Redis内存碎片原理深入分析
JAVA旭阳 人气:0前言
我们先来看一个问题, 假设Redis实例保存了5GB的数据,现在删除了2GB的数据,那么Redis进程占用的内存会不会减少呢?
答案是:它可能仍然占用大约5GB内存,即使Redis数据只占用大约3GB。
如果maxmemory不设置该参数,Redis不会触发内存淘汰策略删除数据。
Redis会继续为新写入的数据分配内存。分配失败会导致应用程序报错,当然不会导致宕机。
注:设置maxmemory参数,执行命令CONFIG SET maxmemory 100mb,或在redis.conf 配置文件中设置maxmemory 100mb。
使用top命令查看数据是否已经删除,为什么它仍然占用这么多内存?
释放的内存去了哪里?
当我们使用top命令查看系统使用情况时,会发现内存依然很高,Redis并没有真正释放内存。那么内存都去哪儿了?这时候我们就需要使用info memory命令获取Redis内存相关的指标。
127.0.0.1:6379> info memory # Memory used_memory:1132832 // Redis Amount of memory used to store data used_memory_human:1.08M // Returns the total amount of memory in human readable form used_memory_rss:2977792 // From the perspective of the operating system, the total physical memory occupied by the process used_memory_rss_human:2.84M // used_memory_rss Readability mode display used_memory_peak:1183808 // The maximum value of memory used, representing the peak value of used_memory used_memory_peak_human:1.13M // Returns the value of used_memory_peak in a human readable format used_memory_lua:37888 // Lua The amount of memory consumed by the engine。 used_memory_lua_human:37.00K maxmemory:2147483648 // The maximum memory value that can be used, in bytes. maxmemory_human:2.00G // readable form maxmemory_policy:noeviction // Memory Retirement Policy mem_fragmentation_ratio:2.79 // The ratio of used_memory_rss & used_memory represents the memory fragmentation rate
Redis进程内存消耗主要由以下几部分组成:
- 内存被Redis自己启动占用
- 存储对象数据内存
- 缓冲区内存:主要由
client-output-buffer-limit客户端输出缓冲区、copy backlog缓冲区、AOF缓冲区组成 - 内存碎片
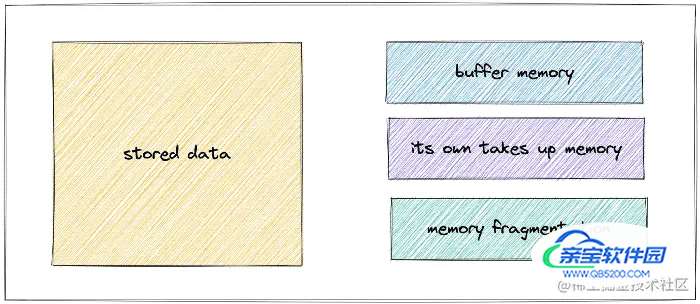
Redis自身的空进程占用的内存很小,可以忽略不计,而对象内存是最大的,里面存放了所有的数据。
需要注意, 如果缓冲区有大流量的场景很容易失控,导致Redis内存不稳定。
内存碎片过多导致有可用空间不足,无法存储数据。内存碎片Fragmentation = used_memory_rss 实际使用的物理内存(RSS 值)除以 used_memory 实际存储的数据内存。
什么是内存碎片?
内存碎片会导致内存空间空闲,但无法存储数据。比如你和女朋友去电影院看电影,你们肯定是要在一起的。
假设现在有 8 个座位,已售出 4 张票,还有 4 张可供购买。不过巧合的是,买票的人很奇怪,都是隔一个座位买票。即使还有4个座位,也不能买顺序连接两个座位的票。

什么导致内存碎片?
主要有两个原因:
- 内存分配器的分配策略
- 键值对的大小不同,删除操作
下面我们就实际发生的原因进行探讨。
1. 内存分配器的分配策略
Redis 默认的内存分配器使用jemalloc,可选的分配器有:glibc,tcmalloc。
内存分配器不能按需分配,而是使用固定范围的内存块进行分配。
比如8字节、16字节……、2KB、4KB,当申请内存最接近固定值时,jemalloc会分配最接近固定值的空间。这样就会出现内存碎片。
比如程序只需要1.5KB,而内存分配器会分配2KB的空间,那么这0.5KB就是碎片。这样做的目的是减少内存分配的次数。比如你申请22个字节的空间来存放数据,jemalloc就会分配32个字节。如果后面需要写入10个字节,则不需要向操作系统申请空间。您可以使用之前请求的 32 个字节。
当一个键被删除时,Redis 不会立即将内存归还给操作系统。发生这种情况是因为底层内存分配器的管理。例如,大多数已删除的键仍与其他有效键分配在同一内存页中。
此外,为了重用空闲内存块,分配器删除了原始 5 GB 数据中的 2 GB。再次向实例添加数据时,Redis的RSS会保持稳定,不会增加太多。因为内存分配器基本上重新使用了之前删除释放的2GB内存。
2.键值对大小不同,删除操作
由于内存分配器是按照固定的大小分配内存,因此分配的内存空间通常会大于实际数据占用的大小,这会造成碎片,降低内存的存储效率。
另外,键值对的频繁修改和删除导致内存空间的扩大和释放。例如,如果原来占用32个字节的字符串现在修改为占用20个字节的字符串,那么释放的12个字节就是空闲空间。
如果下一次数据存储请求需要申请一个13字节的字符串,刚刚释放的12字节空间就不能使用,造成碎片。
分片最大的问题:空间总量足够大,但是这些内存并不连续,可能存不下数据。
mem_fragmentation_ratio = used_memory_rss/ used_memory
如何解决?
首先要判断是否发生了内存碎片,重点看info memory命令执行后的mem_fragmentation_ratio指标,表示内存碎片率。
如果1 < mem_fragmentation_ratio < 1.5,可以认为是合理的,如果大于1.5,说明碎片已经超过了50%,我们需要采取一些措施来解决碎片过多的问题。
1. 重启
最简单的方法是重新启动。如果未启用持久性,数据将丢失。
如果开启持久化,需要使用RDB或者AOF来恢复数据。如果只有一个实例,数据量大会导致恢复阶段长时间无法提供服务,高可用性会大大降低。
2.自动清理内存碎片
Redis在4.0版本之后,提供了内存碎片清理机制。
对于Redis来说,当连续的内存空间被分割成若干个不连续的空间时,操作系统首先将数据移动拼接在一起,释放掉原来数据占用的空间,形成一个连续的空闲内存空间。
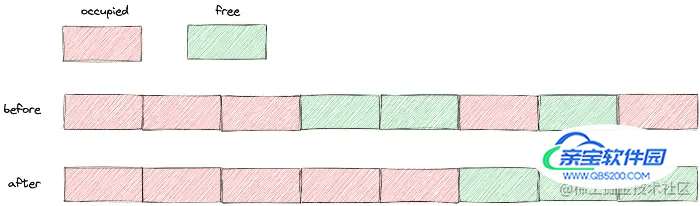
图片由作者提供
自动清理虽然好,但也不要乱来。操作系统需要消耗资源将数据移动到新的位置,然后释放原来的空间。
Redis 操作数据的指令是单线程的,所以在数据复制和移动时,只有清理碎片后才能处理请求,会造成性能损失。
那么问题来了,如何减少对性能的影响来实现自动清理碎片?
问得好,用下面两个参数来控制内存碎片清理和结束的时机,避免占用过多CPU,减少清理碎片对Redis处理请求的性能影响。
启用自动内存碎片整理:
CONFIG SET activedefrag yes
这只是为了启用自动清洁。当清理需要同时满足以下两个条件时,就会出发清理操作。
- 清理条件
active-defrag-ignore-bytes 200mb:内存碎片占用内存达到200MB,开始清理;
active-defrag-threshold-lower 20: 内存碎片空间超过系统分配给Redis空间的20%,开始清理。
- 避免性能影响
清理时间是有的,需要控制清理对性能的影响。一二设置先分配清理碎片占用的CPU资源,保证碎片可以正常清理,避免对Redis处理请求造成性能影响。
active-defrag-cycle-min 20:自动碎片整理过程中占用CPU时间比例不低于20%,以保证清理任务正常进行。
active-defrag-cycle-max 50:自动清理进程占用CPU时间比例不能高于50%。如果超过,会立即停止清理,避免阻塞 Redis 造成高延迟。
总结
如果发现Redis存储数据占用的内存比操作系统分配给Redis的内存小很多,但是数据无法保存,那么可能是内存碎片很多。使用info memory命令查看内存碎片mem_fragmentation_ratio指标是否正常。
然后我们启用自动清理并合理设置清理时间和CPU资源占用。该机制涉及内存复制,这对 Redis 性能构成潜在风险。如果Redis性能变慢,检查是否是清理碎片导致的。如果是这样,减小配置active-defrag-cycle-max的值。
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说