GoLang函数栈的使用详细讲解
raoxiaoya 人气:0函数栈帧
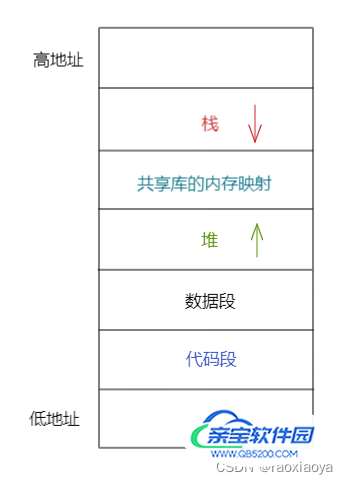
我们的代码会被编译成机器指令并写入到可执行文件,当程序执行时,可执行文件被加载到内存,这些机器指令会被存储到虚拟地址空间中的代码段,在代码段内部,指令是低地址向高地址堆积的。堆区存储的是需要程序员手动alloc并free的空间,需要自己来控制。
虚拟内存空间是对存储器的一层抽象,是为了更好的来管理存储器,虚拟内存和存储器之间存在映射关系。
如果在一个函数中调用了另外一个函数,编译器就会对应生成一条call指令,当call指令被执行时,就会跳转到被调用函数入口处开始执行,而每个函数的最后都有一条ret指令,负责在函数结束后跳回到调用处继续执行。
call 指令做了两件事,将下一条指令的地址入栈,这就是IP寄存器中存储的值,第二,跳转到被调用函数入口处执行。
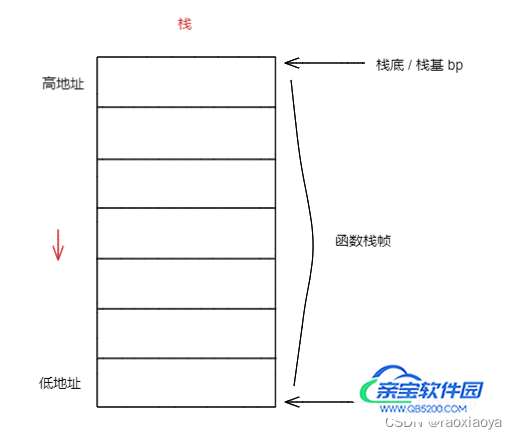
函数执行时需要有足够的内存空间用来存储参数,局部变量,返回值,这块空间对应的就是栈,栈区是从高地址向低地址生长的,且先进后出。分配给函数的栈空间被称为函数栈帧。
C语言中,每个栈帧对应着一个未运行完的函数。栈帧中保存了该函数的返回地址和局部变量。
寄存器
ESP寄存器:ESP即 Extended stack pointer 的缩写,直译过来就是扩展的栈指针寄存器。SP是16位的,ESP是32位的,RSP是64位的,存放的都是栈顶地址。
EBP寄存器:EBP即 Extended base pointer 的缩写,直译过来就是扩展的基址指针寄存器。该指针总是指向当前栈帧的底部。
IP寄存器:指令指针,它指向代码段中的地址,是一个16位专用寄存器,它指向当前需要取出的指令字节,也就是下一个将要执行的指令在代码段中的地址。
eax:累加(Accumulator)寄存器,常用于函数返回值
ebx:基址(Base)寄存器,以它为基址访问内存
ecx:计数器(Counter)寄存器,常用作字符串和循环操作中的计数器
edx:数据(Data)寄存器,常用于乘除法和I/O指针
esi:源地址寄存器
edi:目的地址寄存器
esp:堆栈指针
ebp:栈指针寄存器
当然,以上功能并未限制寄存器的使用,特殊情况为了效率也可作其他用途。
这八个寄存器低16位分别有一个引用别名 ax, bx, cx, dx, bp, si, di, sp,
其中 ax, bx, cx, dx, 的高8位又引用至 ah, bh, ch, dh,低八位引用至 al, bl, cl, dl
在 64-bit 模式下,有16个通用寄存器,但是这16个寄存器是兼容32位模式的,
32位方式下寄存器名分别为 eax, ebx, ecx, edx, edi, esi, ebp, esp, r8d – r15d.
在64位模式下,他们被扩展为 rax, rbx, rcx, rdx, rdi, rsi, rbp, rsp, r8 – r15.
其中 r8 – r15 这八个寄存器是64-bit模式下新加入的寄存器。
我们看到CPU在执行代码段中的指令,而这当中又伴随着内存的分配,于是在函数栈帧上就会有相应的变化。
int add(int a, int b)
{
int c = 4;
c = a + b;
return c;
}
int main()
{
int a = 1;
int b = 2;
int sum = 3;
sum = add(a, b);
return 0;
}
生成的汇编代码的方式
1、使用 gcc + objdump
gcc -save-temps -fverbose-asm -g -o b testasm.c
objdump -S --disassemble b > b.objdump
2、使用第三方网站来生成,进入 https://godbolt.org/,选择语言为C,编译器为x86-64 gcc 12.2,粘贴进你的代码,就能看到汇编代码,如下
add:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-20], edi
mov DWORD PTR [rbp-24], esi
mov DWORD PTR [rbp-4], 4
mov edx, DWORD PTR [rbp-20]
mov eax, DWORD PTR [rbp-24]
add eax, edx
mov DWORD PTR [rbp-4], eax
mov eax, DWORD PTR [rbp-4]
pop rbp
ret
main:
push rbp
mov rbp, rsp
sub rsp, 16
mov DWORD PTR [rbp-4], 1
mov DWORD PTR [rbp-8], 2
mov DWORD PTR [rbp-12], 3
mov edx, DWORD PTR [rbp-8]
mov eax, DWORD PTR [rbp-4]
mov esi, edx
mov edi, eax
call add
mov DWORD PTR [rbp-12], eax
mov eax, 0
leave
ret
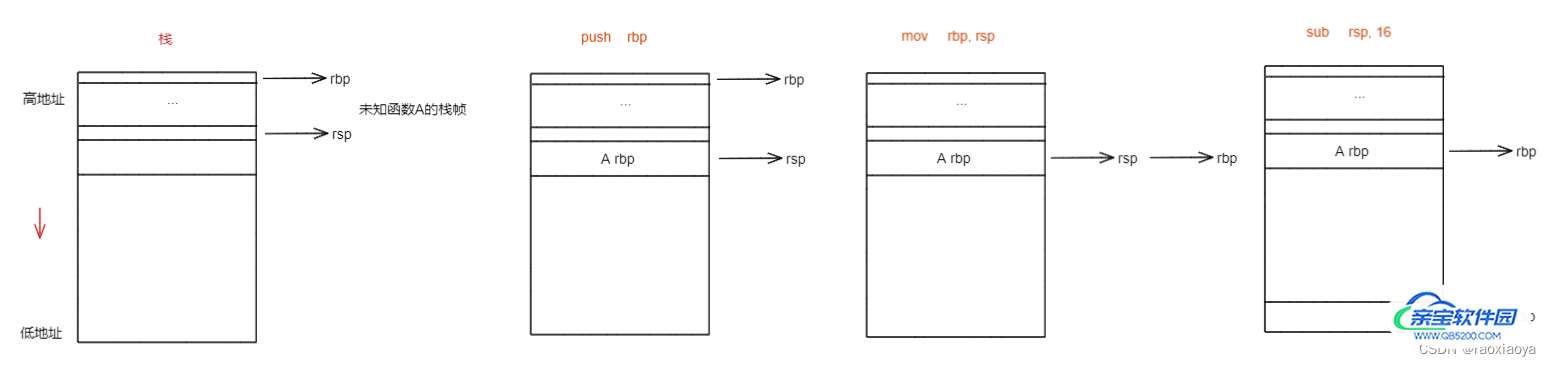
从main开始解读
// 此时rbp存储的还是上一层函数(调用者)的栈基地址,将rbp的值入栈保存起来,因为main函数也是被其他函 // 数调用的,运行完main之后还得回到那个函数体中去。这里的地址指的是指令的地址,是代码段中的位置。 // push指令会使rsp下移。 push rbp // 此时rbp存储的还是上一个函数的基地址,而rsp则已经游走到了main函数这里,mov指令将rsp中存储的地址传递 // 给rbp,也就意味着执行完之后rbp和rsp都处于main函数的开始位置,称为初始化操作。 mov rbp, rsp // rsp下移16,就是分配栈空间 sub rsp, 16
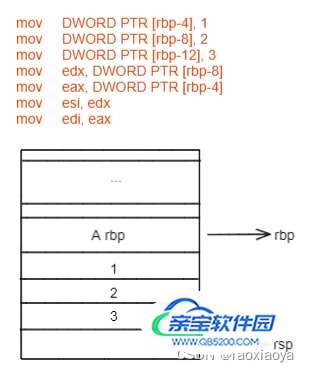
// DWORD 为双字,即四个字节,PTR为指针的意思,此句意为在rbp向下偏移4个字节的这段栈内存中存储0 // a mov DWORD PTR [rbp-4], 1 // b mov DWORD PTR [rbp-8], 2 // sum mov DWORD PTR [rbp-12], 3 // 将参数从右到左,依次存起来,此处存到了 edx和eax,并拷贝了一份到esi和edi。 mov edx, DWORD PTR [rbp-8]` mov eax, DWORD PTR [rbp-4]` mov esi, edx` mov edi, eax`
// 执行call指令
// 注意,call会使CPU跳入到add的栈帧中去,那么执行完之后,我们需要跳回到被调用处继续向下执行,由
// 最前面的push指令我们已经把调用者的栈基存了下来,可是我们还要精确到具体是回到哪个指令,这就是call
// 指令的额外工作,它会先将IP入栈(push ip),因为IP中存的就是下一条指令(mov DWORD PTR [rbp-12], eax)
// 的地址,然后再去跳转(jmp),将add函数的第一条指令写入IP,此后就进入add函数栈帧。
call add
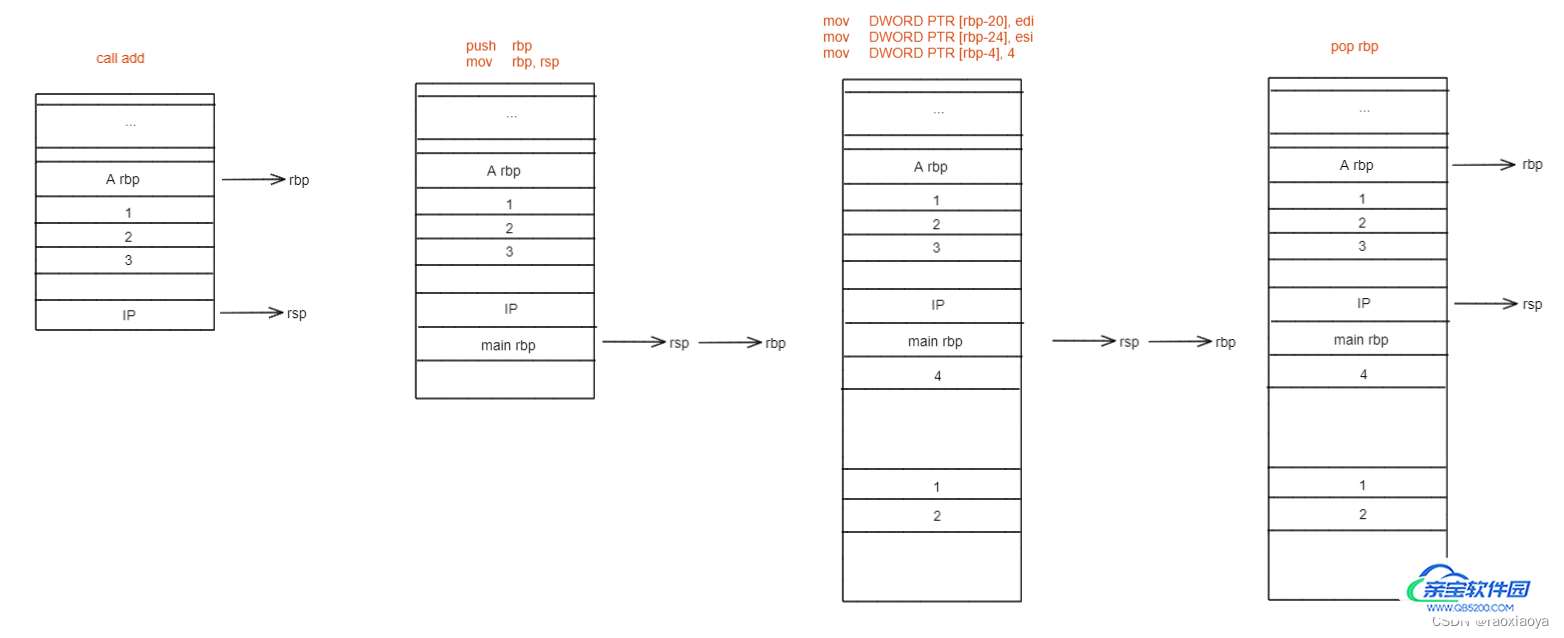
// cpu执行完运算后会将结果存储在寄存器中,至于它会把结果存储在那个寄存器,这个由编译器编译出的指令 // 决定的,由add函数的指令来看,它选择了eax // rbp-12 为sum的位置,这条指令将eax寄存器的值赋值给sum mov DWORD PTR [rbp-12], eax // 将eax置0,也就是main的返回值 mov eax, 0 // 意为 mov rsp, rbp 和 pop rbp 的组合 // 此时rbp为main函数的栈基,rsp为main函数的末尾了,将rbp赋值给rsp,于是它们都指向main函数的栈基,上 // 面解释过,rbp寄存器存储的地址指向的栈上的空间存储的还是一个地址,此地址指向调用者的栈基, // pop rbp 将栈顶rsp的数据送入rbp,就意味着之后就回到了调用者的栈帧了,同时pop会伴随着rsp的上移, // 于是rsp来到了EIP的位置。 leave // 相当于 pop ip // 此函数执行完需要跳回到调用者并继续执行下一条指令,由于call的时候已经将下一条指令的地址入栈了,所以 // 此处值需要将其弹出即可。 ret
加载全部内容