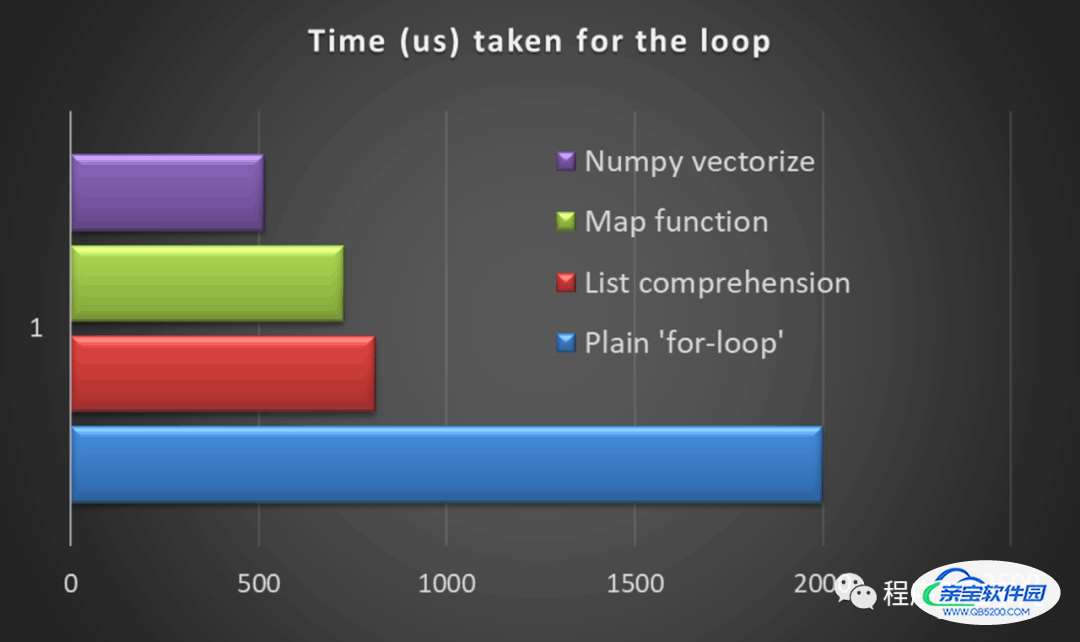
python中使用矢量化替换循环详解
梦回丶故里 人气:0所有编程语言都离不开循环。因此,默认情况下,只要有重复操作,我们就会开始执行循环。但是当我们处理大量迭代(数百万/十亿行)时,使用循环是一种犯罪。您可能会被困几个小时,后来才意识到它行不通。这就是在 python 中实现矢量化变得非常关键的地方。
什么是矢量化?
矢量化是在数据集上实现 (NumPy) 数组操作的技术。在后台,它将操作一次性应用于数组或系列的所有元素(不同于一次操作一行的“for”循环)。
接下来我们使用一些用例来演示什么是矢量化。
求数字之和
##使用循环
import time
start = time.time()
# iterative sum
total = 0
# iterating through 1.5 Million numbers
for item in range(0, 1500000):
total = total + item
print('sum is:' + str(total))
end = time.time()
print(end - start)
#1124999250000
#0.14 Seconds## 使用矢量化 import numpy as np start = time.time() # vectorized sum - using numpy for vectorization # np.arange create the sequence of numbers from 0 to 1499999 print(np.sum(np.arange(1500000))) end = time.time() print(end - start) ##1124999250000 ##0.008 Seconds
与使用范围函数的迭代相比,矢量化的执行时间减少了约 18 倍。在使用 Pandas DataFrame 时,这种差异将变得更加显著。
数学运算
在数据科学中,在使用 Pandas DataFrame 时,开发人员使用循环通过数学运算创建新的派生列。
在下面的示例中,我们可以看到对于此类用例,用矢量化替换循环是多么容易。
DataFrame 是行和列形式的表格数据。
我们创建一个具有 500 万行和 4 列的 pandas DataFrame,其中填充了 0 到 50 之间的随机值。

import numpy as np import pandas as pd df = pd.DataFrame(np.random.randint( 0 , 50 , size=( 5000000 , 4 )), columns=( 'a' , 'b' , 'c' , 'd ' )) df.shape # (5000000, 5) df.head()
创建一个新列“ratio”来查找列“d”和“c”的比率。
## 循环遍历
import time
start = time.time()
# 使用 iterrows 遍历 DataFrame
for idx, row in df.iterrows():
# 创建一个新列
df.at[idx, 'ratio' ] = 100 * (row[ "d" ] / row[ "c" ])
end = time.time()
print (end - start)
### 109 秒## 使用矢量化 start = time.time() df[ "ratio" ] = 100 * (df[ "d" ] / df[ "c" ]) end = time.time() print (end - start) ### 0.12 秒
我们可以看到 DataFrame 的显著改进,与Python 中的循环相比,矢量化操作所花费的时间几乎快 1000 倍。
If-else 语句
我们实现了很多需要我们使用“If-else”类型逻辑的操作。我们可以轻松地将这些逻辑替换为 python 中的矢量化操作。
让我们看下面的例子来更好地理解它(我们将使用我们在用例 2 中创建的 DataFrame):
想象一下,我们要根据现有列“a”上的某些条件创建一个新列“e”
## 使用循环
import time
start = time.time()
# 使用 iterrows 遍历 DataFrame
for idx, row in df.iterrows():
if row.a == 0 :
df.at[idx, 'e' ] = row.d
elif ( row.a <= 25 ) & (row.a > 0 ):
df.at[idx, 'e' ] = (row.b)-(row.c)
else :
df.at[idx, 'e' ] = row.b + row.c
end = time.time()
print (end - start)
### 耗时:166 秒## 矢量化 start = time.time() df[ 'e' ] = df[ 'b' ] + df[ 'c' ] df.loc[df[ 'a' ] <= 25 , 'e' ] = df [ 'b' ] -df[ 'c' ] df.loc[df[ 'a' ]== 0 , 'e' ] = df[ 'd' ]end = time.time() 打印(结束 - 开始) ## 0.29007707595825195 秒
与使用 if-else 语句的 python 循环相比,向量化操作所花费的时间快 600 倍。
解决机器学习/深度学习网络
深度学习要求我们解决多个复杂的方程式,而且需要解决数百万和数十亿行的问题。在 Python 中运行循环来求解这些方程式非常慢,矢量化是最佳解决方案。
例如,计算以下多元线性回归方程中数百万行的 y 值:
我们可以用矢量化代替循环。
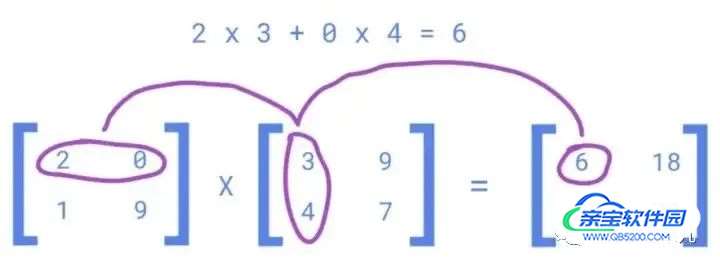
m1、m2、m3……的值是通过使用与 x1、x2、x3……对应的数百万个值求解上述等式来确定的
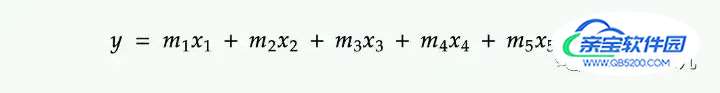
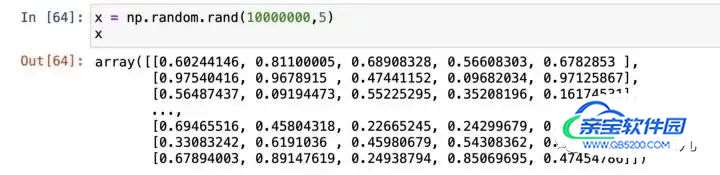
import numpy as np # 设置 m 的初始值 m = np.random.rand( 1 , 5 ) # 500 万行的输入值 x = np.random.rand( 5000000 , 5 )
## 使用循环
import numpy as np
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total = 0
tic = time.process_time()
for i in range(0,5000000):
total = 0
for j in range(0,5):
total = total + x[i][j]*m[0][j]
zer[i] = total
toc = time.process_time()
print ("Computation time = "+ str ((toc - tic)) + "seconds" )
####计算时间 = 27.02 秒## 矢量化 tic = time.process_time() #dot product np.dot(x,mT) toc = time.process_time() print ( "计算时间 = " + str ((toc - tic)) + "seconds" ) ####计算时间 = 0.107 秒
np.dot 在后端实现向量化矩阵乘法。与 Python 中的循环相比,它快 165 倍。
结论
python 中的矢量化速度非常快,无论何时我们处理非常大的数据集,都应该优先于循环。

随着时间的推移开始实施它,您将习惯于按照代码的矢量化思路进行思考。
加载全部内容