C语言链表案例学习之通讯录的实现
EMCred 人气:0一、通讯录需要实现的功能
1,通讯录可以存储编号,联系人的姓名,电话号码和家庭住址。
2,通讯录最基本的功能是添加联系人,用户可以随时添加联系人。
3,通讯录可以展示已经添加的所有联系人。
4,通讯录中用户可以根据联系人的姓名删除对应通讯录中的信息。
5,通讯录中姓名可以重复,所以为了删除准确的信息,需要实现按位置删除的功能。
6,通讯录中用户可以根据联系人的姓名找到联系人在通讯录中的信息,因为联系人可以重名,所以如果有重名的联系人的时候就需要返回两个或两个以上的联系人信息到一个查找表单中。
7,通讯录中用户可以根据通讯录的位置修改该位置的联系人信息,而修改这样的功能就只需要按照位置来进行修改,不需要再按照姓名进行修改,因为存在重名的情况,并且可以根据返回的表单看到具体的联系人位置,所以就不需要再 设计像按照名字进行修改这样冗余的功能了。
8,通讯录可以按照位置插入联系人
二、项目目的
制作本项目是为了将所学到的链表的知识进行巩固学习,做到学以致用,并通过做这样的小项目来增强理解开发,算法和C语言的指针,结构体等知识,同时收获开发经验,项目重点是能够使用链表的知识做出的小项目,所以该项目不会考虑到实现数据持久化的操作和GUI编程,只是基于DOS的命令行程序。
三、项目开发
开发IDE:Visual Studio 2019
IDE注意:
1,在该IDE中不能够直接使用scanf()函数,因为它可能会存在一些不安全的因素,所以在该IDE中使用的是scanf_s()函数,但是scanf和scanf_s函数具有本质的区别,并且scanf_s函数只能在该IDE中使用,不广泛,所以还是推荐使用scanf()函数,为了能正常使用scanf()函数,需要将声明#define _CRT_SECURE_NO_WARNINGS放在项目的最顶部。
2,为了更方便的开发该项目,所以使用了一些c++的库函数,所以为了能够正确运行程序,建议将后缀改为.cpp,其实c++是c的升级版本,解决了c不能面向对象开发的模式,它的编译器既可以运行.c的程序也可以运行.cpp的程序,但是.c的编译器是不能够运行.cpp的程序的,它并不能识别一些.cpp的源码。
首先,根据需求,选择合适的数据结构,这里选择的数据结构是链表为主体,采用带有头结点的单链表的形式,通过传入指向头结点的指针进行添加结点,遍历结点,删除结点,插入结点等对结点的操作,这样每次对链表进行操作就只需要传入指向头结点的指针就可以了,可以这样理解:
当程序运行在内存中的时候,首先先使用一个指针指向一个头结点
将该指针传入到添加结点的函数中,在该函数中通过指针从头结点开始遍历,使用头插法或尾插法,将生成的结点插入到头结点之后
然后再次传入指向头结点的指针到添加结点的函数,此时该链表已经有两个结点,头结点和一个结点,内部函数使用指针进行遍历,然后添加结点,形成头结点为起点的后面带有两个结点的单向链表
依次如此....
理解这里最重要的是对于指针的理解
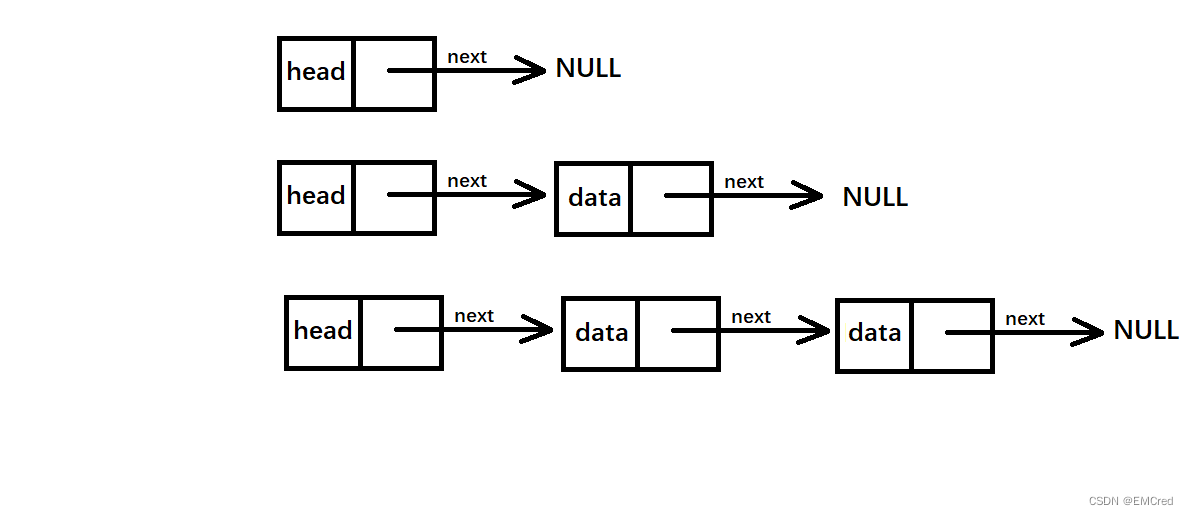
然后我们根据需要在通讯录中的内容可以存储编号,联系人的姓名,电话号码和家庭住址定义一个结构体,如下:
typedef struct Node {
Number num;//编号
Name name[23];//联系人姓名
Phone phone[33];//联系人电话
Addr addr[50];//联系人地址
struct Node* next;//next指针
}LNode;在这里需要考虑到的问题是对于编号的实现,编号可以在程序中由程序自主的实现,也就是在程序中可以定义一个全局变量number,并且赋初值为0,当调用添加结点的函数时,number自增并将number的值的赋给结构体成员num,但是它只能够不断的自增,当调用删除功能时,它的序号就会变得混乱,比如,现在已经添加了5个联系人,编号分别为1,2,3,4,5,如果删除编号为3的联系人的话,那么此时通讯录中的编号只剩下1,2,4,5,这样就会造成编号无序的情况,就没有意义也不便于管理操作。
如果编号在添加结点的时候由用户输入实现的话,对于用户来说可能会增加操作的负担,同时也不便于管理,可能它会无序甚至是重复。
所以最后可以解决的方式就是将编号不作为结构体成员的变量而是作为功能函数体中的一部分,也就是说我们传入头结点之后添加结点形成的单链表,如果要将信息输出到屏幕上时,可以定义一个指针指向单链表的首元结点并定义一个num为1的计数器,指针遍历到的个数就是计数器上的数字,这样如果删除了某个结点,它都会重新遍历一次,这样编号就是有序的,也就是说在打印联系人名单的函数中每次传入头结点都需要重新遍历一下,编号由函数中的num给出,所以此时重新修改结构体为:
typedef struct Node {
Name name[23];//联系人姓名
Phone phone[33];//联系人电话
Addr addr[50];//联系人地址
struct Node* next;//next指针
}LNode;然后定义函数printNode(Node* head)用来打印通讯录的名单,这里可以更好的理解如何解决编号的问题
void printNode(Node* head)
{
Node* move;
move = head->next;
int num = 1;
printf("================================通讯录页面=============================\n");
while (move)
{
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
printf("编号:%d 姓名:%s 电话:%s 住址:%s\n", num, move->name, move->phone, move->addr);
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
move = move->next;
num++;
}
printf("================================通讯录页面=============================\n");
}接下来,我们来定义完整的链表实现:
首先,可以定义一个函数Node* initList()用来初始化链表,也就是创建一个头结点并让它的指针域指向NULL,定义一个指针函数,该指针函数返回一个指向头结点的指针。
Node* initList()
{
Node* head;
head = (Node*)malloc(sizeof(Node));
head->next = NULL;
return head;
}然后,定义一个函数用来添加联系人也就是创建结点并使用头插法添加到单向链表中,此时我们需要传入指向头结点的指针。
void addListNode(Node* head)
{
Node* node;
node = (Node*)malloc(sizeof(Node));
printf("请输入联系人信息:\n");
printf("姓名:");
scanf("%s", &node->name);
printf("电话号码:");
scanf("%s", &node->phone);
printf("家庭地址:");
scanf("%s", &node->addr);
//使用头插法将结点链接到头结点之后
node->next = head->next;
head->next = node;
if (head->next != NULL) {
printf("添加联系人成功\n");
}
else {
printf("添加联系人失败\n");
}
}此时,可以在主方法中进行测试,此时已经能够打印出三个联系人了
int main()
{
Node* head;
head=initList();
addListNode(head);
addListNode(head);
printNode(head);
return 0;
}我们已经实现了通讯录的存储要求,添加联系人和打印出通讯录的联系人信息了。

此时我们会考虑到如果该通讯录为空的话,我们直接进行打印可能会造成nullptr,所以需要实现一个判断表空的函数,该函数返回bool值便于调用判断布尔类型。
bool isempty(Node* head)
{
if (head->next == NULL) {
return false;
}
else {
return true;
}
}此时在打印联系人目录的函数中使用该函数在函数的最开始进行判断,并在main中进行测试
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
接下来需要实现的是通讯录的其他功能。
首先实现用户可以根据联系人的姓名删除对应通讯录中的信息,根据联系人的姓名删除对应通讯录中的信息,我们可以想到,联系人的姓名是可以重复的,所以在删除时需要判断是否有重名的情况,所以可以先实现第6个需求,也就是通讯录中用户可以根据联系人的姓名找到联系人在通讯录中的信息,因为联系人可以重名,所以如果有重名的联系人的时候就需要返回两个或两个以上的联系人信息到一个查找表单中。
首先我们知道该功能是通过用户输入联系人的姓名也就是字符串然后在链表中找到相应字符串的位置进行返回,那么我们就需要实现一个字符串匹配的函数,它应当返回一个bool类型的值,当指针在链表中不断遍历并取出联系人的姓名进行比较直到找到这个联系人为止也就是该函数返回false的时候循环结束,所以可以定义一个字符匹配函数bool isBatch(Name n1[], Name n2[]);它的具体实现如下:
bool isBatch(Name n1[], Name n2[])
{
Name* n11, * n22;//定义两个char类型的指针
n11 = n1;//让n11指向字符串n1的首地址
n22 = n2;//让n22指向字符串n2的首地址
int num1 = 1;//定义长度器用来计量n1的长度
int num2 = 1;//定义长度器用来计量n2的长度
//定义两个长度器的原因是如果是n1:NUM,n2:NUM2的话,没有计数器的情况下当跳出循环后它依然是返回true的
while (1)
{
if (*n11 == *n22)
{
n11++;
n22++;
num1++;
num2++;
if (*n11 == '\0' && *n22 == '\0') {
break;
}
}
else {
return false;
}
}
if (num1 != num2) {
return false;
}
return true;
}然后我们需要返回联系人在链表中的位置通过再打印查找单的函数中遍历打印出信息,联系人可能重名,所以位置可能会返回多个,一个或者是无联系人的情况,因此这个返回位置的函数可以想到使用返回一个int数组的方式来操作,在C语言中如果想要返回数组的话需要返回的是指向这个数组的指针,也就是说C语言不能够直接就返回一个数组类型的数据,所以可以定义一个函数int* lookupByname(Node* head, Name name[]);传入头结点和输入的名字,它的具体实现如下:
int* lookupByname(Node* head, Name name[])
{
Node* target;//定义一个目标指针,该目标指针是用来获取每一个结点中的name并与输入的name进行比较
target = head->next;//让其指向第一个结点
int* summary = NULL;//定义一个指向返回数组的指针
summary = (int*)calloc(NUM, sizeof(int));//该指针指向一片大小为NUM的int类型的数组,该数组中所有值为0
int loc = 1;//获取位置从1开始,放在所申请的数组中
int numd = 0;//数组的下标
while (target)//遍历完整个链表
{
if (isBatch(target->name, name))//如果匹配
{
summary[numd] = loc;//位置放入数组
numd++;//只要放入numd就会加1,所以只要有一个联系人numd是1不是0
}
target = target->next;
loc++;
}
if (numd == 0) {//如果最后遍历完整个链表numd还是0就说明没有这个人
loc = -1;//让位置为-1
summary[0] = loc;
}
return summary;//返回指向整型数组的指针
}最后,我们来实现遍历打印出查找单的函数void printsMenu(Node* head, int* loc);传入链表的头结点和指向整型数组的指针,它的具体实现如下:
void printsMenu(Node* head, int* loc) {
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
Node* ptr;//定义一个指针用来获取位置并打印信息
ptr = head->next;
int num = 1;//定义位置寻找器用来找到指定的位置
printf("================================查找人汇总=============================\n");
for (int i = 0; i < NUM; i++)//遍历返回的数组,数组最大值为NUM其实不必要遍历到NUM,找到0的时候就可以跳出循环
{
if (loc[i] == -1) {//如果位置返回的是-1的话就表明无此人
printf(" 未查询到此人\n");
break;
}
while (num!=loc[i]) {//指针指到相应位置的结点
num++;
ptr = ptr->next;
}
//打印信息
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
printf("编号:%d 姓名:%s 电话:%s 住址:%s\n", num, ptr->name, ptr->phone, ptr->addr);
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
if (ptr->next == NULL) {//如果指针指到结尾就结束方法
return;
}
}
return;
}此时我们可以来测试一下这个功能,在main方法中:
int main()
{
Node* head;
Name name[23]="李白";
//添加两个李白,一个李白,没有李白和一个叫李白一个叫李白1进行测试
head=initList();
addListNode(head);
addListNode(head);
addListNode(head);
addListNode(head);
int* loc;
loc=lookupByname(head,name);
printsMenu(head, loc)
return 0;
}
接下来,既然现在已经能够按照姓名查到位置并输出了,那么实现用户可以根据联系人的姓名删除对应通讯录中的信息,这里可以考虑到姓名重名的话我们可以再设计一个按照位置删除联系人的函数,这样在按姓名删除的函数中需要通过返回的数组的大小提醒用户是否有重名的联系人,并提供建议如果有则建议结束函数然后采用按位置删除联系人的方式解决,没有就可以直接删除还有就是没有此联系人的情况,所以定义函数void deleteByname(Node* head, Name name[]),依然传入头结点和要删除的名字
void deleteByname(Node* head, Name name[])
{
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
Node* p, * q;//定义两个指针,p指针指向的是头结点,q指针指向的是首元结点
p = head;
q = head->next;
//当q查询到名字时就将q所指结点进行释放,然后将p所指结点也就是q所指结点的前一个结点连接到q所指结点的后一个结点
while (q)
{
if (q->next == NULL && !isBatch(q->name, name)) {//当遍历完整个链表并且最后一个结点的名字与输入的名字不符合的情况下结束遍历
printf("删除失败,未找到该联系人\n");
return;
}
if (isBatch(q->name, name))//如果遍历的过程中找到与输入的名字相对于的名字时
{
int* ptr = lookupByname(head, name);//调用查找名字位置的函数用于查找该名称是否有重名的情况
int li=1;//定义计数器记录有无重名的情况
for (int i = 0; i < NUM; i++) {
if (ptr[i] == 0) {
break;
}
li++;
}
if (li-1 == 1) {//计数器为1,也就是说只有一个名字无重名
printf("没有重名的联系人\n");
}
else {
printf("有%d个重名的联系人,建议查询后使用位置删除\n",li-1);
printf("按1选择继续删除,按2选择结束本次删除:");
int input;
scanf("%d", &input);
if (input == 1) {
goto loop;
}
else {
return;
}
}
break;
}
p = p->next;
q = q->next;
}
loop:
//删除结点的过程
p->next = q->next;
q->next = NULL;
free(q);
printf("删除联系人成功\n");
}然后在main方法写测试的用例:
int main()
{
Node* head;
Name deletename[23]="李白";
//添加两个李白,一个李白,没有李白和一个叫李白一个叫李白1进行测试
head=initList();
addListNode(head);
addListNode(head);
addListNode(head);
addListNode(head);
deleteByName(head,deletename);
return 0;
}添加两个李白的情况:

添加一个李白的情况:

没有李白的情况:

接下来,既然能够按照联系人的名称进行删除了,那么在重名的情况下,还需要一种删除的方法,也就是按照位置的删除方法,所以可以定义函数void deleteByLoc(Node* head, int loc),按照位置删除联系人,它的具体实现如下:
void deleteByLoc(Node* head, int loc)
{
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
Node* move,*q,*choic;
choic = head->next;//choic指向首元结点,用来判断链表中结点的数量,避免程序出现nullptr
//删除操作的两个指针
q = head;
move = head->next;
int num = 1;//位置计数器,一直自增到对应的位置loc
int t = 1;//链表数量器,用来遍历获取链表的结点数量
while (choic) {//获取链表的实际长度
if (choic->next == NULL) {
break;
}
choic = choic->next;
t++;
}
while (num!=loc&&move) {//寻找到要删除的位置
q = q->next;
move = move->next;
num++;
}
if (num >= t) {//如果要删除的位置比链表的长度都长就说明删除错误
printf("查询错误,已经超出已有人数上限,会造成程序异常\n");
return;
}
else {
q->next = move->next;
move->next = NULL;
free(move);
printf("删除成功\n");
}
}再次使用main方法进行测试:
int main()
{
Node* head;
int loc=1;
head=initList();
addListNode(head);
deleteByLoc(head,1);
return 0;
}
到目前位置,整个通讯录的功能已经完成了,接下来完成修改联系人的信息和插入新的联系人的功能,先完成修改联系人信息的功能,既然可以查找到重名的联系人,所以此时需要按照位置修改联系人信息,所以定义函数void modifyByName(Node* head, int loc),闯入头结点和需要修改的位置,在修改的时候,我们希望可以展示修改人原先的信息,有些算法的思想和按位删除联系人的思想一致,具体实现如下:
void modifyByName(Node* head, int loc)
{
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
Node* move, * choic;
choic = head->next;
move = head->next;
int num = 1;
int t = 1;
while (choic) {
choic = choic->next;
t++;
if (choic->next == NULL) {
break;
}
}
while (num != loc && move) {
move = move->next;
num++;
}
if (num > t) {
printf("位置错误,已经超出已有人数上限,会造成程序异常\n");
return;
}
else {
printf("找到联系人信息\n");
printf("正在检测联系人信息...........\n");
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
printf("编号:%d 姓名:%s 电话:%s 住址:%s\n", num, move->name, move->phone, move->addr);
printf("++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\n");
printf("按1键更改联系人信息,按2键不更改联系人信息并结束:");
int inputs;
scanf("%d", &inputs);
if (inputs==1)
{
int istrue;
do {
printf("请输入联系人信息:\n");
printf("姓名:");
scanf("%s", &move->name);
printf("电话号码:");
scanf("%s", &move->phone);
printf("家庭地址:");
scanf("%s", &move->addr);
printf("按1键确认更改,按2键重新更改:");
scanf("%d", &istrue);
} while (istrue!=1);
printf("修改联系人信息成功\n");
}
else {
printf("ERROR");
return;
}
}
}同样在main函数中进行测试
最后完成最后一个功能,按位置插入联系人,这个函数的意义不大,但是为了巩固链表的插入而设计的,定义一个函数void insertNodeByLoc(Node* head, int loc)算法的实现思路与按位删除的一致,只是找到后是将新的结点插入而已,具体实现如下:
void insertNodeByLoc(Node* head, int loc)
{
if (!isempty(head)) {
printf("检测到通讯录为空,请先添加联系人再进行操作\n");
return;
}
Node* p, * q,*m;
m = head->next;
p = head->next;
q = head;
int num=1;
int i=1;
while (m)
{
i++;
if (m->next == NULL) {
break;
}
}
while (num!=loc&&p) {
p = p->next;
q = q->next;
num++;
}
if (num >= i) {
printf("插入位置错误,已经超出已有数量上限,会造成程序异常\n");
return;
}
else {
Node* node;
node = (Node*)malloc(sizeof(Node));
printf("请输入联系人信息:\n");
printf("姓名:");
scanf("%s", &node->name);
printf("电话号码:");
scanf("%s", &node->phone);
printf("家庭地址:");
scanf("%s", &node->addr);
node->next = p->next;
p->next = node;
printf("插入成功\n");
}
}同样进行测试:

加载全部内容