教你用Node.js与Express建立一个GraphQL服务器
Jovie 人气:0前言
在这篇文章中,我们将对使用Node.js和Express建立GraphQL服务器的整个过程进行演练。我们将使用 Express 的中间件库express-graphql 来协助我们完成这一过程。
如果你还不熟悉GraphQL以及我们使用它的目的,请务必查看这篇文章,我们将深入了解GraphQL是什么以及为什么我们应该在我们的应用程序中使用它。
如果你已经熟悉它了,你可能想看看这篇文章,在这篇文章中我们用React实现了Apollo客户端来连接到我们现在要创建的服务器。
包含这篇文章中的代码的资源库可以在这里找到。
还有一个包含使用该服务器的前端的资源库,可以在这里找到。
所以,不用多说了,让我们开始吧。
GraphQL服务器配置设置
首先,我们可能想先创建一个新的目录,通过以下命令设置npm npm init命令,然后创建我们的 server.js文件,该文件将承载我们的GraphQL服务器。
一旦我们完成了这些,我们就需要安装以下库:
- express
- express-graphql
- graphql
- cors
server.js文件看起来应该是这样的:
const app = require("express")();
const cors = require('cors');
const { graphqlHTTP } = require("express-graphql");
const { buildSchema } = require("graphql");
const schema = buildSchema('');
const root = {
};
app.use(cors());
app.use(
"/graphql",
graphqlHTTP({
schema,
rootValue: root,
graphiql: true,
})
);
app.listen(8080, () => {
console.log('GraphQL server running on port 8080');
});让我们来看看配置过程的每一步,这样我们就能更好地了解实际发生的情况:
- 首先导入express并调用其导出的主函数,这样我们就可以通过app变量来设置我们的应用服务器了
- 导入cors库的主函数,以帮助我们解决在不同域(localhost与不同端口)上运行服务器的问题
- 从Express-graphql库中导入graphqlHTTP方法,帮助我们进行配置
- 从graphql库中导入buildSchema方法来定义数据模式(我们允许客户访问哪些数据)。
- 现在定义一个空的数据模式
- 现在定义一个空的根,但这将被用来定义我们的 调解器或者说我们选择如何处理数据,以便将其发送到客户端。
- 设置 CORS,不需要额外的配置
- 定义我们将用于**"/graphql "**端点的配置,它将利用我们之前定义的模式、根解析器对象,以及我们将用于测试和与我们的数据进行可视化交互的游乐场。
为了启动服务器,你所需要做的就是执行 node server.js命令。然后你可以在你的浏览器中检查 "localhost:8080",在那里你就可以看到GraphiQL游乐场的运行,这是一种与你的数据/架构进行交互的可视化方式。
它看起来应该是这样的。
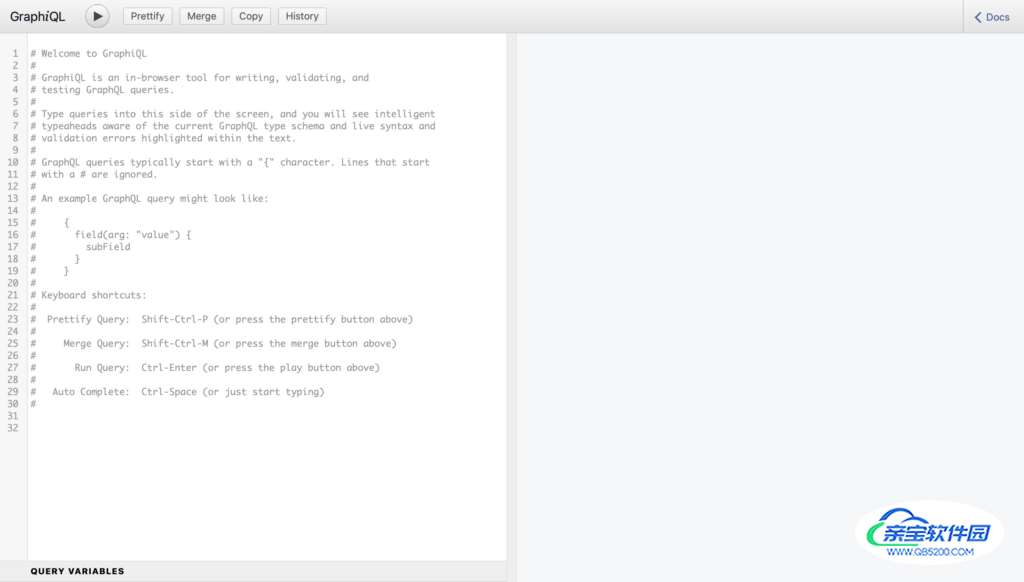
在浏览器中运行的GraphiQL
定义模式
现在我们已经把GraphQL设置好了,让我们看看用一些数据来填充我们的GraphQL模式。
为了简单起见,我们将使用一些更基本的模型,并在这些模型之间定义一个基本关系。我们将有一个作者模型和一个图书模型,它们将有以下模式:
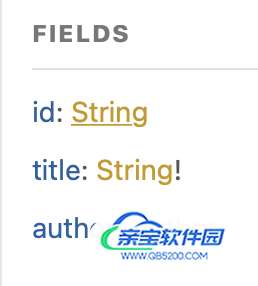
书籍模式:

作者模式
正如你从所附图片中看到的,我们将有2个基本模型,分别有3个和4个字段,在这里我们也定义了一对多的关系。这意味着一个作者可以写很多书,而一本书只能有一个作者。
这就是我们如何在代码中定义这些模型模式:
const schema = buildSchema(
`
type Query {
authors: [Author]
books: [Book]
}
type Author {
id: String
firstName: String!
lastName: String!
books: [Book]
}
type Book {
id: String
title: String!
author: Author
}
`
);我们还必须定义我们的父查询类型,它承载了所有检索数据的查询。在定义了父查询之后,我们将不得不为作者和书的模型定义模式。
你可以注意到一些字段类型后面的"!"符号,这表示一个字段是不可置空的。方括号("[]")围绕着一个类型,意味着它是一个数组。
嘲弄我们的数据
我们现在已经定义了模式,但还缺少两样东西:数据和解析器来解析查询的数据。
首先,让我们根据之前定义的模式来模拟我们的数据:
const mockedAuthors = [
{
id: '1',
firstName: "Mike",
lastName: "Ross",
},
{
id: '2',
firstName: "John",
lastName: "Miles",
books: [
{
id: '1',
title: "Book 1",
author: {
id: '2',
firstName: "John",
lastName: "Miles",
},
},
{
id: '2',
title: "Book 2",
author: {
id: '2',
firstName: "John",
lastName: "Miles",
},
},
],
},
];
const mockedBooks = {
'1': {
title: "Book 1",
author: mockedAuthors["2"],
},
'2': {
title: "Book 2",
author: mockedAuthors["2"],
},
};正如你可能注意到的,"Mike Ross "还没有写任何书,这不是一个问题,因为作者模式不需要在其数组内有任何书。此外,根本不需要定义一个书的数组,因为模式不需要它。然而,我们可以通过改变作者的书籍字段的类型来改变这种情况。[书籍]!这就要求至少有一个数组,不管是不是空的。
定义解析器
现在我们已经定义了模式和数据,我们可以通过定义解析器来完成,我们将使用这些解析器来实际处理如何将数据传递给客户端。
现在,我们只需要两个解析器:
- 一个用于解析作者的数据
- 一个用于解析图书数据
我们将在根中这样定义解析器:
const root = {
authors: () => mockedAuthors,
books: () => mockedBooks,
};正如你在上面的代码片段中所看到的,定义解析器的过程是非常直接的。会有一个作为查询名称的属性,这意味着通过具体查询 "author",都是小写字母,你会得到 "mockedAuthors "数据。
注意,我们还将函数作为值传递给属性,这一点很关键。
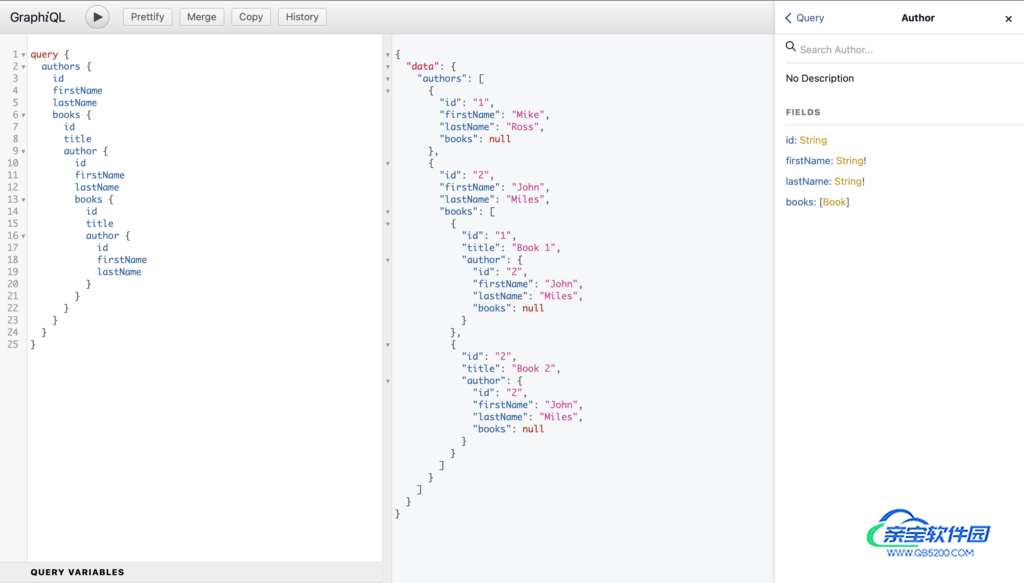
现在让我们测试一下所有的东西,这样我们就可以确保它按预期工作:
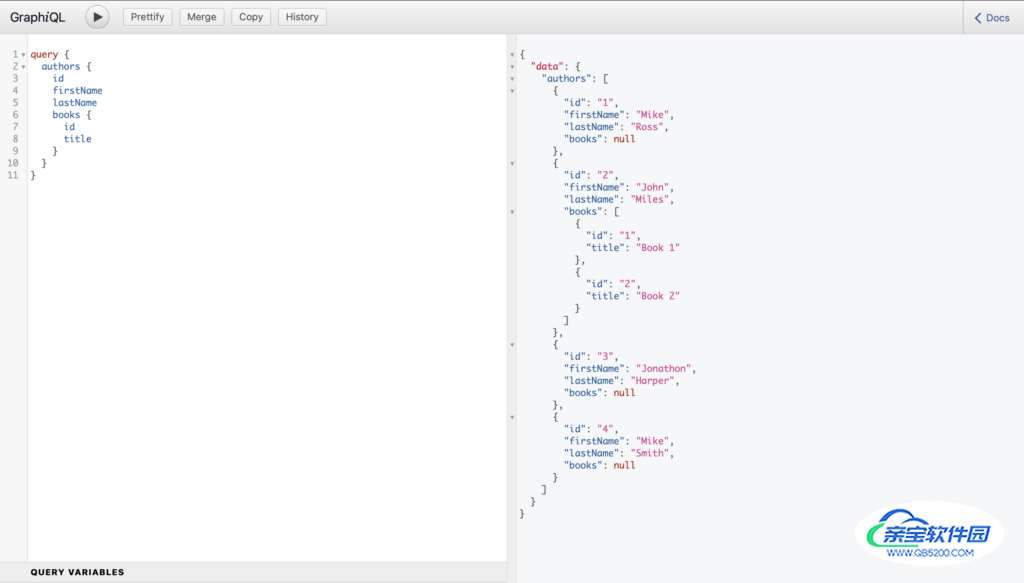
正如你所看到的,这一切都像预期的那样工作正常。我们使用GraphQL的特定术语,提到我们正在做一个查询,使用 "query "关键字,后面是我们希望查询的属性/类型/条目。在这种情况下,我们希望查询作者类型的所有属性,但只查询书籍类型的id和标题;我们跳过了作者字段。
因为我们已经模拟了数据,以包括书籍中的作者,我们可能会做像这样的循环查询。
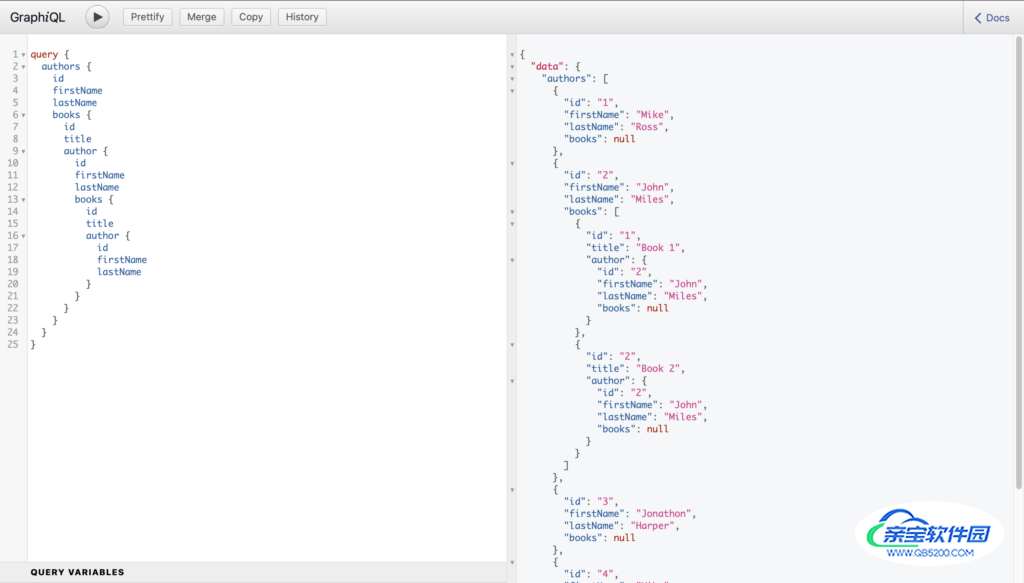
所以,你有了它。你可以看到设置GraphQL服务器并为其定义模式和解析器是多么容易。通过定义类型,你不仅有验证的地方,而且你还可能从你所选择的游乐场访问文档。
GraphiQL提供了一个右上方的小Docs菜单,它可以跳出来,向你展示在模式中定义的所有类型的文档。
GraphiQL中的GraphQL自我文档化模式
现在我们已经建立了使用查询检索数据的工作流程,我们还将看看如何使用突变来修改已有的数据。
定义突变
当我们使用查询来检索数据时,我们使用突变来创建、修改或删除现有数据。
假设我们要创建一个新的作者条目,我们要做的就是定义一个新的父 "突变"类型,该类型将拥有我们在整个系统中可能使用的突变字段。在那之后,我们必须为它定义解析器,然后就可以了。这将是我们需要做的所有事情。
下面的代码片段应该说明最终的server.js文件具有创建一个新的作者条目的能力:
const app = require("express")();
const cors = require('cors');
const { graphqlHTTP } = require("express-graphql");
const { buildSchema } = require("graphql");
const schema = buildSchema(
`
type Query {
authors: [Author]
books: [Book]
}
type Mutation {
createAuthor(
firstName: String!,
lastName: String!
): Author
}
type Author {
id: String
firstName: String!
lastName: String!
books: [Book]
}
type Book {
id: String
title: String!
author: Author
}
`
);
const mockedAuthors = [
{
id: '1',
firstName: "Mike",
lastName: "Ross",
},
{
id: '2',
firstName: "John",
lastName: "Miles",
books: [
{
id: '1',
title: "Book 1",
author: {
id: '2',
firstName: "John",
lastName: "Miles",
},
},
{
id: '2',
title: "Book 2",
author: {
id: '2',
firstName: "John",
lastName: "Miles",
},
},
],
},
];
const mockedBooks = {
'1': {
title: "Book 1",
author: mockedAuthors["2"],
},
'2': {
title: "Book 2",
author: mockedAuthors["2"],
},
};
const root = {
authors: () => mockedAuthors,
books: () => mockedBooks,
createAuthor: ({ firstName, lastName }) => {
const id = String(mockedAuthors.length + 1);
const createdAuthor = {
id,
firstName,
lastName
};
mockedAuthors.push(createdAuthor);
return createdAuthor;
}
};
app.use(cors());
app.use(
"/graphql",
graphqlHTTP({
schema,
rootValue: root,
graphiql: true,
})
);
app.listen(8080);所以,你有了它。你应该有一个工作的GraphQL服务器,你可以与之互动,以检索和修改或删除数据。
你可能会选择开始研究将解析器和模式类型分离到单独的目录和文件中,并在server.js文件中聚合它们,还有更多;在考虑扩展GraphQL应用程序时,选择是无穷无尽的。毕竟,这是它被建立的原因之一。
我希望你喜欢阅读这篇文章,并希望它能帮助你了解使用Node.js和Express设置GraphQL服务器的基本原理。
总结
加载全部内容