Python基于OpenCV的视频图像处理详解
心随而动 人气:0初识OpenCV
OpenCV是一个开源的,跨平台的计算机视觉库,它采用优化的C/C++代码编写,能够充分利用多核处理器的优势,提供了Python,Ruby,MATPLOAB以及其他高级语言接口。
OpenCV的设计目标是执行速度尽量快,主要面向实时应用,是视频信号处理的主要工具之一,它封装了丰富的视频处理相关的工具包。视频信号是重要的视觉信息来源,其中包含的信息要远大于图像,对视频的分析也是计算机视觉领域的重要研究方向之一。视频在本质上由连锁的多帧图像构成,因此,视频信号处理最终仍归属图像处理范畴。但在视频中,其时间维度也包含了许多有用的信息。
视频读写处理
视频一般有两种来源,一种是从本地磁盘加载,另一种是从摄像头等设备实时获取。上述两种视频获取方式分别对应着OpenCV2的两个函数CaptureFromFile()和CaptureFromCAM().在OpenCV3中则统一为一个用于处理视频源载入的函数VideoCapture()。
下示例代码展示了如何从本地载入一个视频文件,然后将其转化为灰度图像连续帧并播放:
import cv2
cap=cv2.VideoCapture('D:\Image\Funny.mp4')
while(cap.isOpened()):
ret,frame=cap.read() #循环播放视频中每帧图像
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #将原帧图像转化为灰度图像
cv2.imshow('视频捕捉',gray) #显示处理后的图像
if cv2.waitKey(1) & 0xFF==ord('q'): #按q键退出程序
break
cap.release() #处理完成,释放视频捕捉
cv2.destroyAllWindows() #关闭窗口释放资源
由于视频过长,原视频放在了主页。
下列代码则展示了如何从摄像头获取视频:
#摄像头获取视频
import cv2
cap=cv2.VideoCapture(1) #打开摄像头获取视频
while(True):
ret,frame=cap.read() #循环播放视频中每帧图像
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#显示结果
cv2.imshow('摄像头拍照',gray)
if cv2.waitKey(1) & 0xFF==ord('q'):
break
cap.release()#处理完成,释放视频捕捉
cv2.destroyAllWindows()下列代码展示了将摄像头获得的视频写入存储文件的过程。其中,VideoWriter_fourcc类用于定义视频文件的写入格式,其参数有多种格式可选,如下:
- ①.VideoWriter_fourcc('T','4','2','0'),该选项为一个未压缩的YUV颜色编码类型,是4:2:0色度子采样。改编码有着很好的兼容性,但是会产生较大的文件,文件拓展名为:“.avi”
- ②.VideoWriter_fourcc('P','T','M','1'):该选项为“MPEG-1”编码类型,文件拓展名为“.mpeg”
- ③.VideoWrite_fourcc('X','V','T','D'):该选项是“MPEG-4”编码类型,如果希望得到的视频大小为平均值,推荐使用该选项,文件拓展名为:“.mp4”
- ④.VideWriter_fourcc('T','H','E','O'):该选项是“Ogg Vorbis”编码类型,文件拓展名为“.ogv”。
- ⑤.VideWriter_foucc('F','L','V','T'):该选项是Flash编码类型,文件拓展名是“.flv”。
定义好输出视频的格式后,用VideWriter类进行写入的时候,需要指定帧速率和帧大小,因此需要从另一个视频文件复制视频帧,这些属性可以通过VideoCapture类的get()函数得到。
通过OpenCV获取视频并写入文件的示例代码:
#通过OpenCv获取视频并写入
import cv2
cap2=cv2.VideoCapture('D:\Image\Funny.mp4')
cap=cv2.VideoCapture(1)#打开摄像头并获取视频
#对视频帧率fps进行赋值
fps=24
#过去视频帧的大小
size=(int(cap2.get(cv2.CAP_PROP_FRAME_WIDTH)),int(cap2.get(cv2.CAP_PROP_FRAME_HEIGHT)))
fourcc=cv2.VideoWriter_fourcc('X','V','I','D') #MP4文件格式
out=cv2.VideoWriter('D:\Image\output.avi',fourcc,fps,size)#定义视频文件写入对象
while(cap.isOpened()):
ret,frame=cap.read()
if ret==True:
'''
获取帧图像并翻转,cv2.flip()的第二个参数表示翻转方式:0代表垂直翻转,1代表水平翻转,-1代表水平垂直翻转
'''
frame=cv2.flip(frame,1)
out.write(frame)#将翻转后的帧图像写入文件
cv2.imshow('帧图像处理',frame)
if cv2.waitKey(1) & 0xFF==ord('q'):
break
else:
break
cap.release()
out.release()
cv2.destroyAllWindows()运动轨迹标记
运动捕捉(Motion Capture)技术可对运动物体或其特征点在三维空间中的运动轨迹进行实时,精确,定量地连续测量,跟踪和记录。运动轨迹则是从物体开始位置运动结束位置所经过的路线组成的空间特征。基于计算机视觉图像处理技术的运动捕捉方案在动画及游戏制作,仿真训练等领域有着广泛的应用。
光流(Optical Flow)是图像亮度的运动信息描述,是空间运动物体在观测成像面上的像素运动的瞬时速度,也是对视频中运动对象轨迹进行标记的一种常用方法。光流由场景中前景目标本身的运动,摄像机的运动,或者两者的共同运动产生。当人通过眼睛观察运动物体时,物体的景象在人眼的视网膜上形成一系列连续变化的图像,这一系列连续变化的信息不断“流过”视网膜,犹如光在平面中的流动,故称之为“光流”。光流的概念在20世纪40年代首次被提出,该方法利用图像序列中的像素在时域上的变化,相邻帧之间的相关性来找到前一帧与当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息。光流表达了图像的变化,由于它包含了目标运动的信息,因此可被观察者用于确定目标的运动情况。
在真实的三维空间中,描述物体运动状态的物理概念是运动场(Motion Field)。三维空间中的每一个点,经过某段时间的运动之后会到达一个新的位置,而这个位移过程可以用运动场来描述,运动场的实质上就是物体在三维真实世界的运动,而时光流畅(Optical Flow Field)是指图像中所有像素点构成的一种二维瞬时速度场它是一个二维矢量场。
三维空间运动到二维平面的投影所形成的光流,当描述部分像素时,称为稀疏光流,当描述全部像素时,则称为稠密光流。
OpenCV实现了不少光流算法,其中,Lucas-Kanade(L-K)是一种广泛使用的光流估计差分算法,它由布鲁斯·D.卢卡斯(Bruce D.Lucas)和金出武雄(Takeo Kanade)提出,L-K算法假设光流在像素点的领域是一个常数,然后使用最小二乘法对领域中的所有像素点求解基本的光流方程。通过结合几个邻近像素点的信息,L-K算法通常能够消除光流方程中的多义性。而且与逐点计算的方法比,L-K算法对图像噪声不敏感。对于L-K算法,低速度,亮度不变以及区域一致性都是较强的假设,但是这些条件并不容易满足。当运动速度过快时,这种假设不成立,使得最终求出的光流值有较大的误差。吉思——伊卡斯·布格(Jean—Yves Bouguent)提出了一种基于金字塔分层的算法,针对仿射变换的改进L-K算法,该算法最明显的优势在于,对于每一层的光流都会保持很小,但最终计算的光流可进行累积,从而可有效地跟踪特征点。L-K算法现已逐渐发展成为计算图像稀疏光流的重要方法。通过金字塔L-K算法计算稀疏光流的示例代码:
#L-K算法
import numpy as np
import cv2
#设置L-K算法参数
lk_params=dict(winSize=(15,15), #搜索窗口的大小
maxLevel=2,#最大金字塔层数
#迭代算法终止条件(迭代次数或迭代阈值)
criteria=(cv2.TERM_CRITERIA_EPS|cv2.TERM_CRITERIA_COUNT,10,0.03))
feature_params=dict(maxCorners=500, #设置最多返回的关键点(角点)数
qualityLevel=0.3, #角点阈值:反映一个像素点对强才算一个角点
minDistance=7, #角点之间的最小像素点(欧氏距离)
blockSize=7) #计算一个像素点是否为关键点时所取区域的大小
class App:
#构造方法,初始化一些参数和视频路径
def __init__(self,video_src):
self.track_len=10 #光流标记长度
self.detect_interval=5#帧检测间隔
#跟踪点几何初始化,self.tracks中值的格式时:(前一帧角点)
self.tracks=[]
self.cam=cv2.VideoCapture(video_src) #视频源
self.frame_idx=0 #帧序列号初始化
def run(self): #运行光流方法
while True:
ret,frame=self.cam.read()
if ret ==True:
frame_gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
vis=frame.copy()
#检测到角点后光流跟踪
if len(self.tracks)>0:
img0,img1=self.prev_gray,frame_gray
p0=np.float32([tr[-1] for tr in self.tracks]).reshape(-1,1,2)
#将前一帧的角点和当前帧的图像作为输入的角点在当前帧的位置
p1,st,err=cv2.calcOpticalFlowPyrLK(img0,img1,p0,None,**lk_params)
#将当前帧跟踪到的角点以及图像和前一帧的图像作为输入得到前一帧的角点检测
p0r,st,err=cv2.calcOpticalFlowPyrLK(img1,img0,p1,None,**lk_params)
#得到角点回溯与前一帧实际角点的位置变化系
d=abs(p0-p0r).reshape(-1,2).max(-1)
good=d<1 #判断d的值是否小于1
new_tracks=[]
#将跟踪的点列为成功跟踪点
for tr,(x,y),good_flag in zip(self.tracks,p1.reshape(-1,2),good):
if not good_flag:
continue
tr.append((x,y))
if (len(tr)>self.track_len):
del tr[0]
new_tracks.append(tr)
cv2.circle(vis,(x,y),2,(0,255,0),-1)
self.tracks=new_tracks
#以前一帧角点为初始点,以当前帧跟踪到的点为终点划线,开始轨迹标记
cv2.polylines(vis,[np.int32(tr) for tr in self.tracks],False,(0,255,0))
#每五帧检测一次
if (self.frame_idx % self.detect_interval==0):
mask=np.zeros_like(frame_gray)#初始化和视频尺寸大小相同的图像
mask[:]=255 #计算全部图像的角点
for x,y in [np.int32(tr[-1]) for tr in self.tracks]:
cv2.circle(mask,(x,y),5,0,-1)
#利用goodFeaturesToTrack进行角点检测
p=cv2.goodFeaturesToTrack(frame_gray,mask=mask,**feature_params)
if p is not None:
for x,y in np.float32(p).reshape(-1,2):
self.tracks.append([(x,y)]) #将检测到的角点放在预跟踪序列
self.frame_idx+=1
self.prev_gray=frame_gray
cv2.imshow('Lucas-Kanade光流算法',vis)
ch=0xFF & cv2.waitKey(1)
if ch==ord('q'):#按q键退出
break
def main():
import sys
video_src='D:\Image\haha.mp4'
App(video_src).run() #运行主程序
cv2.destroyAllWindows()
if __name__=='__main__':
main() 由于视频是本地文件,不能展示出来,这里就直接呈现代码;通过运行结果程序可知,稠密光流算法是一种对图像进行逐点匹配的图像配准算法。不同于稀疏光流算法只针对图像中若干个特征点,稠密光流算法计算图像上所有的点的偏移量,从而形成一个稠密的光流场。通过这个稠密的光流场,可以进行像素级别的图像配准,因此,其配准后的效果也明显优于稀疏光流算法配准的效果。但是其副作用也非常明显,由于要计算每个点的偏移量,其计算量也明显大于稀疏光流算法。
CalOpticalFlowFraneback()算法
在OpenCV中,CalOpticalFlowFraneback()函数利用Gunnar Farneback算法进行全局性稠密光流算法,其参数说明如下:
- (1)prevImg:输入的8bit单通道前一帧图像。
- (2)nextImg:输入的8bit单通道当前帧图像。
- (3)pyr_scale:金字塔参数,0.5为经典参数,每一层是下一层尺度的一般。
- (4)levels:金字塔的层数。
- (5)winsize:窗口大小。
- (6)iterations:迭代次数。
- (7)poly_n:像素领域的大小,如果值比较大则表示图像整体比较平滑。
- (8)poly_sigma:高斯标准差。
- (9)flags:可以为这些组合——OPTFLOW_USE_INITIAL_FLOW,OPTFLOW_FARNEBACK_GAUSSIAN,返回值为每一个像素点的位移。
基于稠密光流算法的运动轨迹标记的代码:
#基于稠密光流算法轨迹标记
from numpy import *
import cv2
#定义光流跟踪标记函数
def draw_flow(im,flow,step=16):
h,w=im.shape[:2]
y,x=mgrid[step/2:h:step,step/2:w:step].reshape(2,-1)
fx,fy=flow[y.astype(int),x.astype(int)].T
#创建标记线条端点
lines=vstack([x,y,x+fx,y+fy]).T.reshape(-1,2,2)
lines=int32(lines)
#创建图像和进行线条标记
vis=cv2.cvtColor(im,cv2.COLOR_GRAY2BGR)
for (x1,y1),(x2,y2) in lines:
cv2.line(vis,(x1,y1),(x2,y2),(0,255,0),1)
cv2.circle(vis,(x1,y1),1,(0,255,0),-1)#画圆
return vis
cap=cv2.VideoCapture(1)#开启摄像头
#读取视频帧
ret,im=cap.read()
#转化为灰度图像
prev_gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
while True:
#读取视频帧
ret,im=cap.read()
#转换为灰度图像
gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
#光流计算
flow=cv2.calcOpticalFlowFarneback(prev_gray,gray,None,0.5,3,15,3,5,1.2,0)
prev_gray=gray
#绘制光流轨迹
cv2.imshow('稠密光流算法',draw_flow(gray,flow))
if cv2.waitKey(1)&0xFF==ord('q'): #按q键结束
break
im.release()
cv2.destroyAllWindows()
运动检测
运动检测(Motion Detection)是计算机视觉和视频处理中常用的预处理步骤,是指从视频中识别发生变化或移动的区域。运动检测最常见的应用场景是运动目标检测,也就是对摄像头记录的视频移动目标进行定位到过程,有着非常广泛的应用。实时目标检测是许多计算机视觉的重要任务,例如安全监控,增强现实应用,基于对象的视频压缩,基于感知的用户界面及辅助驾驶等。
运动目标检测算法根据目标与摄像机之间的关系可以分为静态背景下的运动目标检测和动态背景下的运动目标检测。静态背景下的运动目标检测,就是从序列图像中将实际的的变化区域与背景分开。在背景静止的大前提下进行运动目标检测的方法有很多,大多侧重于背景扰动小噪声的消除,如背景差分法(Background Difference Nethod ,BDM),帧间差分法(Inter-Frame Difference Method,IFDM),光流法,高斯混合模型(Gaussion Mixed Model,GMM),码本(Codebook),自组织背景减除(Self-Organizing Background Subtraction,SOBS),视觉背景提取(Visual Background Extractor,VIBE)以及这些方法的变种,如三帧差分法,五帧差分法,或者这些方法的结合。动态背景下的运动目标检测,相对于静态背景而言,算法的思路有所不同,一般更侧重于匹配,需要进行图像的全局运动估计与补偿,因为在目标和背景同时运动的情况下,无法简单的根据运动来判断。动态背景下的运动目标检测算法也有很多,例如块匹配(Block Matching,BM)和光流估计(Optical Flow Estimation,OFE)等。
帧间差分法是一种常用的运动目标检测算法,其基本原理是观测视频图像相邻帧之间的细微变化来判断物体是否在运动。摄像机采集的视频序列具有连续性,如果场景内没有运动目标,则连续帧的变化很小;如果存在运动目标,由于场景中的目标的运动,目标的影像在不同图像帧之间的位置会不同,从而导致连续帧之间有显著变化。该算法通过对时间上连续的两帧或三帧图像进行差分运算,对不同帧对应的的像素点灰度值想减,来判断灰度值的绝对值,当绝对值超过一定阈值时,则可判断其为运动目标,从而实现目标的检测功能。
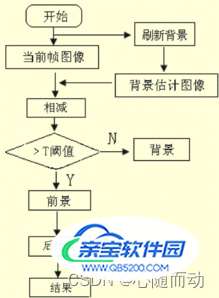
(二帧差分原理图)
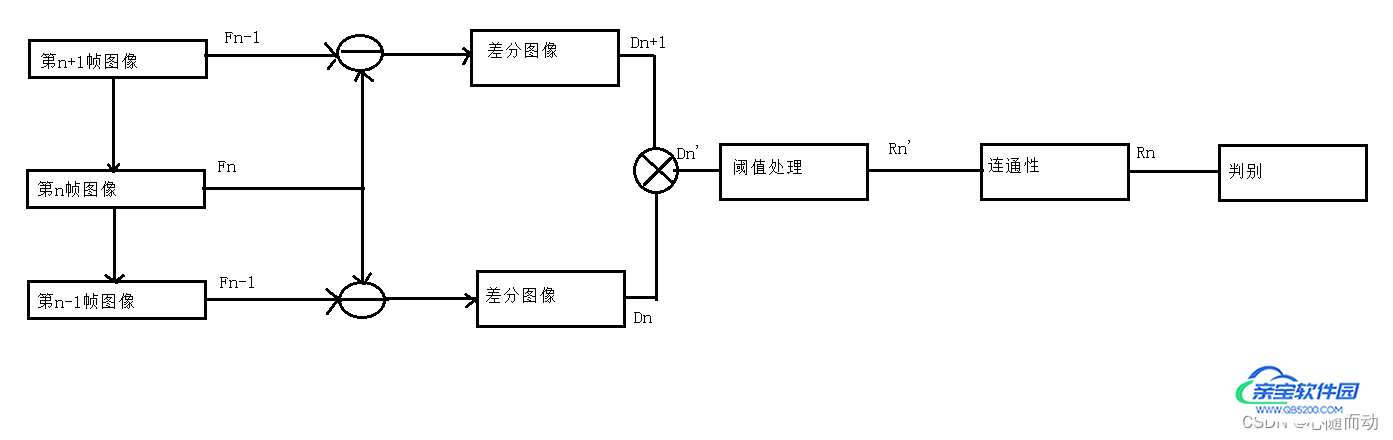
(三帧差分原理图)
在OpebCV中用absdiff()函数实现。
三帧差分法的运算过程如上图所示。记视频序列中第n+1帧、第n帧和第n-1帧的图像分别为fn+1、fn和fn-1,三帧对应像素点的灰度值记为fn+1(x,y)、fn(x,y)和fn-1(x,y),分别得到差分图像Dn和Dn+1,对差分图像Dn和Dn+1按照下式进行计算,得到图像Dn',然后再进行阈值处理、连通性分析,最终提取出运动目标。
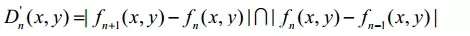
在帧间差分法中,阈值T的选择非常重要。如果阈值T选取的值太小,则无法抑制差分图像中的噪声;如果阈值T选取的值太大,又有可能掩盖差分图像中目标的部分信息;而且固定的阈值T无法适应场景中光线变化等情况。为此,有人提出了在判决条件中加入对整体光照敏感的添加项的方法,将判决条件修改为:
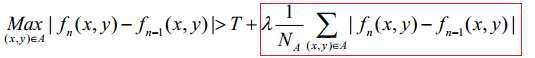
其中,NA为待检测区域中像素的总数目,λ为光照的抑制系数,A可设为整帧图像。红框中的添加项表达了整帧图像中光照的变化情况。如果场景中的光照变化较小,则该项的值趋向于零;如果场景中的光照变化明显,则该项的值明显增大,导致上式右侧判决条件自适应地增大,最终的判决结果为没有运动目标,这样就有效地抑制了光线变化对运动目标检测结果的影响。
下图中左图是采用帧间差分法进行运动目标检测的实验结果,(b)图是采用两帧差分法的检测结果,(c)图是采用三帧差分法的检测结果。视频序列中的目标运动较快,在这种情况下,运动目标在不同图像帧内的位置明显不同,采用两帧差分法检测出的目标会出现“重影”的现象,采用三帧差分法,可以检测出较为完整的运动目标。
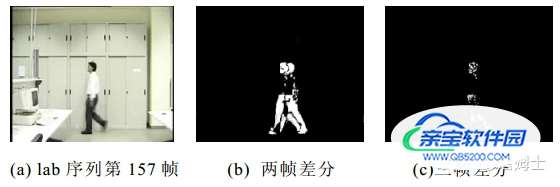
综上所述,帧间差分法的原理简单,计算量小,能够快速检测出场景中的运动目标。但由实验结果可以看出,帧间差分法不能提取出对象的完整区域,只能提取出边界。同时依赖于选择的帧间时间间隔,对快速运动的物体,需要选择较小的时间间隔,如果选择不合适,当物体在前后两帧中没有重叠时,会被检测为两个分开的物体,而对慢速运动的物体,应该选择较大的时
间差,如果时间选择不适当,当物体在前后两帧中几乎完全重叠时,则检测不到物体。
因此帧间差分法通常不单独用在目标检测中,往往与其它的检测算法结合使用。常见的是结合背景差分法和帧间差分法的优缺点,使它们优势互补,从而克服相互的弱点,提高运动检测的效果。例如在实际的场景中,即便是室内环境,也存在光线等各种变化造成的干扰,或者人为造成的开灯等光线的强烈变化。所以在背景差分法的实现中,它的固定背景不能一成不变。如果不进行重新初始化,错误的检测结果将随时间不断累计,造成恶性循环,从而造成监控失效。
利用帧间差分法示例代码:
#利用帧间差分法进行目标检测
import time
import cv2
import argparse #用于解析参数
import datetime #用于时间和日期相关处理
import imutils #用于图像相关处理
import argparse
#创建参数解析器并解析参数
ap=argparse.ArgumentParser()
ap.add_argument('-v','--video',help='path to the video file')
ap.add_argument('-a','--min-area',type=int,default=500,help='minimum area size')
args=vars(ap.parse_args(args=[])) #这里有两种表达式,JUPYTER只能使用这种,表示默认参数,pycharme可以用另一种
#如果video参数为None,那么我们从摄像头读取数据
if args.get('video',None) is None:
camera=cv2.VideoCapture(1)
if camera is None:
print("请检查摄像头连接")
exit()
time.sleep(0.25)
else:
#读取一个视频
camera=cv2.VideoCapture('D:\Image\haha.mp4')
'''
初始化视频流的第一帧。一般情况下,视频第一帧不会包含运动而仅仅是背景
'''
firstFrame=None
#遍历视频的每一帧
while True:
'''
获取当前视帧并初始化显示文本,调用camera.read()将返回一个二元组,元组的第一个值是True和False,表明是否成功从缓冲中读取帧图像,元组的第二个值就是获取的当前帧图像的值。
'''
(grabbed,frame)=camera.read()
text='No Motion Detected'
#如果不能获取到帧,说明到了视频的结尾
if not grabbed:
break
frame=imutils.resize(frame,width=500) #调整帧图像大小
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY) #转换为灰度图像
gray=cv2.GaussianBlur(gray,(21,21),0)#高斯模糊处理
#如果第一帧是None,对其进行初始化
if firstFrame is None:
firstFrame=gray
continue
#将当前帧和第一帧图像对应的像素点的灰度值相减并求绝对值来计算两帧的不同
frameDelta=cv2.absdiff(firstFrame,gray)
#对差分图像进行阈值处理来显示图像中像素点的灰度值有所变化的区域
thresh=cv2.threshold(frameDelta,25,255,cv2.THRESH_BINARY)[1]
#扩展阈值图像填充空洞,然后找到阈值图像中的轮廓
thresh=cv2.dilate(thresh,None,iterations=2)
'''
cv2.findContours()函数返回3个值,第一个是所处理的图像,第二个是轮廓,第三个是每个轮廓对应的属性
'''
contours,hierrarchy=cv2.findContours(thresh.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) #老版返回3个接受参数,新版返回两个;
#遍历轮廓
for c in contours:
#过滤小的,不相关的轮廓,如果轮廓面积大于min_area,则在前景和移动区域画边框
if cv2.contourArea(c)<args['min_area']:
continue
#计算轮廓的边界框,在当前帧中画出该框并更新相应文本
(x,y,w,h)=cv2.boundingRect(c)
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
text='Motion Detected'
#在当前帧上写文本及时间戳
cv2.putText(frame,'Room Status:{}'.format(text),(10,20),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,0,255),2)
cv2.putText(frame,datetime.datetime.now().strftime('%A %%d %B %Y %I:%M:%S%p'),(10,frame.shape[0]-10),cv2.FONT_HERSHEY_SIMPLEX,0.35,(0,0,255),1)
#显示当前帧并记录用户是否按了键
cv2.imshow('视频监控演示',frame)
cv2.imshow('阈值轮廓图像',thresh)
cv2.imshow('帧差分图像',frameDelta)
key=cv2.waitKey(1)
if key==ord('q'):
break #跳出循环
#释放摄像机资源并关闭打开的窗口
camera.release()
cv2.destroyAllWindows()
由于视频不太容易上传,这里就使用截屏作为结果展示。
运动方向检测
在某些应用场合,检测出运动的物体之后,我们还需知道物体的运动方向,判断其是否进入或离开检测区域。对于运动方向的检测,一般通过检测图像的光流场估算图像的运动场来实现。根据传统估算方法,需要对图像中的每一个像素进行计算,算出图像每一点的运动场,然后得到整幅图像的运动场。
检测物体的运动方向,理论上也可以使在帧间差分法的基础上通过计算帧图像轮廓中点的变化来实现,但因每次检测出的轮廓数量不稳定,所以该方式会使得误差不可控。不过,OpenCv中的goodFeaturesToTrack()函数可用于获取图像最大特征只的角点。我们可以此为契机重新设计物体运动方向检测算法,步骤如下:
- (1) 对相邻两帧图像所有像素点通过absdiff()函数进行差分运算得到差分图像。
- (2) 将差分图像转化成灰度图像并进行二值化处理。
- (3) 利用goodFeaturesToTrack()函数获得最大特征值的角点。
- (4) 计算角点的平均特征值,写入队列。
- (5) 维护一个长度为10的队列,队列满时计算队列中元素的增减情况,并以此来确定目标的运动方向。
利用上述改进算法进行物体运动方向检测的示例代码:
#运动方向检测
import cv2
import numpy as np
import queue #导入库主要用于队列处理
camera=cv2.VideoCapture(1)
if camera is None:
print('请检查摄像头链接')
exit()
width=int(camera.get(3))
height=int(camera.get(4))
#参数初始化
firstFrame=None
lastDec=None
firstThresh=None
feature_params=dict(maxCorners=100, #设置最多返回的关键点数
qualityLevel=0.3, #角点阈值:响应最大值
minDistance=7, #角点之间最少像素点(欧氏距离)
blockSize=7) #计算一个像素点是否为关键点时所取区域
#Lucas-Kanade 光流算法参数设置
lk_params=dict(winSize=(15,15),#搜索窗口的大小
maxLevel=2,#最大金字塔层数
criteria=(cv2.TermCriteria_EPS|cv2.TERM_CRITERIA_COUNT,10,0.03))
color=np.random.randint(0,255,(100,3))
num=0
#队列初始化
q_x=queue.Queue(maxsize=10)
q_y=queue.Queue(maxsize=10)
while True:
#获取视频帧并转化为灰度图像
(grabbed,frame)=camera.read()
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
gray=cv2.GaussianBlur(gray,(21,21),0)
if firstFrame is None:
firstFrame=gray
continue
frameDelta=cv2.absdiff(firstFrame,gray)
#对图像进行阈值二值化
thresh=cv2.threshold(frameDelta,25,255,cv2.THRESH_BINARY)[1]
p0=cv2.goodFeaturesToTrack(thresh,mask=None,**feature_params)
if p0 is not None:
x_sum=0
y_sum=0
for i,old in enumerate(p0):
x,y=old.ravel()
x_sum+=x
y_sum+=y
x_avg=x_sum/len(p0)
y_avg=y_sum/len(p0)
if q_x.full():
qx_list=list(q_x.queue)
key=0
diffx_sum=0
for item_x in qx_list:
key+=1
if key<10:
diff_x=item_x-qx_list[key]
diffx_sum+=diff_x
if diffx_sum<0 and x_avg<500:#表明队列在增加
print('Left')
cv2.putText(frame,'Left Motion Detected',(100,100),0,0.5,(0,0,255),2)
else:
print("Right")
cv2.putText(frame,"Right Motion Detected",(300,100),0,0.5,(255,0,255),2)
q_x.get()
q_x.put(x_avg)
cv2.putText(frame,str(x_avg),(300,100),0,0.5,(0,0,255),2)
frame=cv2.circle(frame,(int(x_avg),int(y_avg)),5,color[i].tolist(),-1)
cv2.imshow('运动方向检测',frame)
firstFrame=gray.copy()
key=cv2.waitKey(1)&0xFF
if key==ord('q'):
break
camera.release()
cv2.destroyAllWindows()加载全部内容