PySpark中RDD的数据输出问题详解
阳862 人气:0
RDD概念
RDD(resilient distributed dataset ,弹性分布式数据集),是 Spark 中最基础的抽象。它表示了一个可以并行操作的、不可变得、被分区了的元素集合。用户不需要关心底层复杂的抽象处理,直接使用方便的算子处理和计算就可以了。
RDD的特点
1) . 分布式 RDD是一个抽象的概念,RDD在spark driver中,通过RDD来引用数据,数据真正存储在节点机的partition上。
2). 只读 在Spark中RDD一旦生成了,就不能修改。 那么为什么要设置为只读,设置为只读的话,因为不存在修改,并发的吞吐量就上来了。
3). 血缘关系 我们需要对RDD进行一系列的操作,因为RDD是只读的,我们只能不断的生产新的RDD,这样,新的RDD与原来的RDD就会存在一些血缘关系。
Spark会记录这些血缘关系,在后期的容错上会有很大的益处。
4). 缓存 当一个 RDD 需要被重复使用时,或者当任务失败重新计算的时候,这时如果将 RDD 缓存起来,就可以避免重新计算,保证程序运行的性能。
一. 回顾
数据输入:
- sc.parallelize
- sc.textFile
数据计算:
- rdd.map
- rdd.flatMap
- rdd.reduceByKey
- .…
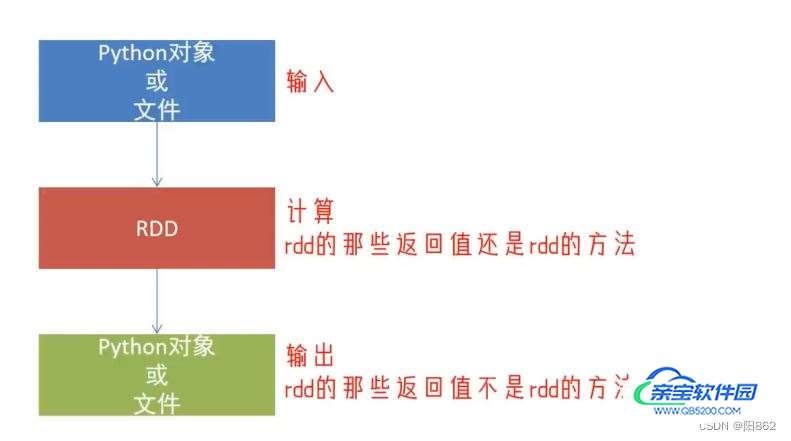
二.输出为python对象
数据输出可用的方法是很多的,这里简单介绍常会用到的4个
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
collect算子
功能:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
用法:
rdd.collect()
返回值是一个list
演示
from pyspark import SparkContext,SparkConf
import os
os.environ["PYSPARK_PYTHON"]="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#collect算子,输出RDD为list对象
print("rdd是:",rdd)
print("rdd.collect是:",rdd.collect())结果是
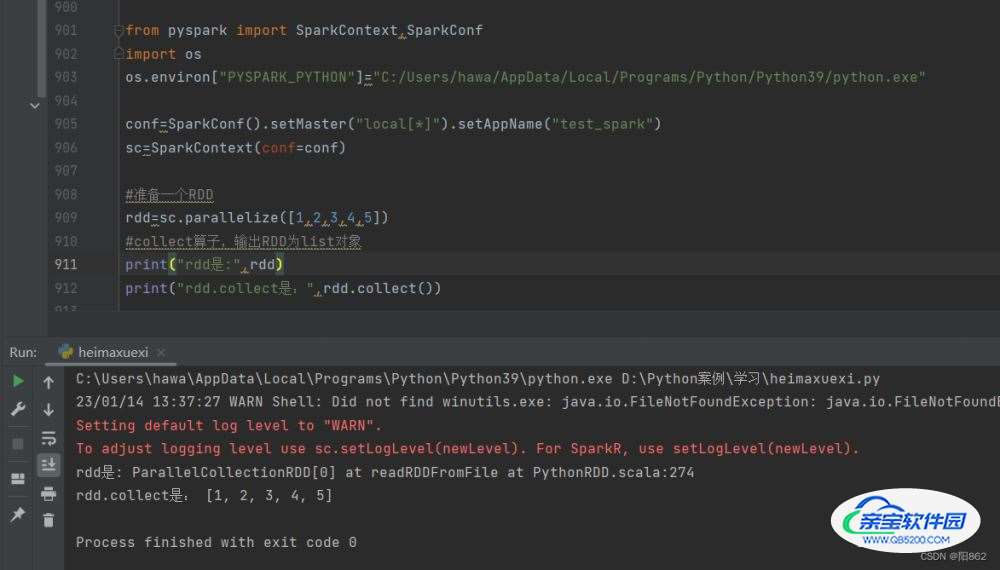
单独输出rdd,输出的是rdd的类名而非内容
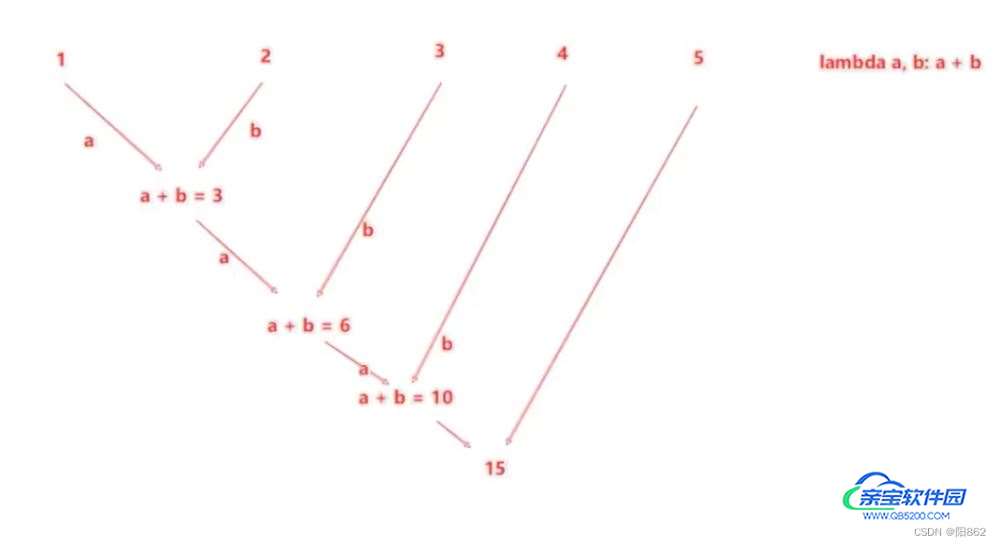
reduce算子
功能:对RDD数据集按照你传入的逻辑进行聚合
语法:

代码

返回值等于计算函数的返回值
演示
from pyspark import SparkContext,SparkConf
import os
os.environ["PYSPARK_PYTHON"]="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
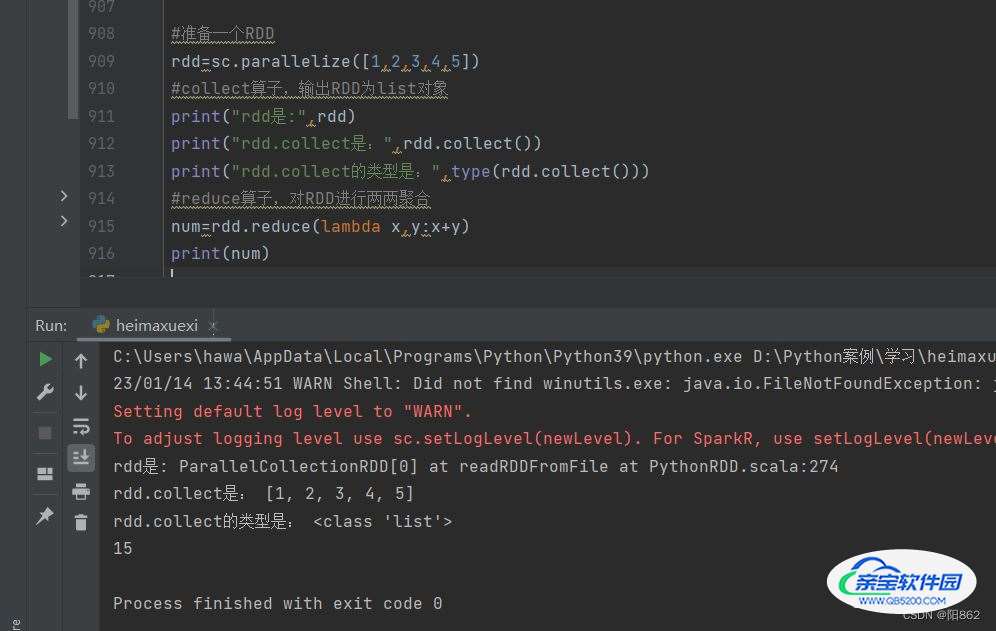
#准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#collect算子,输出RDD为list对象
print("rdd是:",rdd)
print("rdd.collect是:",rdd.collect())
print("rdd.collect的类型是:",type(rdd.collect()))
#reduce算子,对RDD进行两两聚合
num=rdd.reduce(lambda x,y:x+y)
print(num)结果是
take算子
功能:取RDD的前N个元素,组合成list返回给你
用法:

演示
from pyspark import SparkContext,SparkConf
import os
os.environ["PYSPARK_PYTHON"]="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#collect算子,输出RDD为list对象
print("rdd是:",rdd)
print("rdd.collect是:",rdd.collect())
print("rdd.collect的类型是:",type(rdd.collect()))
#reduce算子,对RDD进行两两聚合
num=rdd.reduce(lambda x,y:x+y)
print(num)
#take算子,取出RDD前n个元素,组成list返回
take_list=rdd.take(3)
print(take_list)结果是
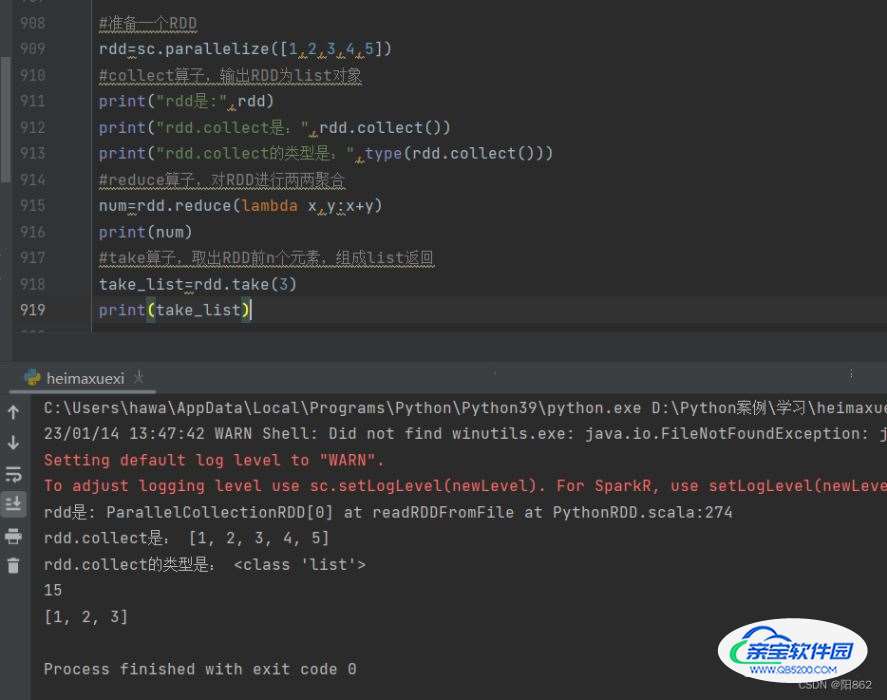
count算子
功能:计算RDD有多少条数据,返回值是一个数字
用法:

演示
from pyspark import SparkContext,SparkConf
import os
os.environ["PYSPARK_PYTHON"]="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备一个RDD
rdd=sc.parallelize([1,2,3,4,5])
#collect算子,输出RDD为list对象
print("rdd是:",rdd)
print("rdd.collect是:",rdd.collect())
print("rdd.collect的类型是:",type(rdd.collect()))
#reduce算子,对RDD进行两两聚合
num=rdd.reduce(lambda x,y:x+y)
print(num)
#take算子,取出RDD前n个元素,组成list返回
take_list=rdd.take(3)
print(take_list)
#count算子,统计rdd中有多少条数据,返回值为数字
num_count=rdd.count()
print(num_count)
#关闭链接
sc.stop()结果是
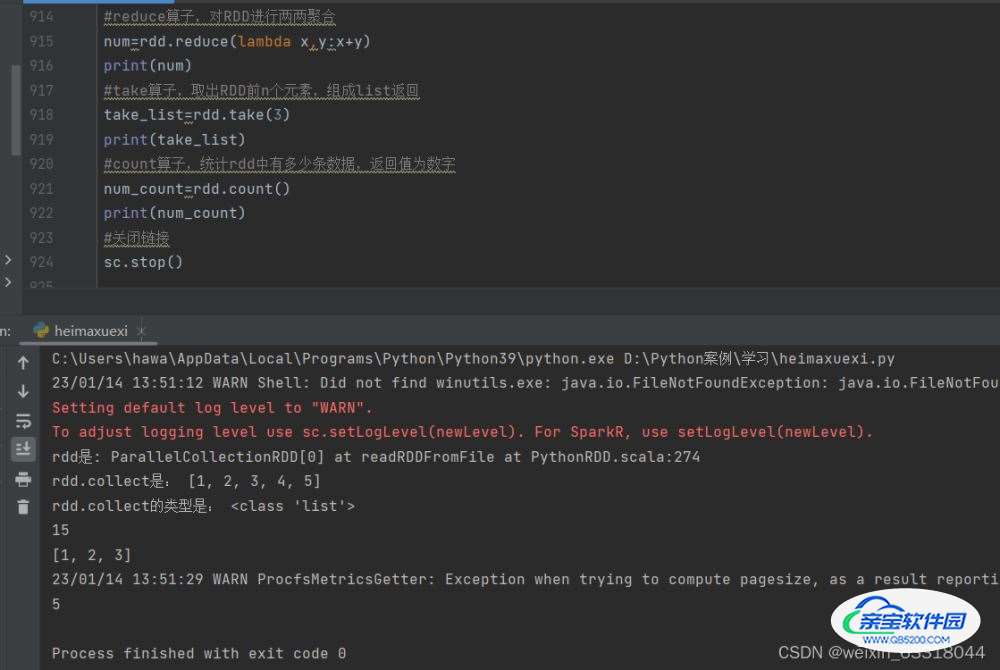
小结
1.Spark的编程流程就是:
- 将数据加载为RDD(数据输入)对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
2.数据输出的方法
- collect:将RDD内容转换为list
- reduce:对RDD内容进行自定义聚合
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数
数据输出可用的方法是很多的,这里只是简单介绍4个
三.输出到文件中
savaAsTextFile算子
功能:将RDD的数据写入文本文件中支持本地写出, hdfs等文件系统.
代码:

演示

这是因为这个方法本质上依赖大数据的Hadoop框架,需要配置Hadoop 依赖.
配置Hadoop依赖
调用保存文件的算子,需要配置Hadoop依赖。
- 下载Hadoop安装包解压到电脑任意位置
- 在Python代码中使用os模块配置: os.environ['HADOOP_HOME']='HADOOP解压文件夹路径′。
- 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- 下载hadoop.dll,并放入:C:/Windows/System32文件夹内
配置完成之后,执行下面的代码
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
os.environ['HADOOP_HOME']='D:/heima_hadoop/hadoop-3.0.0'
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=conf)
#准备rdd
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize([("asdf",3),("w3er_!2",5),("hello",3)])
rdd3=sc.parallelize([[1,2,3],[3,2,4],[4,3,5]])
#输出到文件中
rdd1.saveAsTextFile("D:/output1")
rdd2.saveAsTextFile("D:/output2")
rdd3.saveAsTextFile("D:/output3")结果是
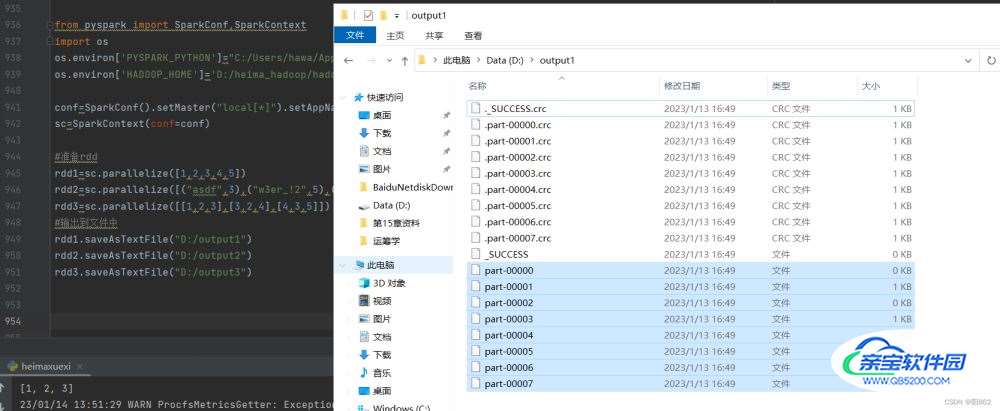
输出的文件夹中有这么8文件,是因为RDD被默认为分成8个分区
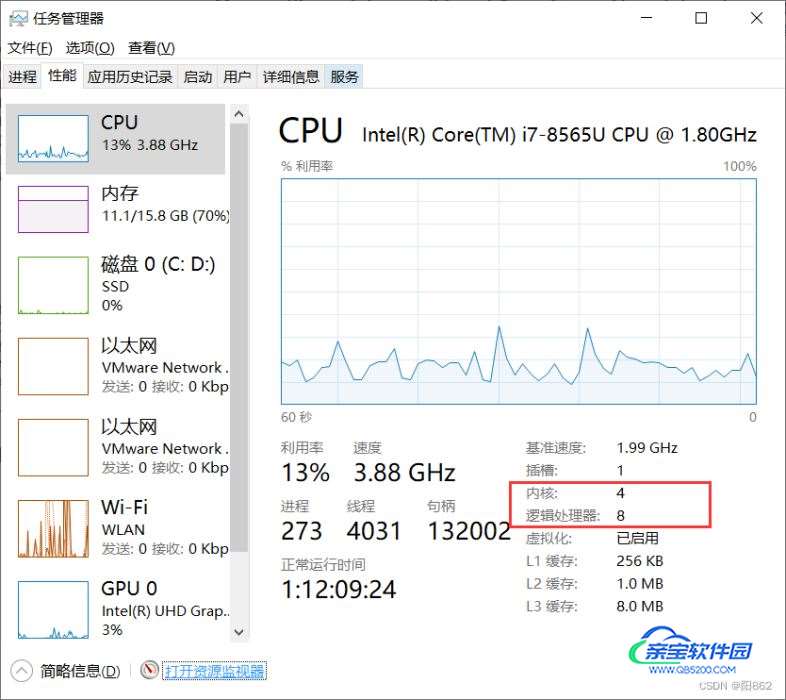
SaveAsTextFile算子输出文件的个数是根据RDD的分区来决定的,有多少分区就会输出多少个文件,RDD在本电脑中默认是8(该电脑CPU核心数是8核)
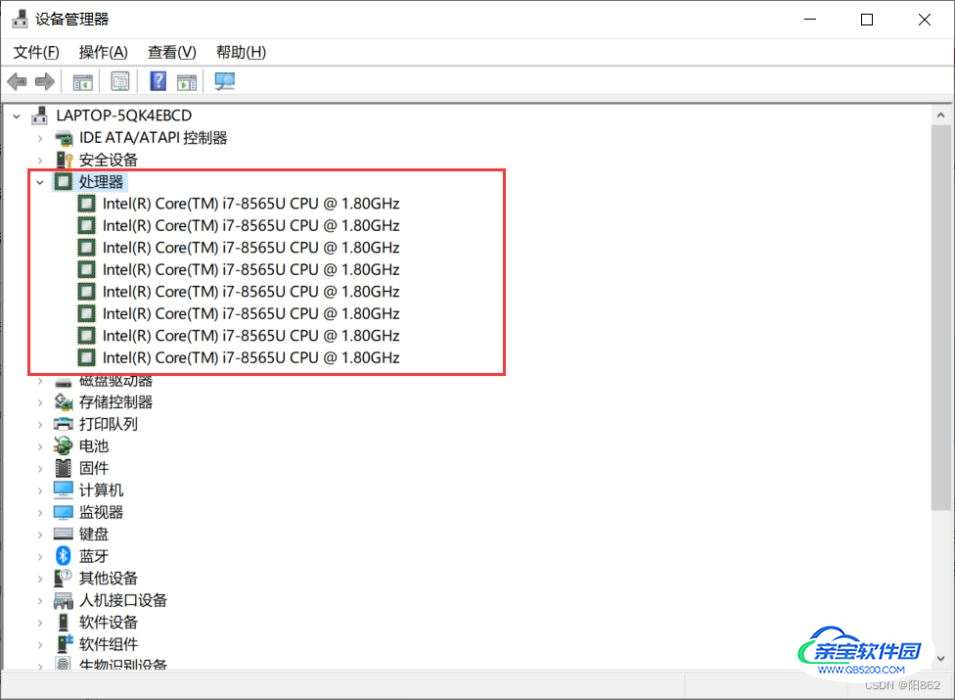
打开设备管理器就可以查看处理器个数,这里是有8个逻辑CPU
或者打开任务管理器就可以看到是4核8个逻辑CPU
修改rdd分区为1个
方式1, SparkConf对象设置属性全局并行度为1:

方式2,创建RDD的时候设置( parallelize方法传入numSlices参数为1)

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
os.environ['HADOOP_HOME']='D:/heima_hadoop/hadoop-3.0.0'
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#rdd分区设置为1
conf.set("spark.default.parallelism","1")
sc=SparkContext(conf=conf)
#准备rdd
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize([("asdf",3),("w3er_!2",5),("hello",3)])
rdd3=sc.parallelize([[1,2,3],[3,2,4],[4,3,5]])
#输出到文件中
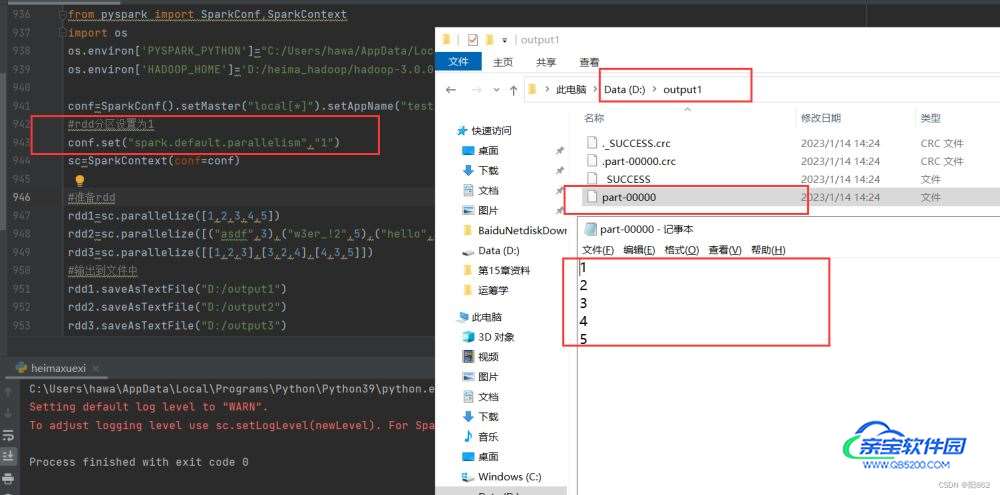
rdd1.saveAsTextFile("D:/output1")
rdd2.saveAsTextFile("D:/output2")
rdd3.saveAsTextFile("D:/output3")结果是
小结
1.RDD输出到文件的方法
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
2.如何修改RDD分区
- SparkConf对象设置conf.set("spark.default.parallelism", "7")
- 创建RDD的时候,sc.parallelize方法传入numSlices参数为1
四.练习案例

需求:
读取文件转换成RDD,并完成:
- 打印输出:热门搜索时间段(小时精度)Top3
- 打印输出:热门搜索词Top3
- 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
- 将数据转换为JSON格式,写出为文件
代码
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']="C:/Users/hawa/AppData/Local/Programs/Python/Python39/python.exe"
os.environ['HADOOP_HOME']='D:/heima_hadoop/hadoop-3.0.0'
conf=SparkConf().setMaster("local[*]").setAppName("test_spark")
#rdd分区设置为1
conf.set("spark.default.parallelism","1")
sc=SparkContext(conf=conf)
rdd=sc.textFile("D:/search_log.txt")
#需求1 打印输出:热门搜索时间段(小时精度)Top3
# 取出全部的时间并转换为小时
# 转换为(小时,1)的二元元组
# Key分组聚合Value
# 排序(降序)
# 取前3
result1=rdd.map(lambda x:x.split("\t")).\
map(lambda x:x[0][:2]).\
map(lambda x:(x,1)).\
reduceByKey(lambda x,y:x+y).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(3)#上面用的‘/'是换行的意思,当一行代码太长时就可以这样用
print(result1)
#需求2 打印输出:热门搜索词Top3
# 取出全部的搜索词
# (词,1)二元元组
# 分组聚合
# 排序
# Top3
result2=rdd.map(lambda x:x.split("\t")).\
map(lambda x:x[2])\
.map(lambda x:(x,1)).\
reduceByKey(lambda x,y:x+y).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(3)
print(result2)
#需求3 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
result3=rdd.map(lambda x:x.split("\t")).\
filter((lambda x:x[2]=="黑马程序员")).\
map(lambda x:(x[0][:2],1)).\
reduceByKey(lambda x,y:x+y).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
take(3)
print(result3)
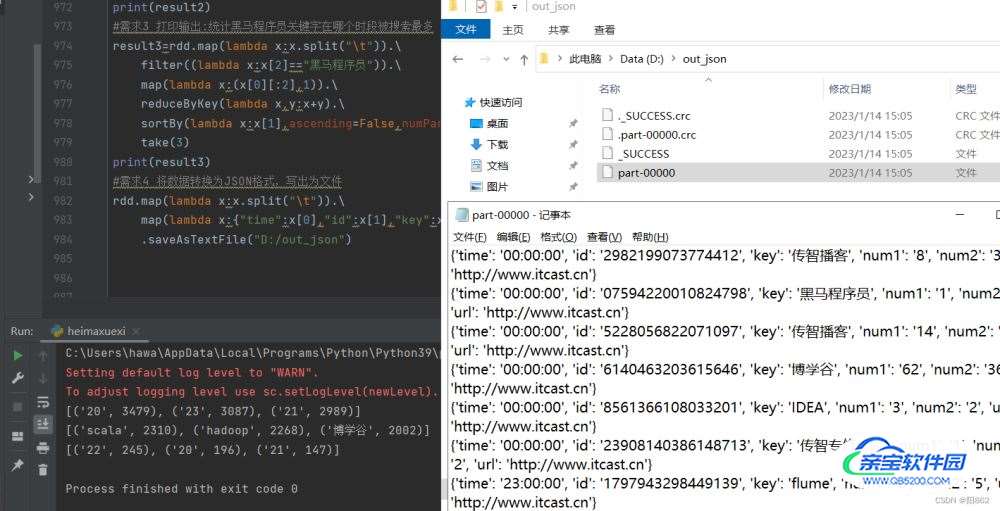
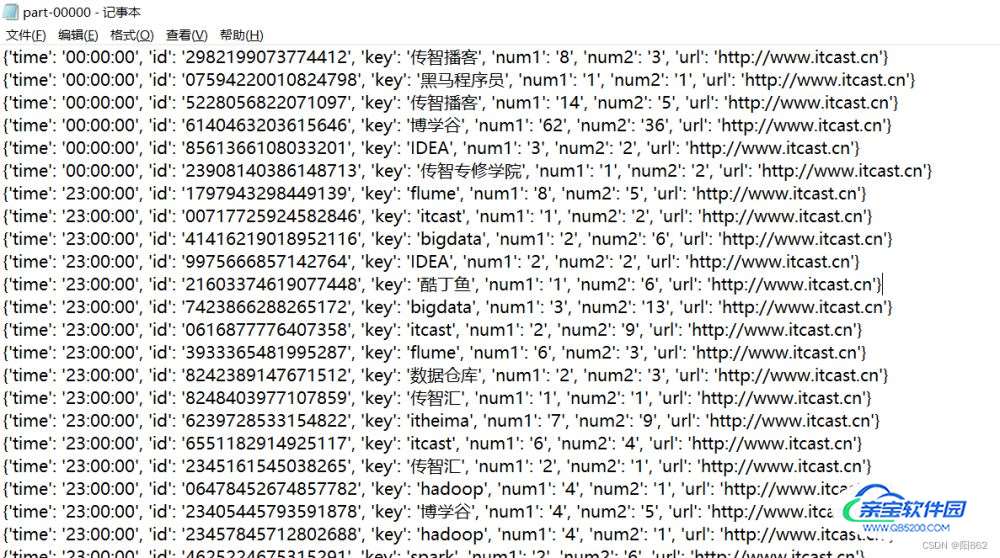
#需求4 将数据转换为JSON格式,写出为文件
rdd.map(lambda x:x.split("\t")).\
map(lambda x:{"time":x[0],"id":x[1],"key":x[2],"num1":x[3],"num2":x[4],"url":x[5]})\
.saveAsTextFile("D:/out_json")
结果是
加载全部内容