Mybatis实现动态SQL编写的示例详解
微凉秋意 人气:0前言
上篇博文把表连接查询和三种对应关系的写法记录总结了,本篇要把 mybatis 中的动态sql 的使用以及缓存知识记录下来。
动态SQL
在解释 where if 标签之前先进行一个模糊查询的操作。
模糊查询
如下面一张表:
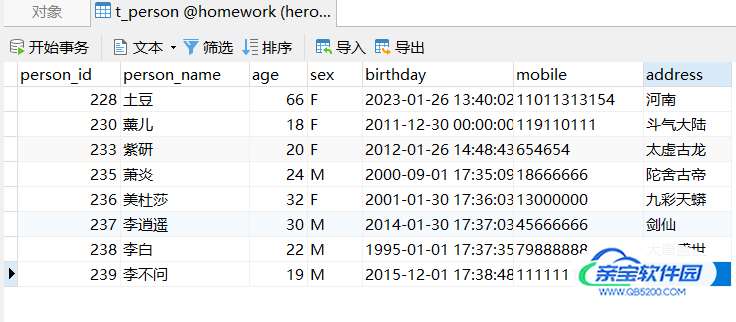
查询所有 李 姓人员的信息:
在mapper接口中定义方法:
List<Person> selectName(String name);
在 xml 中编写 sql 语句:
<select id="selectName" resultMap="personMap">
select *
from t_person
where person_name like concat('%', #{name}, '%');
</select>
这里的 concat('%', #{name}, '%') 写法使用了字符串拼接的技巧,这样在查询语句里就是 %name% 的模糊查询了。
如果这样写:'%#{name}%' 是不行的,#{}会失效。
编写测试类:
测试结果:
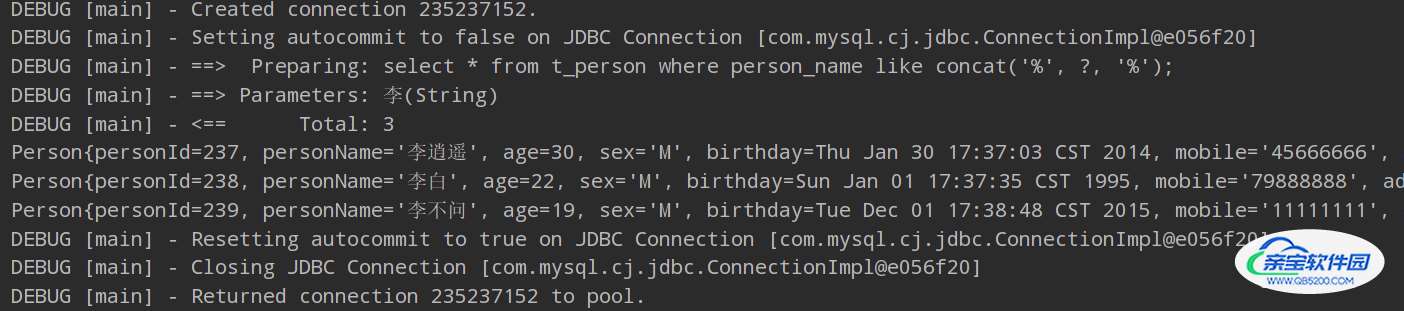
可以看到所有 李 姓的人信息被查询到了。
where if 标签
姓李的太多,那么我们可以加一个年龄范围,于是需要增加两个参数:

这里要注意,参数在两个以上需要使用 注解 来绑定。
重点来看 xml中的 sql 语句:
<select id="selectContent" resultMap="personMap">
select * from t_person
<where>
<if test="name != null and name !=''">
person_name like concat('%',#{name},'%')
</if>
<if test="ageMin > 0">
and age >= #{ageMin}
</if>
<if test="ageMax > ageMin">
and age <= #{ageMax}
</if>
</where>
</select>
可以看到这里的 where 关键字变成了一个标签 <where>,这是因为:
如果这三个参数都不填写的话,where 下的条件就不会起作用,
此条 sql 就变成了查询所有。
显然,查询所有的语法里是没有 where 关键字的,因此使用标签代替。
除了使用 <where> 标签之外,也可以使用类似 1=1 加 and 的方法拼接。
比如: select * from t_person where 1=1 and ...
此外,where 标签还可以去除多余的 and 前缀。
if 标签用来做判断,test 里写判断的条件,标签内写判断成功后的 sql 语句:
这里就是判断名字是否为空以及年龄的取值范围是否合理:
- test 里面的符号正常写,and 和 or 代表并且和或者。
- sql 语句里,> 是大于的意思,< 是小于的意思。
编写测试类:
测试结果:

很明显,年龄在 20~28 且姓李的只有 “李白” 自己。
update set 标签
以往的修改操作都是将对象的所有属性都修改或者重写一遍,这样是不合逻辑的,因此可以在修改的 sql 语句里使用 if 标签来优化。
在 mapper 接口中写方法:
void update(Person person);
在 xml 中编写 sql:
<update id="update">
update t_person
<set>
<if test="personName !=null and personName !=''">
person_name = #{personName},
</if>
<if test="age !=null">
age = #{age},
</if>
<if test="birthday != null and birthday!= ''">
birthday = #{birthday},
</if>
<if test=" sex !=null and sex !=''">
sex = #{sex},
</if>
<if test="mobile != null and mobile !=''">
mobile = #{mobile},
</if>
<if test="address !=null and address!=''">
address = #{address}
</if>
</set>
where person_id = #{personId}
</update>if 标签想必好理解,但是set 标签是做什么的呢?原因是:
假如只修改名字,那么 sql 语句将变为:
update t_person set person_name = ?, where ...
可以发现?占位符后面会有多余的逗号导致 sql 语法错误
<set> 标签会自动去除多余的逗号后缀。
值得注意的是:set 标签去除,后缀,where 标签去除and前缀。
foreach 标签
相信大家都知道foreach 跟循环有关系,没错,我们可以利用此标签来完成 批量删除 操作。
从 sql 的语句来看,批量删除应该这样写:
delete from t_person where person_id in (?,?,?,...)
那么 in 后的形式该怎么用 mybatis 表达出来呢,有括号,不定数量的逗号…
不急,一步步来,先写 mapper接口:
void deleteMany(@Param("myIds") int[] ids);
再编写 sql 语句:
<delete id="deleteMany">
delete from t_person where person_id in
<foreach collection="myIds" open="(" close=")" separator="," item="id">
#{id}
</foreach>
</delete>
利用 foreach 就可以将参数集合中的值依次放入到 in 后的括号内:(id,id,id...)
foreach 标签相关解释:
- collection:被循环的数组或者集合,注意如果是参数必须使用@Param 起名
- open : 循环以什么开始
- close :循环以什么结束
- separator: 循环以什么分割
- item : 每次循环的元素
编写测试类(不要忘记手动提交事务):
测试结果:

可以看到数组里的元素依次放入了括号内,并成功做到了批量删除。
useGeneratedKeys 获取插入数据的主键值
一般我们习惯将表中的主键设为自增长,那么在使用 insert 插入数据时,主键是不用赋值的,而是用 null 代替。那怎么才能在插入后直接得到该数据的主键值呢?那就使用 useGeneratedKeys。
来看具体的使用:
<insert id="insert" useGeneratedKeys="true" keyProperty="personId" keyColumn="person_id">
insert into t_person
values (null, #{personName}, #{age}, #{sex}, #{birthday}, #{mobile}, #{address})
</insert>
将值设为 true 后,keyPropetry 的值填写属性名,keyColumn 的值填写表的字段名。
编写测试类:
@Test
public void insert(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
PersonMapper mapper = sqlSession.getMapper(PersonMapper.class);
Person person = new Person(null,"微凉",21,"1",new Date(),"1359356123","爱琴海");
mapper.insert(person);
sqlSession.commit();
MybatisUtil.closeSqlSession(sqlSession);
System.out.println(person);
}
测试结果:

可以看到插入数据后的主键值为 240,这便是自动获取的结果。
Mybatis 缓存
有关 IO 操作一般都会很耗时,在一个 javaweb 项目中,页面到 tomcat 与 tomcat 到数据库都属于IO操作。因此 mybatis 在 tomcat 中创建了一块叫做缓存的空间,在缓存中保存比如查询操作的数据,以后进行重复操作时,就不必到数据库中获取了,而是直接在 tomcat 内部获取。
如果对数据库进行修改,缓存中的数据跟数据库中的对应不上,那么此时缓存中的就变成了脏数据。
一级缓存
特点:
- 默认开启
- 作用在同一个 SqlSession 中
- 脏数据的处理: 一旦执行增删改,立刻清空缓存
但是一级缓存并没有什么意义,因为作用范围的缘故,它只能在一个 SqlSession ,也就是一个事务内,一旦提交事务,缓存就会被清空,没有实战意义。
二级缓存
二级缓存的作用范围大,符合实战的需求,该如何开启:
1.实体类需要实现可序列化接口:implements Serializable
2.在 mybatis-config.xml 文件中添加<settings> 标签:
<!--开启二级缓存 settings 写在 properties 和 typeAliases 之间--> <settings> <setting name="cacheEnabled" value="true"/> </settings>
3.在对应 mapper 的 xml 文件中添加 <cache> 标签:
<cache size="1024" eviction="LRU" flushInterval="60000"/>
size:定义二级缓存空间大小 (单位是 M)
eviction:定义缓存到达上限时的淘汰策略,常使用LRU算法:
叫做最近最久未使用算法,即清空最近使用次数最少的缓存
flushInterval:定义清空缓存的间隔时间 (单位 ms)
作用范围:
同一个sqlSessionFactory内,而且必须提交事务。
脏数据的处理:
1.一旦执行增删改,默认清空同一个 namespace 下的二级缓存。
2.自定义清空缓存的策略:
- flushCache属性,值为 true 时执行清空缓存,为 false 则不清空。
- 在 insert、delete、update 标签里默认为 true
- 在 select 标签里默认为 false
脏数据并不都是一定要清空,因此在增删改查标签内可以自由的设定缓存清空的策略。
加载全部内容