goroutine 泄漏和避免泄漏实战示例
山与路 人气:0goroutine 泄漏和避免泄漏的最佳实践
Go的奇妙之处在于,我们可以使用goroutines和channel轻松地执行并发任务。如果在生产环境中使用goroutines和channel,但是不了解它们的行为方式,会造成一些严重的影响。
好吧,我们就面临着这样的影响,我们在goroutines中出现了泄漏,导致应用服务器随着时间的推移而膨胀,消耗了大量的CPU和频繁的GC,影响了多个服务的SLA。
从本文中可以看到什么
理解什么是goroutine泄露。 理解goroutine泄漏的多种方式。 详细了解造成goroutine泄露的一个真实场景。 我们是如何找到goroutine泄漏原因? 阻止goroutine泄漏的最佳实践是什么?

正如你在上面所附的指标中所看到的,goroutines开始随着时间的推移成倍地飙升。唯一的一次下降是当我们的一个正在运行的实例被AWS调度走,新的实例被启动,或者有一个新的版本,杀死了现有的容器并产生了新的容器。
如果你观察GC暂停的时间,它会随着活动的goroutine的数量不断增加。GC暂停的次数越多,CPU利用率就越高,响应时间也越来越长。
什么是goroutine泄漏?
goroutine泄漏是指客户端生成一个goroutine来做一些异步任务,并在任务完成后将一些数据写入一个channel,但是
没有监听程序消耗该channel的数据写入。
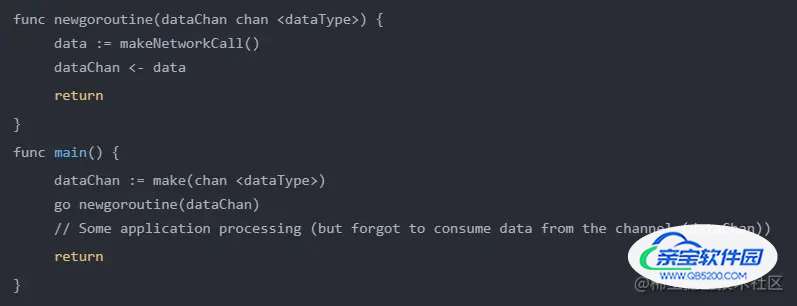
在上述情况下,代码成功地完成了执行,好像根本就没有问题。但这里发生的情况是,会有一个没有被管理的goroutine驻留在内存中,占用CPU和RAM。
原因分析
主要原因是第3行,我们正在向一个通道写入数据,但根据Go原则,一个未缓冲的通道会阻止向通道的写入,直到消费者从该channel取走信息。
所以在这种情况下,第4行的返回将永远不会被执行,并且newgoroutine函数在整个应用程序生命周期中都被卡住,因为这个channel没有消费者。
在goroutine启动和channel监听器之间有一些条件逻辑。

在这个案例中,有一个小小的改进。我们有一个消费者从dataChan中消费数据,但是从我们生成goroutine开始,到我们开始从通道中消费数据之前,有大量的应用程序代码驻留在那里,这些代码可以在一些处理错误|DB错误|无指针异常|panic的情况下退出主函数,由于这些原因,channel的数据可能从未被执行。
这就是一个goroutine看似正常,实际可能导致泄漏的情况。
我们不能在应用处理之前将channel中的值提前消费,因为消费者会阻止剩下业务逻辑的处理,直到它收到数据,从而消除了并发任务的执行。
发送完成立刻返回 以上两种情况是当goroutine因为没有channle的消费者而被阻塞,或者消费者从channel中消费数据的代码块被跳过。
当我们把一个channel传递给goroutine去消费时,当发送者向通道发送数据时出现了问题,这是否也是同样的情况?

好吧,95%的goroutine泄露都是因为这3种情况中的一种,在我们的案例中,是由于情景-2。我们在GoIbibo-Makemytrip的工作是折扣和便利费服务。
当客户应用一个促销代码时,我们有一套规则要执行,以找出正确的折扣。我们有另一个微服务,我们称之为实时动态折扣器(DD),它试图根据一些算法(黑盒子)来计算折扣。
这个动态折扣是一个A/B实验,只有10%的用户会参与其中。只有当我们的静态规则中存在有效的折扣时,我们才会覆盖DD折扣。
伪代码

我们只有在处理完静态规则后才需要DD的响应。所以来自ddChan的消费将在最后进行。
如果静态规则的评估有问题|如果没有满足请求的有效规则|如果用户应用了一些假的促销活动,我们从ddChan中消耗数据的代码将无法到达,这导致loadDDDiscount函数成为一个无法控制的goroutine。
有什么方法可以解决这个问题?
方法-1 方法 -> 从我们启动goroutine开始,到我们从退出channel的消耗数据为止,我们识别每一个错误条件,并在每一个返回语句前放置一个接收者,以解除对生成的goroutine的封锁。
陷阱 -> 我们必须手动找到所有的边缘情况,并且在将来,如果我们必须处理更多的错误情况,我们需要记住在返回之前我们需要消耗哪些channel的数据。
方法-2 方法 -> 与其在每个错误的情况下放置一个接收者,为什么不设置一个可以从channel中接收数据的延迟函数。
陷阱 -- 在成功的情况下,数据将在处理完静态规则后从通道中读取。因此,如果我们在defer函数中开始接收通道中的数据,那么在成功的情况下就会阻塞主goroutine。
方法-3 没有完美的方法。在上述所有场景中,我们创建了一个无缓冲的通道,阻止发送者向该通道发送数据,直到接收者收到数据。这里的主要问题是我们不确定由于我们的应用处理,接收方是否会被执行。那么,简单的解决方案是创建一个上限为1的缓冲通道。有了这个,即使没有消费者,或者消费者代码没有达到,发送者也不会被阻止写一次数据。 图片 陷阱 -> 绝对是零。这与非缓冲通道的工作原理完全相同,但为我们提供了一个额外的能力,即发送者在发送数据时不会受到阻碍,而消费者可以在任何时候消费它,而且生成的goroutine也不会等待消费者的到来。 我们用第三种方法将变化带入生产环境,你可以看到显著的影响。
图片 以前是线性增长的goroutine数量,现在下降到150个,我们的GC暂停频率也是如此。
整个事情中最痛苦的部分是,如何找到代码中存在goroutine泄漏的部分?
所以我的方法是这样的。
当服务器启动时,使用debug.SetGCPercent(-1)禁用垃圾收集器。 现在运行代码中每一个使用Go程序的流程(Dev Env)。 在每个API的入口处,打印在开始和执行API之前和之后运行的goroutines的数量。
func ApplyPromo() {
fmt.Println(runtime.NumGoroutine())
defer fmt.Println(runtime.NumGoroutine()
// Process your application logic
}
现在,如果一个服务在前后返回不同的Goroutines数量,那么这个逻辑就存在泄漏。
我们有近20个API和大约35-40个地方使用了goroutines以改善并发性。幸运的是,我能够在前3次迭代中找出泄漏问题,并发现了这个存在泄漏的逻辑。
加载全部内容