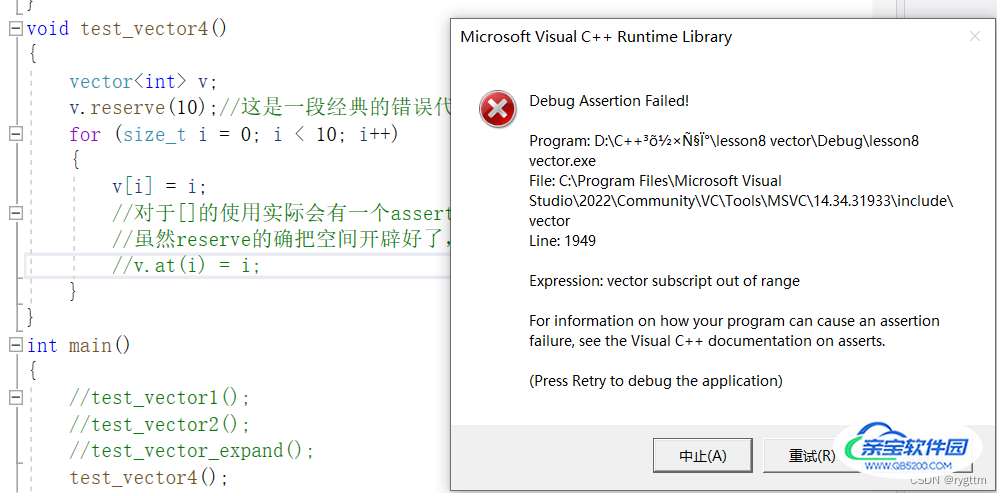
1.operator[]和at对于越界访问的检查机制(一段经典的代码错误)
1.
下面所展示的代码是比较经典的错误,就是我们用reserve扩容之后,就利用[]和下标来进行容器元素的访问,扩容之后空间的使用权确实属于我们,但是operator[]的越界访问检查机制,导致了我们程序的崩溃,assert(pos<size),所以对于元素的访问,是要用resize来进行size的调整的,而reserve的主要作用是用来提前预留空间,在空间不够使用的情况下进行调用,所以这里使用的情景有些不搭。
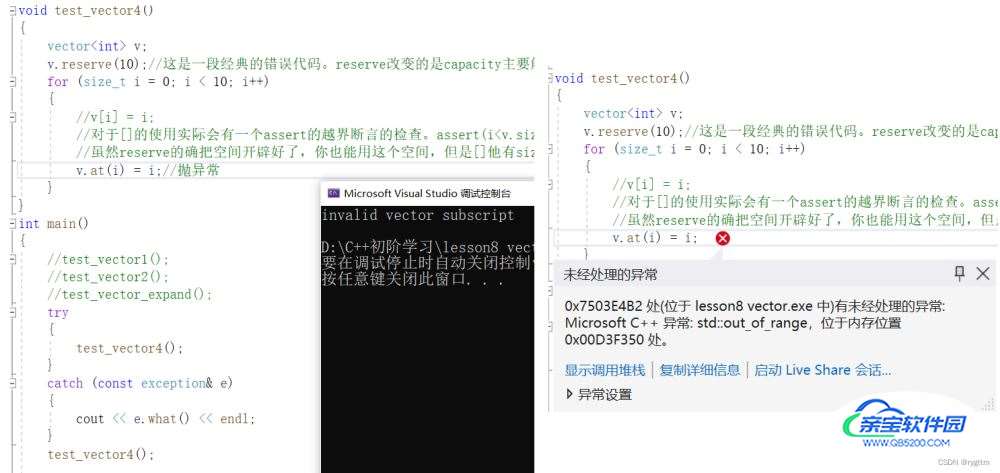
2.
对于at的使用,所采用的越界访问检查机制是抛异常,catch捕获异常之后,我们可以将异常信息打印出来,可以看到异常信息是无效的vector下标,指的也是所传下标是无用的,实际就是下标位置超过了size。
void test_vector4()
{
vector<int> v;
v.reserve(10);
//这是一段经典的错误代码。reserve改变的是capacity主要解决的是插入数据时涉及到的扩容问题。
//resize改变的是size,平常对于vector的容量增加,还是resize多一点,resize可以直接包揽reserve的活,并且除此之外还能初始化空间。
for (size_t i = 0; i < 10; i++)
{
//v[i] = i;
//对于[]的使用实际会有一个assert的越界断言的检查。assert(i<v.size()),你的下标不能超过size。
//虽然reserve的确把空间开辟好了,你也能用这个空间,但是[]他有size和下标的越界检查,所以你的程序就会报错。
//reserve=开空间+初始化(有默认值)
v.at(i) = i;//抛异常
//断言报错真正的问题是在于,release版本下面,断言就失效了,断言在release版本下面是不起作用的。
}
}
int main()
{
//test_vector1();
//test_vector2();
//test_vector_expand();
try
{
//test_vector6();
}
catch (const exception& e)
{//在这个地方捕获异常然后进行打印
cout << e.what() << endl;//报错valid vector subscript,无效的vector下标
}
//test_vector4();
//test_vector5();
//test_vector6();
test_vector7();
//string算是STL的启蒙,string的源码我们就不看了
return 0;
}
四、vector的修改操作
1.assign和迭代器的配合使用
1.
assign有两种使用方式,一种是用n个value来进行容器元素的覆盖,一种是用迭代器区间的元素来进行容器元素的覆盖,这里的迭代器采用模板形式,因为迭代器类型不仅仅可能是vector类型,也有可能是其他容器类型,所以这里采用模板泛型的方式。

2.
而且迭代器使用起来实际是非常方便的,由于vector的底层是连续的顺序表,所以我们可以通过指针±整数的方式来控制迭代器赋值的区间,所以采用迭代器作为参数是非常灵活的。
void test_vector5()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
//void assign(size_type n, const value_type & val);前后类型分别为size_t和模板参数T的类型typedef,那就是int类型
v.assign(10, 1);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
vector<int> v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
//template <class InputIterator> void assign(InputIterator first, InputIterator last);
v.assign(v1.begin(), v1.end());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
string str("hello world");
v.assign(str.begin(), str.end());//assign里面的迭代器类型是不确定的,既有可能是他自己的iterator也有可能是其他容器的迭代器类型。
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.assign(++str.begin(), --str.end());//你可以控制迭代器的区间,指定assign的容器元素内容的长度。
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}2.insert和find的配合使用
1.
对于顺序表这种结构来说,头插和头删的效率是非常低的,所以vector只提供了push_back和pop_back,而难免遇到头插和头删的情况时,可以偶尔使用insert和erase来进行头插和头删,并且insert和erase的参数都使用了迭代器类型作为参数,因为迭代器更具有普适性。
2.
如果要在vector的某个位置进行插入时,肯定是需要使用find接口的,但其实vector的默认成员函数并没有find接口,这是为什么呢?因为大多数的容器都会用到查找接口,也就是find,所以C++直接将这个接口放到算法库里面去了,实现一个函数模板,这个函数的实现实际也比较简单,只要遍历一遍迭代器然后返回对应位置的迭代器即可,所以这个函数不单独作为某个类的成员函数,而是直接放到了算法库里面去。

void test_vector6()//测试insert和find
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.insert(v.begin(), 4);
v.insert(v.begin() + 2, 4);
//vector的迭代器能够直接+2,源自于vector的底层是连续的空间,迭代器也就是连续的,而list的底层不是连续空间,而是一个个的节点,
//所以迭代器就不能++来进行使用了
//如果要在vector里面的数字3位置插入一个元素的话:std::find,find的实现就是遍历一遍迭代器,找到了就返回对应位置的迭代器。
//而vector、list、deque等容器都会用到find,所以find直接实现一个模板即可。
vector<int>::iterator it = std::find(v.begin(), v.end(), 3);
//string没有实现find的原因是string不仅仅要找某一个字符,而且还要找一个字串,所以算法库的find就不怎么适用,string就自己造轮子
v.insert(it, 30);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}3.类外、类内、算法库的3个swap
1.
vector类内的swap用于两个对象的交换,在swap实现里面再调用std的swap进行内置类型的交换,但C++用心良苦,如果你不小心使用的格式是std里面的swap格式的话,也没有关系,因为类外面有一个匹配vector的swap,所以会优先调用类外的swap,C++极力不想让你调用算法库的swap,就是因为如果交换的类型是自定义类型的情况下,算法库的swap会进行三次深拷贝,代价极大,所以为了极力防止你调用算法库的swap,C++不仅在类内定义了swap,在类外也定义了已经实例化好的swap,调用时会优先调用最匹配的swap。
void test_vector8()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
vector<int> v1;
v1.swap(v);
swap(v1, v);//一不小心这样用呢?那也不会去调用算法库里面的三次深拷贝的swap
//这里会优先匹配vector的类外成员函数,既然有vector作为类型实例化出来的swap函数模板,就没有必要调用算法库里面的模板进行实例化
//template <class T, class Alloc>
//void swap(vector<T, Alloc>&x, vector<T, Alloc>&y);
}五、看源码时需要注意的问题
1.
看源码框架的方法:将类成员变量先抽出来,看一看成员函数的声明具体都实现了什么功能,如果想要看实现,那就去.c文件抽出来具体函数去看
2.
看某些书籍时的道理和看源码是一样的,要进行抽丝剥茧,不要想着第一遍就把看到的所有东西都弄回,如果你觉得这本书或源码非常不错,你可以多次反复的去看,要循序渐进的去学,一段时间之后,你的知识储备上来之后,可能再去看书籍或者源码又有新的不同的感受,所以不要想着一遍就把所有的东西都搞明白,第一遍弄懂个70%-80%就很不错,如果你想学扎实一点,那就增加遍数。
加载全部内容