Java实现链栈的示例代码
m0_46897923 人气:0前言
线性表和栈都是我们常用的数据结构,栈可以看成一种特殊状态的线性表,栈的实现,一般都是使用线性表来实现,线性表分为顺序表和链表,使用线性表中的顺序表来实现栈时这种栈被称为顺序栈,相应的使用线性表中的链表来实现栈时这种栈被称为链栈,但是需要说明的是,虽然栈是一种特殊的线性表,但是栈和线性表并不是一种数据结构。这篇文章总结如何使用链式存储结构来实现栈,也就是链栈的实现。如果想要了解另一种栈(顺序栈)的实现请看这里:顺序栈的实现
一、实现过程
这部分总结链栈的实现过程,以及对应方法实现思路,这里提供一个栈的顶层接口IStack,用以声明栈中所应实现的方法,提供该接口不仅可供链栈使用,顺序栈也是可以使用的。下面链栈的实现通过实现ISstack接口来完成,详细步骤如下。
1.提供栈接口:IStack
该接口定义了栈必须实现的接口,有如下方法:
/**
* 该接口是:栈的顶层接口
* 他的实现类会有:顺序栈、链栈
*
* 栈:先入后出
*/
public interface IStack {
void clear();//清空方法
boolean isEmpty();//判空方法
int length();//栈深度方法
Object peek();//取栈顶元素并返回值,若栈为空,返回null
void push(Object object) throws Exception;//入栈操作,元素进入栈顶
Object pop();//将栈顶元素出站
}
2.提供结点类:Node
链栈的实现使用单链表来实现,因此我们需要提供一个结点的信息类,该结点是链表的存储单元,他包含有两个属性,一个是数据域用以存储数据,一个是指针域用以指向下一个结点,这两个属性这里都声明成了public,也可以声明成private,这样就需要使用get、set方法来操作这些属性了,这里为了方便使用public来声明这两个属性。
public class Node {
public Object object;
public Node next;
public Node(){
}
public Node(Object object){
this.object = object;
}
public Node(Node next){
this.next = next;
}
public Node(Object object,Node next){
this.object = object;
this.next = next;
}
@Override
public String toString() {
return "Node{" +
"object=" + object +
", next=" + next +
'}';
}
}
3.提供链栈的实现类:LinkedStack
使用链式存储结构实现的栈被称为链栈,这里使用单链表的数据结构来实现,该单链表的实现可以使用带头结点和不带头结点两种方式。两种实现没有太大区别,这里使用不带头结点的方式来实现。不带头结点那我们需要提供一个首结点,首结点需要在栈创建时被初始化,代码如下:
/**
*
* @author pcc
* @version 1.0.0
* @className LinkedStack:该栈类,使用链式存储结构实现,是链栈,这里使用单链表的方式实现
* @date 2021-04-20 16:32
*
* 栈的特点是先进后出:
* 因此我们可以使用头插法,每次在头部插入,出栈时只需获取链表的头结点即可。
*
* 链栈与顺序栈的区别:
* 顺序栈底层是数组,因此必须初始化一个数组的容量,也就是栈的容量,链栈则无需此操作
* 对比链栈和顺序栈的实现,可以发现入栈和出战方法的时间复杂度都是O(1),效率上没有区别,但是顺序栈占用的空间会相对更多
* 一些,顺序栈是通过指针指向假设的栈顶,其他元素其实依然存在,但链栈的栈顶之前的元素会被垃圾回收,因此链栈的实现综合时间和
* 空间来看,更优秀一些。
*/
public class LinkedStack implements IStack {
//这是首结点
Node node;
public LinkedStack(){
node = new Node();
}
}
4.提供清空(clear)、判空(isEmpty)、栈深度(length)等方法
这些方法的实现都比较简单,都一起写了,链表的起始就是首结点,因此我们只需要将首结点的数据域与指针域置空即可实现链栈的清空。判空也只需要判断首结点的数据域是否有值即可。栈深度则需要遍历链表的长度了(也可以设置一个整型,每次入栈操作时整型加1,这里通过遍历实现)。
下面是三个方法的实现:
@Override
public void clear() {
node.next = null;
node.object = null;
}
@Override
public boolean isEmpty() {
return node.object==null?true:false;
}
@Override
public int length() {
if(node.object==null)
return 0;
int j= 1;
Node nodeNew = node;
while(nodeNew.next!=null){
j++;
nodeNew = nodeNew.next;
}
return j;
}
5.提供入栈的方法:push(Object object)
入栈方法当然就是将数据元素放入栈顶的操作了。首先我们应该知道对于链表每次获取链表首结点的时间复杂度是O(1),获取尾结点的时间复杂度是O(n),因此很明显我们使用链表作为栈的数据结构时,应该使用头插法来将数据存入链栈,这样我们每次插入的栈顶元素都在链表的开始位置,获取该结点的时间复杂度是O(1)。所以我们使用头插法实现数据的存储,代码如下:
@Override
public void push(Object object) throws Exception {
if(node.object==null){
node.object = object;
return;
}
//头插法
node = new Node(object,node);
}
6.提供获取栈顶元素方法:peek()
该方法只是获取栈顶元素的信息,并不会将该元素出栈,因为栈顶元素就是链表的首结点,因此我们只需要返回首结点的数据域即可,代码实现如下:
@Override
public Object peek() {
return node.object;
}
7.提供出栈方法:pop()
栈是一种先入后出的数据结构,每次出栈的只能是最后进入的数据元素,因此我们每次只需要将链栈的首结点出栈即可,代码实现如下:
@Override
public Object pop() {
if(node.object==null)
return null;
Node tem = node;
node = node.next==null?new Node():node.next;
return tem.object;
}
8.提供链栈的完整实现代码
/**
*
* @author pcc
* @version 1.0.0
* @className LinkedStack:该栈类,使用链式存储结构实现,是链栈,这里使用单链表的方式实现
* @date 2021-04-20 16:32
*
* 栈的特点是先进后出:
* 因此我们可以使用头插法,每次在头部插入,出栈时只需获取链表的头结点即可。
*
* 链栈与顺序栈的区别:
* 顺序栈底层是数组,因此必须初始化一个数组的容量,也就是栈的容量,链栈则无需此操作
* 对比链栈和顺序栈的实现,可以发现入栈和出战方法的时间复杂度都是O(1),效率上没有区别,但是顺序栈占用的空间会相对更多
* 一些,顺序栈是通过指针指向假设的栈顶,其他元素其实依然存在,但链栈的栈顶之前的元素会被垃圾回收,因此链栈的实现综合时间和
* 空间来看,更优秀一些。
*/
public class LinkedStack implements IStack {
//这是首结点
Node node;
public LinkedStack(){
node = new Node();
}
@Override
public void clear() {
node.next = null;
node.object = null;
}
@Override
public boolean isEmpty() {
return node.object==null?true:false;
}
@Override
public int length() {
if(node.object==null)
return 0;
int j= 1;
Node nodeNew = node;
while(nodeNew.next!=null){
j++;
nodeNew = nodeNew.next;
}
return j;
}
@Override
public Object peek() {
return node.object;
}
@Override
public void push(Object object) throws Exception {
if(node.object==null){
node.object = object;
return;
}
//头插法
node = new Node(object,node);
}
@Override
public Object pop() {
if(node.object==null)
return null;
Node tem = node;
node = node.next==null?new Node():node.next;
return tem.object;
}
}
二、测试链栈的相应方法
第一部分已经详细描述了链栈的实现过程,下面就来测试下这些方法是否可以正常使用吧。
1.测试入栈和出栈
创建一个测试类,然后往栈中插入五个数据元素,并依次出栈,若是出栈顺序和入栈顺序相反则说明是正确的了,测试结果如下图:

可以看见输出和输入顺序是相反的,结果满足先入后出的预期。说明入栈与出栈的操作没有问题。
2.验证获取栈顶元素方法peek、栈深度方法length、清空方法clear
还是往栈里面放入原先的五个元素,然后栈顶元素应该是“李四5”,长度应该是5,第二次长度应该是0,如果输出内容是这些说明栈的实现就没有问题了,结果见下图:
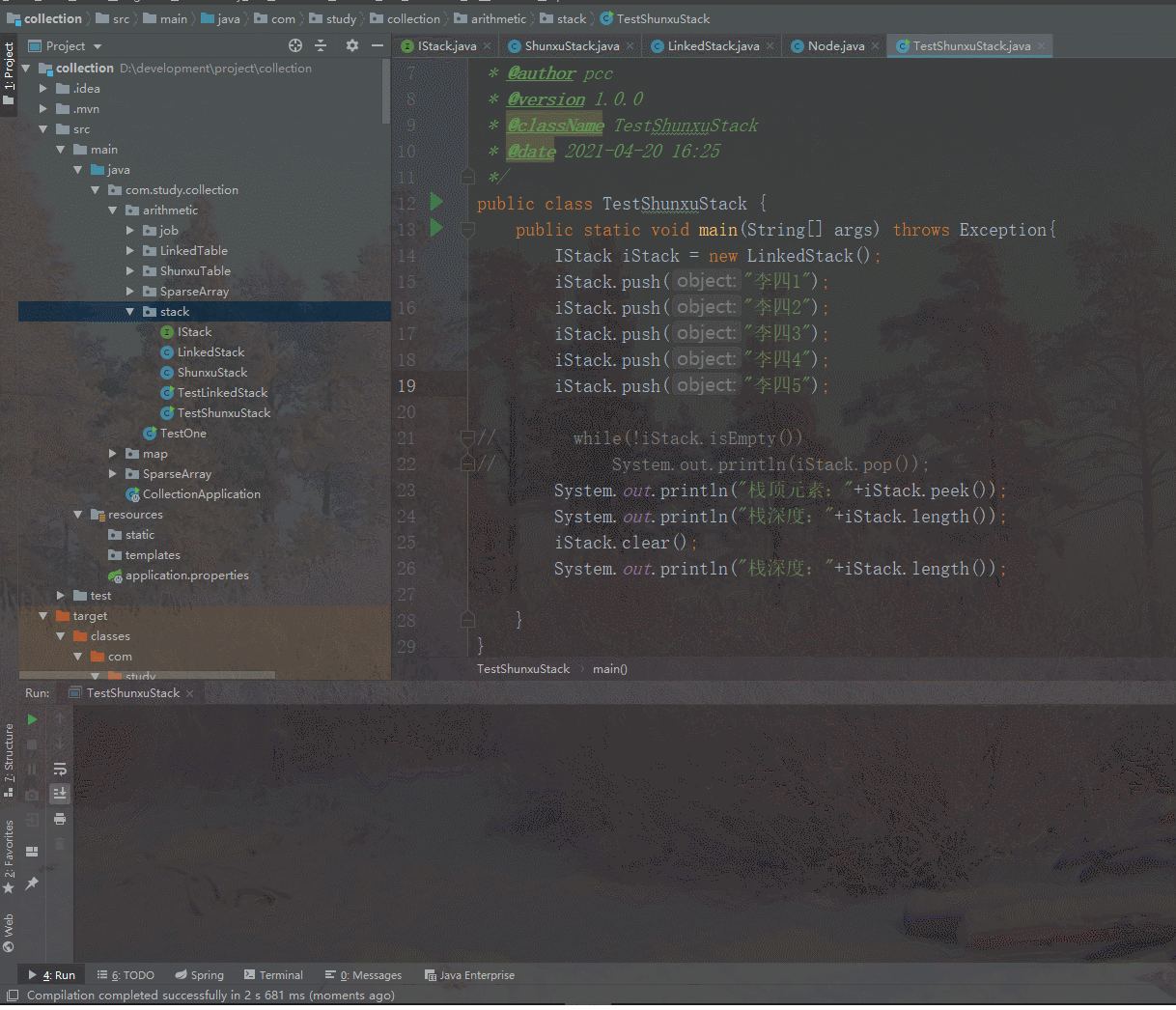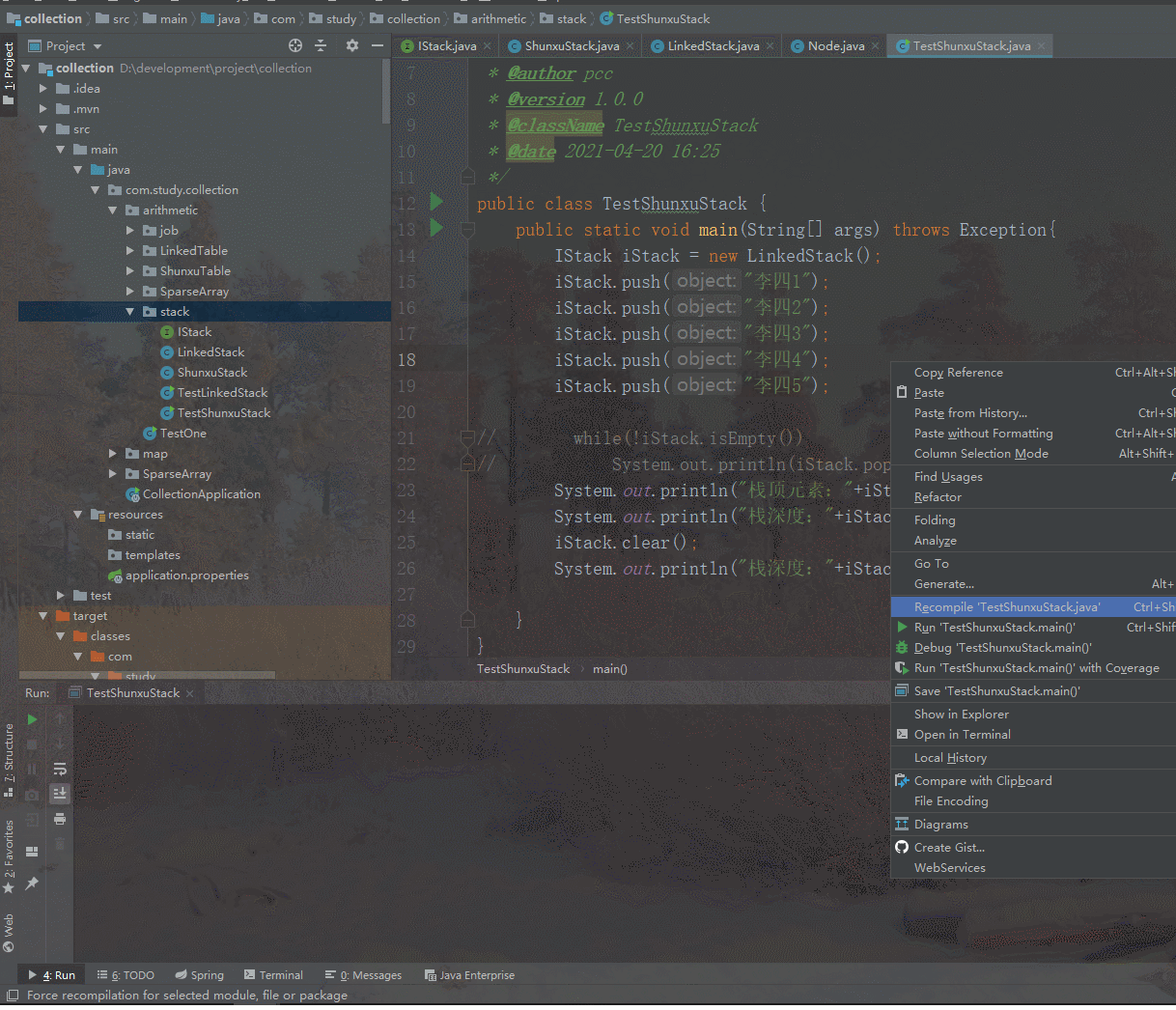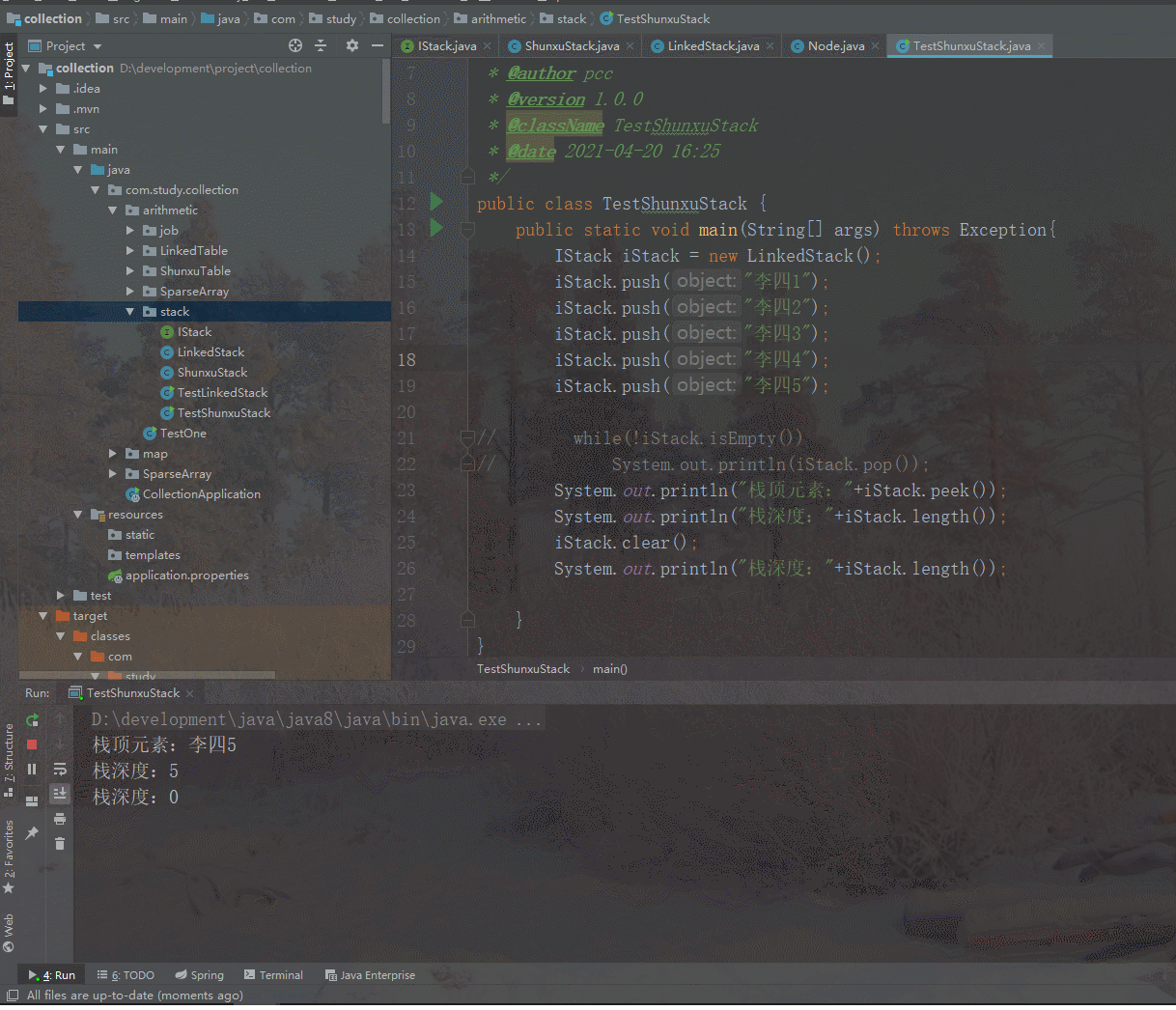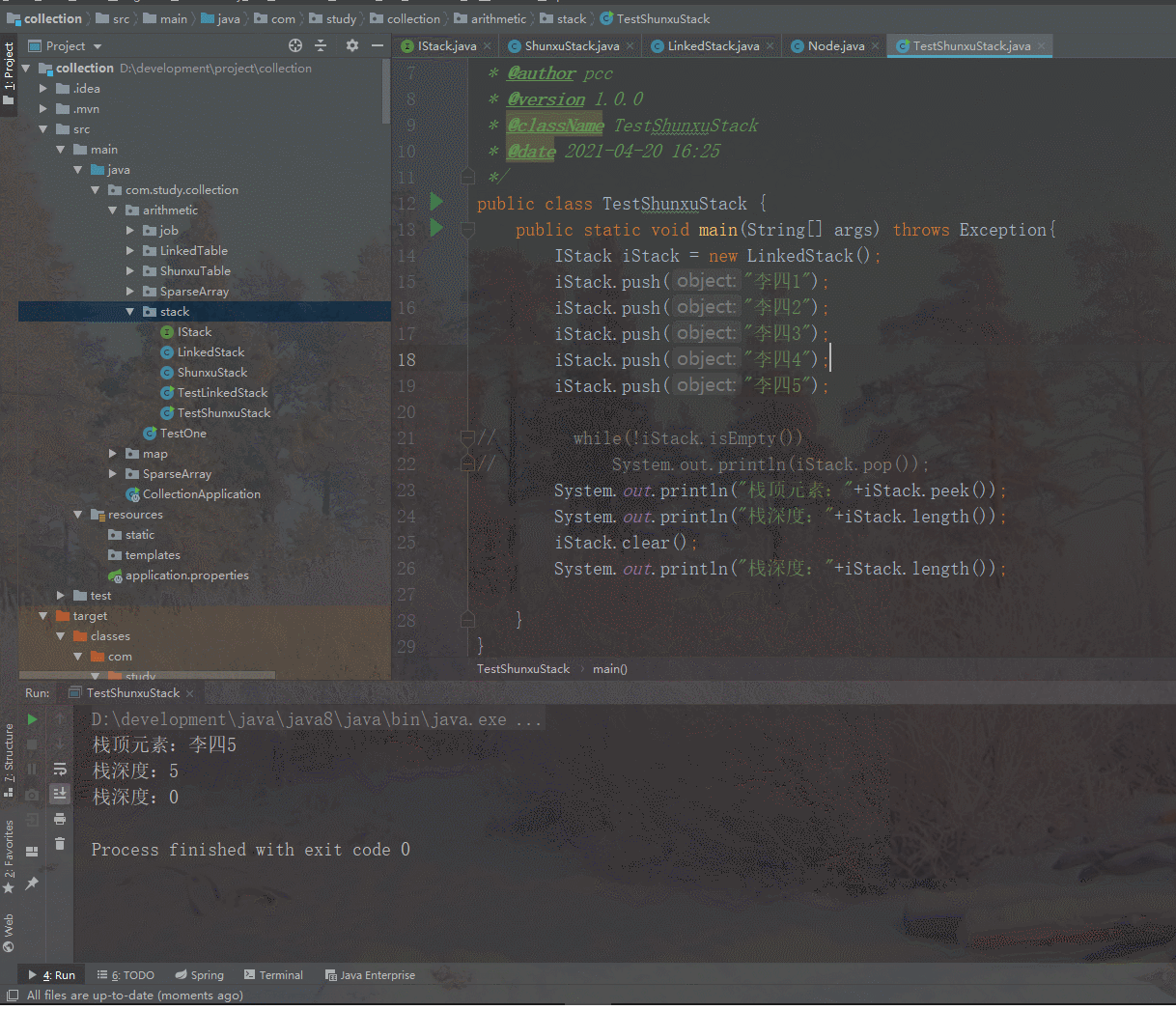
从输出结果可以看到,这些方法实现并没有问题,到这里栈常用的所有方法就已经都实现了,方法的实现都很简单,并没有有难度的地方。
三、总结
链栈即使用链式存储结构实现的栈,其实这里的链栈就是一个特殊的单链表,一种限制了只能在首结点插入和删除的单链表。这也是链表的本质,无论是在何种语言中栈的实现要么是使用顺序表要么是使用链表。无论使用哪种方法实现其实都很简单。
1.顺序栈与链栈的区别
顺序栈与链栈作为两种不同的栈的实现,他们肯定是有区别的,我们首先对比下入栈的操作,顺序栈的入栈操作是直接根据头指针将数据加入到数组指定的下标位置,链栈的入栈则是直接在首结点插入,他们的时间复杂度都是O(1),那么再对比下出栈的操作,顺序栈是通过头指针直接拿到下标为头指针的数组元素,链栈则是直接将链表的头部删除返回,他们的时间复杂度也都是O(1),因此在入栈和出栈的操作上他们的性能并没有什么区别,其他的区别还是要看不同的实现,若是实现的顺序栈每次出栈后不删除栈顶以后的元素,则顺序栈会占用更多的空间,因为链栈每次出栈后他的数据元素与GC ROOTS就失去了连接,下次触发GC时就会回收相应内存。这种情况顺序栈会占用更多的空间,链栈则更少,但是若是每次出栈时将顺序栈头指针以后的数据元素删除,就不会有这种区别了,所以综合来说顺序栈与链栈在入栈和出栈的操作上性能没有区别,但是其他场景的性能消耗,比如空间复杂度上则需要看顺序栈与链栈的具体实现来定。
加载全部内容