C++中字符串全排列算法及next_permutation原理详解
谜一样的男人1 人气:0前言
next_permutation/prev_permutation是C++ STL中的一种实用算法;
功能是: 以迭代器的方式,将一个容器内容改变为他的下一个(或prev上一个)全排列组合;

next_permutation的使用
假设需要将字符串abcd的全排列依次打印,我们可以用next_permutation函数方便操作:
使用方法:
1.一般先sort成升序;(prev_permutation倒着全排列使用规则相反)
2.然后再do while配合调用全排列,循环输出,直到排列情况全部输出 返回false;
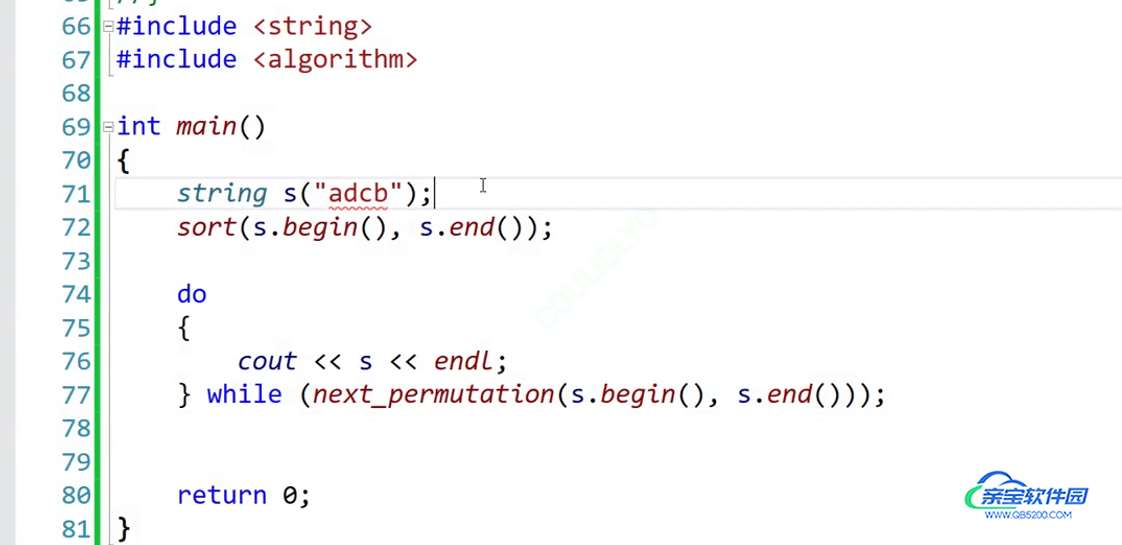
运行结果:
实现全排列的两种算法
当然仅仅只会用没有什么困哪的,如果面试官突然问你STL中这个全排列算法咋实现的呢?
1. 递归法(全排列方便理解记忆的方法,作为备用方法)
如果上面全排列,突然脑袋断片了,或者说考试中不让用封装好的库函数;
为了不至于连个全排列的思想都不会,可以用用相对好理解的递归法全排列:
算法思想:(递归问题:按规则处理一个过程,剩下的过程是相同的处理方式,那么就可以进行函数递归调用)
1.从集合中依次选出每一个元素,作为排列的第一个元素;
2.然后**对剩余的元素(第一个元素之后的)进行 同样操作 **;
如此递归处理,从而得到所有元素的全排列。
eg:
以对字符串abc进行全排列为例,我们可以这么做:以abc为例
- 固定a,递归求后面bc的排列:求好: abc,acb后,b交换到第一位置,得到bac,如下固定b递归b后面的排列:
- 固定b,求后面ac的排列:bac,bca,求好后,c交换到第一位置,得到cba,如下固定c递归c后面的排列:
- 固定c,求后面ba的排列:cba,cab;结束 一共a,b,c分别当第一个元素进行了全排列,算法结束;
(注意:1. 每次交换下一个位置的时候,需要swap换回来,保证原始序列,再交换下一个位置的字母去第一个位置。2. 需要考虑有重复相同且挨着的数字情况,此时需要剪枝)
递归比较抽象,可以用简单地例子abc在纸上模拟画一下好理解;
实现代码(无重复元素情况)
#include<iostream>
#include<vector>
using namespace std;
//dfs实现全排列(无重复元素情况)
void dfs(string &s, int l, int r)
{
if (l == r) {//递归终止,当前s可以输出了,已经是某一轮的完整排列,不能再排列了
cout<<s<<endl;
return;
}
for (int i = l; i < r; i++) {
swap(s[l],s[i]);
dfs(s,l+1,r);//递归
swap(s[l], s[i]);//进行下一轮的swap dfs,需要先swap换回来原来的位置!否则会出现重复排列!
}
}
int main()
{
string s = "abcd";
//sort(s.begin(),s.end())//sort一下,再配合dfs算法,可以实现按照字典序处理
int len = s.size();
dfs(s,0,len);
return 0;
}
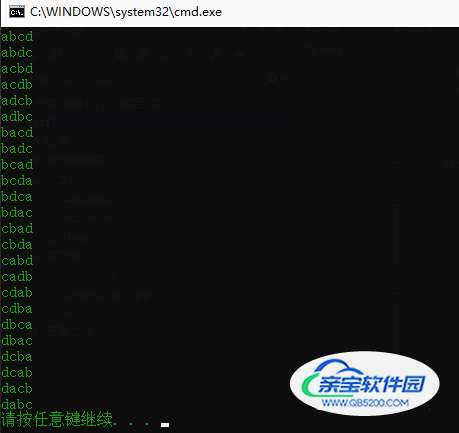
运行结果:
有重复元素情况

这种情况需要对代码做一个优化,不然的话按照上面的算法,会出现重复数字的重复排列情况;
优化很简单:
如果某个数字在之前的排列被换到首位置进行排列过,那本次交换就不进行;(其次,当dfs首次交换i==l的时候,即便出现过也需要进行);
整合一下就是if(i==l || s[i]没出现) -->进行交换)
代码:
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
//dfs实现全排列(含重复元素情况)
void dfs(string &s, int l, int r)
{
if (l == r) {
cout<<s<<endl;
return;
}
set<char>st;//检测重复的set
for (int i = l; i < r; i++) {
if (i == l || st.find(s[i])==st.end()) {//防止后续进行重复排列
st.insert(s[i]);//满足 记录这个字符
swap(s[l], s[i]);
dfs(s, l + 1, r);
swap(s[l], s[i]);
}
}
}
int main()
{
string s = "aba";
int len = s.size();
dfs(s,0,len);
return 0;
}
2. 迭代法(next_permutation底层原理)
比较抽象,难以理解,根据个人情况来理解;
一个全排列可看做一个字符串,字符串可有前缀、后缀。
规定: 生成给定全排列的下一个排列–> 所谓一个字符串的下一个排列,就是这个个字符串变化限制在尽可能短的后缀上,变化后的那个字符串; 这就要求这一个与下
一个有尽可能长的共同前缀;变化限制在尽可能短的后缀上
eg:
839647521是1—9的排列。1—9的排列最前面的是123456789,最后面的987654321;
从右向左扫描若都是增的,就到了987654321,也就没有下一个了。否则找出第一次出现下降的位置。
如何得到346987521的下一个?
首先对原生字符串排序,这个迭代算法是基于字典序排序好的字符串全排列;(所以之后从尾部,向前循环迭代,每次变化尽可能短的后缀,以此类推)
1.从尾部往前找第一个P(i-1) < P(i)的位置;: 346987521 种 最终找到6是第一个变小的数字,记录下6的位置i-1
2.从找到的 i 位置往后找到最后一个大于6的数:346987521 中最终找到7的位置,记录位置为m(m == r-1)
3.swap(r-1,i-1) : 3 4 7 9 8 6 5 2 1
4.倒序翻转i位置后的所有数据 : 3 4 7 1 2 5 6 8 9
5.进行do-while循环,直到第一步之后,判断出 i==0 break; 全部排列完毕
很抽象,但是思想就是 一个字符串的下一个全排列:有尽可能长的共同前缀;变化限制在尽可能短的后缀上
大概知道步骤: 那么用排好序的123456789试试上面的过程,你会发现,每次变化尽可能短的后缀,有点像递归的感觉,一步一步逼近字符串0,index,此时完美结束; 或者用123这个例子体验一下6个全排列是咋来的 amazing
上面的过程多悟几遍就理解了; 大概知道思想面试的时候说说也行=-=
实现代码(有无重复不影响)
#include<iostream>
#include<algorithm>
#include<set>
using namespace std;
//dfs实现全排列
int main()
{
string s = "abcd";
sort(s.begin(),s.end());//记得先排序
int len = s.size();
do
{
cout << s << endl;//打印某次排列
int i = s.size() - 1;
int j;
while (i > 0 && s[i] <= s[i - 1]) i--;//1.从后向前 找 第一个 s[i-1]<s[i]
if (i == 0) break;
j = i;
while (j<len && s[j]>s[i - 1]) j++;//2.从i向后 找 最后一个 s[m]>s[i-1] 用j找,所以最后m==j-1
swap(s[i - 1], s[j - 1]);//3. swap (i-1,m(j-1))
reverse(s.begin() + i, s.end()); //4. 翻转 i后面的子串
} while (1); //do while为了让第一个 abcd 也正常打印再全排列
return 0;
}
这个算法理解起来对于我来说有点夸张,呜呜呜;
加载全部内容