详解JavaScript中的闭包是如何产生的
前端西瓜哥 人气:0这次从内存管理的角度来看看,闭包是怎么产生的。
我们知道,在调用函数时,其实会产生临时的 调用栈。这些调用栈保存的是 执行上下本,并实际保存在 栈内存 中。
每执行一个函数,函数内的局部临时变量会临时保存起来。如果此时函数又调用了另一个函数,另一个函数下的局部变量也要保存下来,就这样,我们产生了栈。
当一个函数执行完后,它对应的局部临时变量就会被销毁。
局部变量保存下来,是为了保护上下文现场。
举例说明一下:
function a() {
const a_num = 99;
const a_obj = { val: "a" };
b();
}
function b() {
const b_str = "text";
c();
}
function c() {
const c_bool = true;
// debugger
}
a();
这里我们嵌套调用了 a、b、c 函数,会产生如下的调用栈。

基本类型的临时变量,会直接保存到栈内存中,对于引用类型,则是在堆内存中生成,然后将地址拿到,保存到栈内存中。
引用类型为什么不直接放到栈内存中?因为栈内存不是很大,很容易就栈溢出,而引用类型通常很大。
闭包的产生
函数调用完成后,它内部声明的临时变量会被销毁。理论上应该如此,但如果使用了闭包,可以会让临时变量一直保留不被销毁。
例子:
function createCounter() {
let count = 0;
let otherVal = "other val";
return function counter() {
// debugger;
console.log(count++);
};
}
const counter = createCounter();
console.log(counter());
执行过程为:
- 执行函数 createCounter 时,会创建一个空的上下文对象。
- 遇到内部函数 counter,会 预扫描内部函数 counter 使用了 createCounter 下的哪些便利,最终扫描出 count 变量。于是在堆内存创建一个闭包
Closure (createCounter)对象,将 count 加进去。otherVal 不会加到闭包对象上,因为它没有被使用。 - 这个内部函数最后被返回,被引用,闭包就一直不会销毁。
使用 DevTool 可以观察到这个闭包对象:
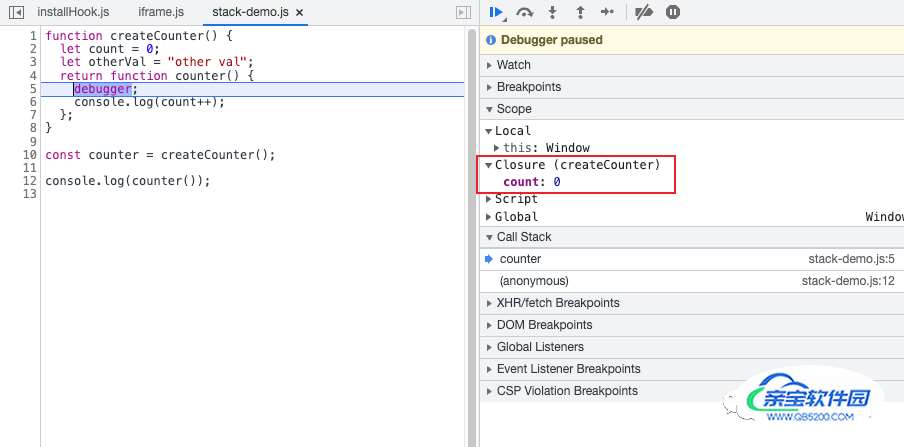
所以,如果一个闭包返回的函数执行完后不用了,要设置为 null。否则它关联的闭包对象会一直在那里占用内存。
多个内部函数共享一个闭包对象
另外,如果有多个内部函数,这些函数会共用同一个闭包对象。即使其中的一个内部函数不会返回,它也会给闭包对象加东西。
下面我们加了一个 printOtherVal 的内部函数,它并不返回,但还是会导致返回 counter 函数对应的闭包对象带上了它不需要的 otherVal 变量。
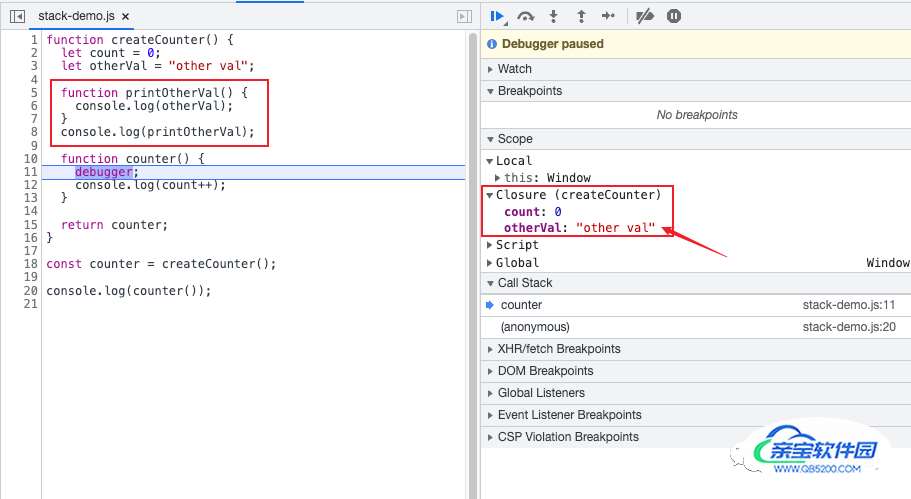
这是 JS 引擎处理闭包策略问题,理论不应该有这样奇怪的效果。
结尾
调用函数时,会产生调用栈,将当前函数上下文入栈,会保存基本类型变量。引用变量会在堆内存中创建,然后在栈内存中引用过来。
因为 JavaScript 中函数是第一公民,所以会有闭包的概念。当发现内部函数,会创建一个闭包对象,将其中使用到的外部函数变量保存到该闭包对象下。之后内部函数被调用时,就会从闭包里提取变量,如果找不到则从全局上下文提取。
加载全部内容