Python selenium模块的安装和配置教程
IT工藤新一 人气:0一、selenium的安装以及简单应用
我们以谷歌浏览器的chromedriver为例
1、在Python虚拟环境中安装selenium模块
pip/pip3 install selenium
2、下载版本符合的webdriver
以chrome谷歌浏览器为例
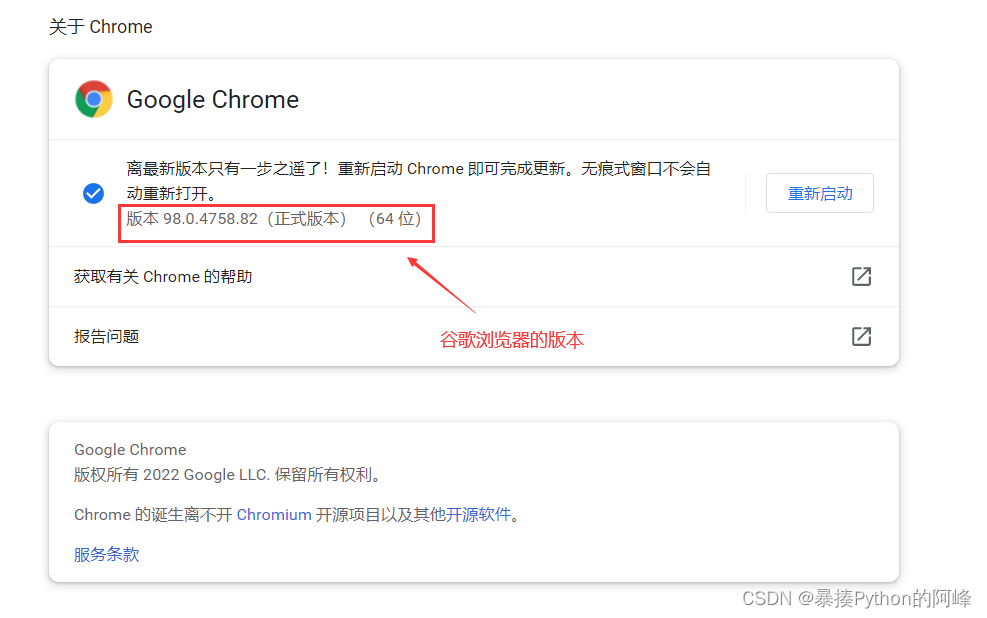
查看谷歌浏览器的版本
鼠标点击右上角的竖排的三个点,然后选择“帮助”,选择“关于 Google Chrome”,进去之后即可查看谷歌浏览器的版本
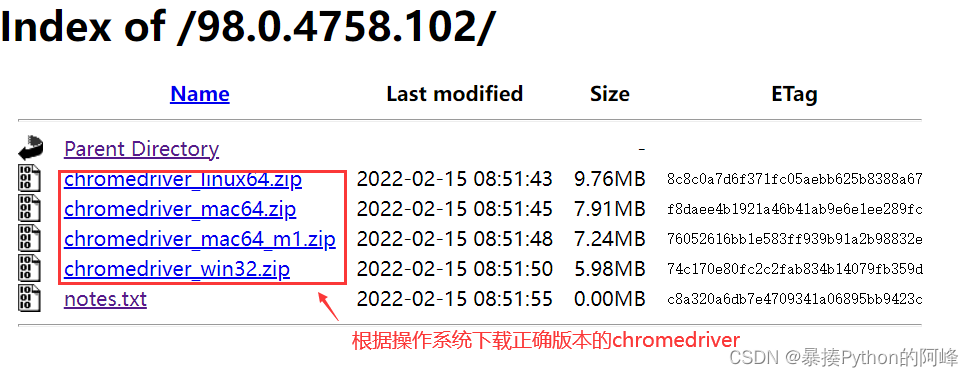
访问下载chromedriver网站
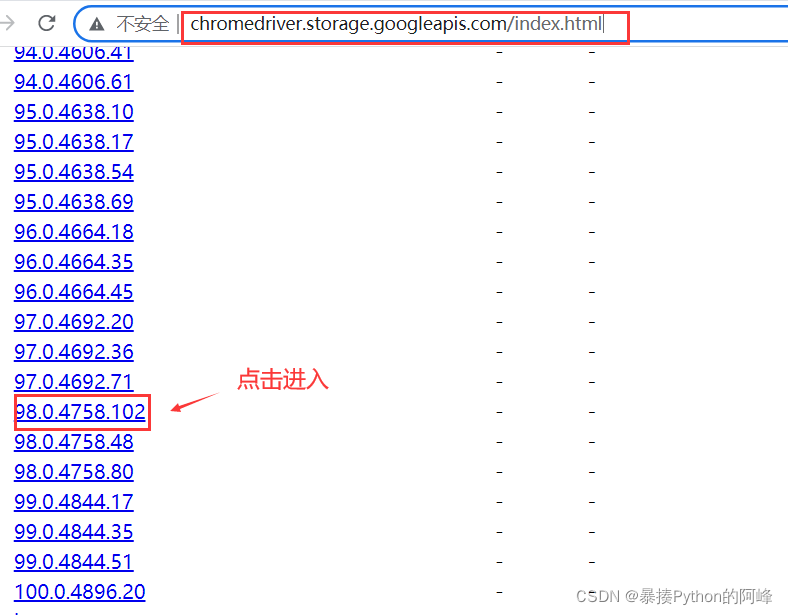
访问chromedriver下载地址,点击进入不同版本的chromedriver下载页面
点击notes.txt进入版本说明页面
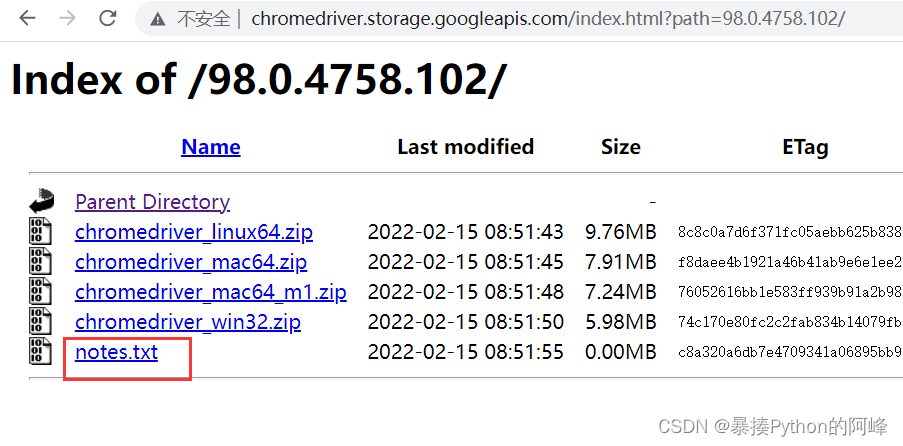
查看chrome和chromedriver匹配的版本

根据操作系统下载正确版本的chromedriver
解压压缩包后获取python代码可以调用的谷歌浏览器的webdriver可执行文件
- windows为 chromedriver.exe
- linux和macos为 chromedriver
chromedriver环境的配置
- windows环境下需要将 chromedriver.exe 所在的目录设置为path环境变量中的路径
- linux/mac环境下,将 chromedriver 所在的目录设置到系统的PATH环境值中
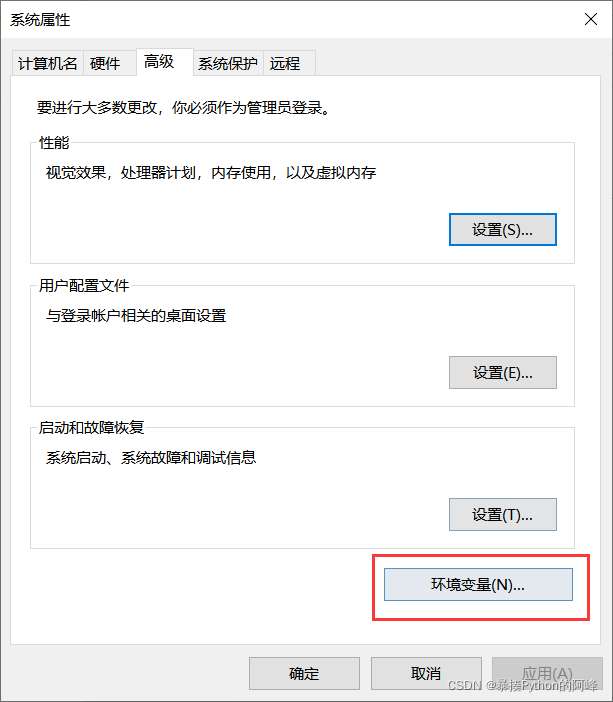
3、chromedriver环境配置的教程
windows环境下将 chromedriver.exe 所在的目录设置为path环境变量中的路径的过程
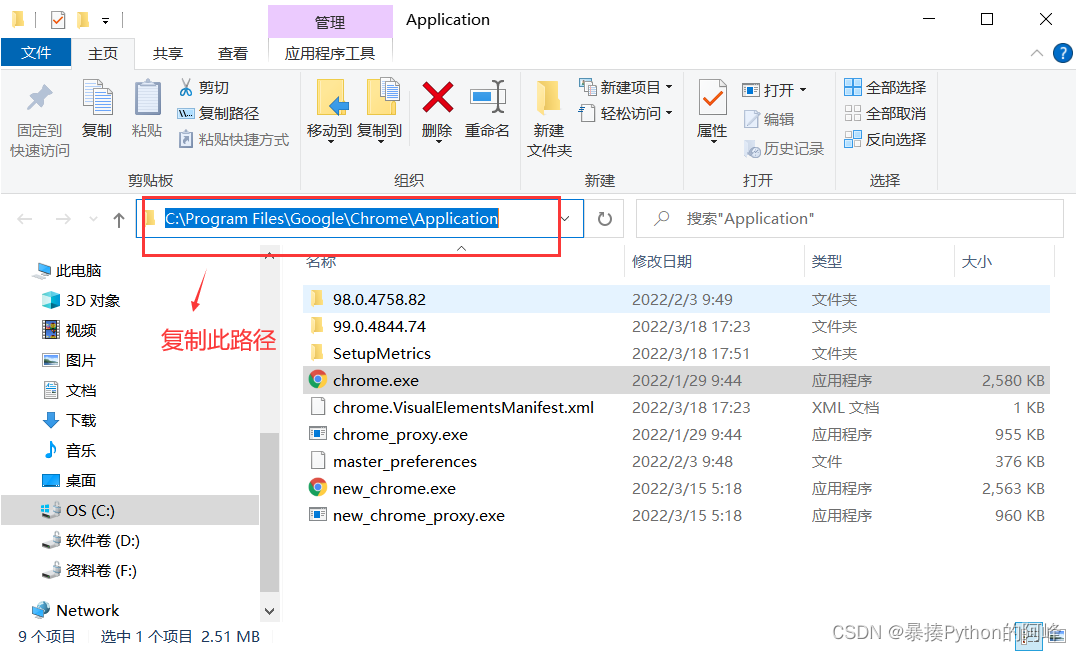
鼠标右键点击“Google Chrome” ,然后点击“打开文件所在位置”复制 chrome.exe 所在的文件路径
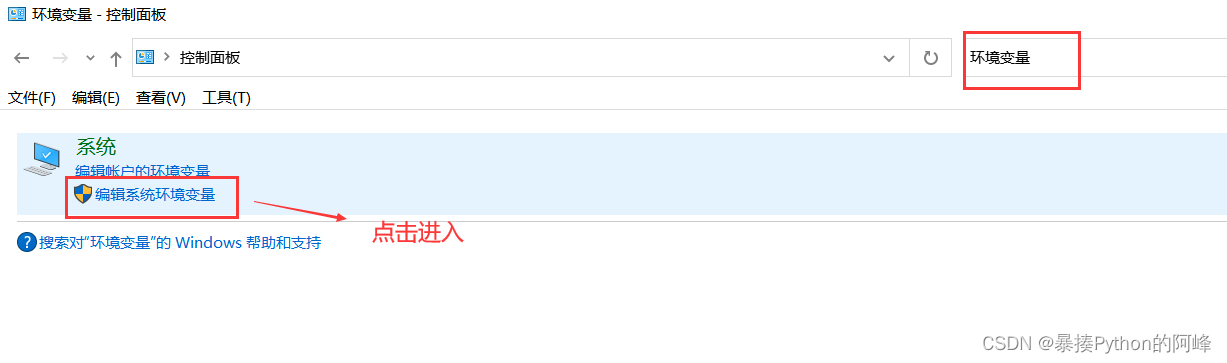
接着打开“控制面板” 搜索输入 “环境变量” 并搜索,然后点击 “编辑系统环境变量”
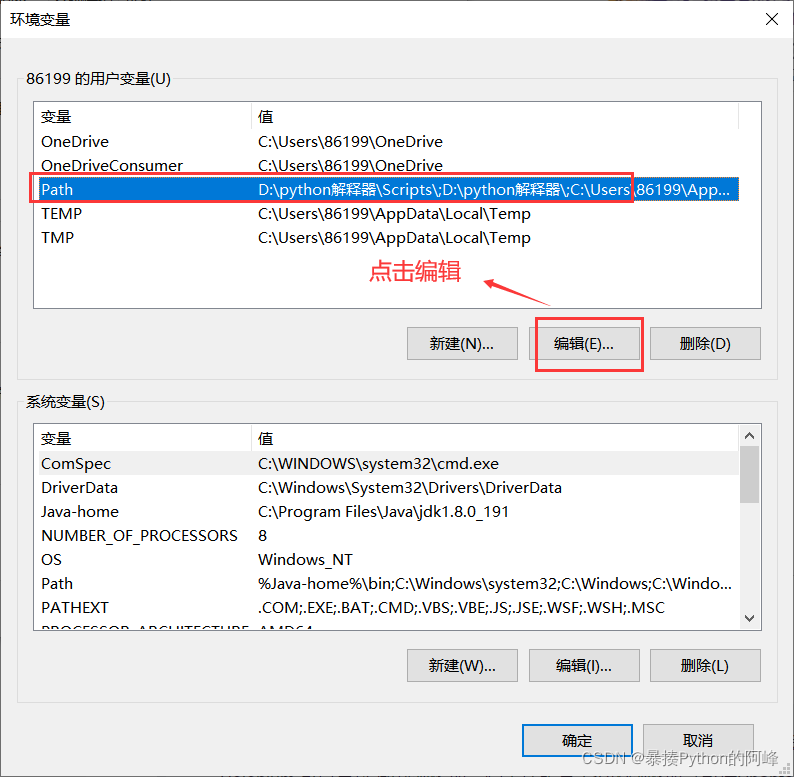
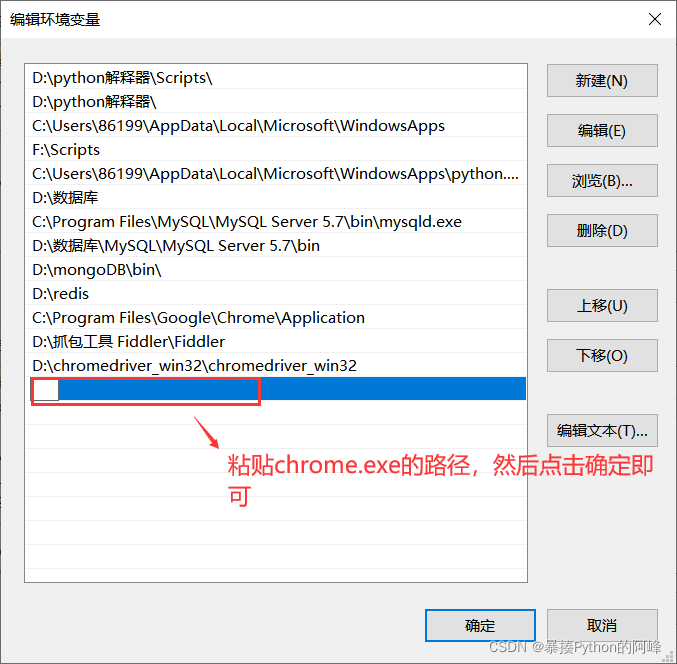
二、selenium的简单使用
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。
Selenium 可以直接调用浏览 器,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器),可以接收指令,让浏览器自动加载页 面,获取需要的数据,甚至页面截屏等。
我们可以使用selenium很容易完成之前编写的爬虫,接下来我们就来 看一下selenium的运行效果
接下来我们就通过代码来模拟百度搜索(展示效果)
import time
from selenium import webdriver
# 通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录。
# driver = webdriver.Chrome(executable_path='./chromedriver')
# 这里的chromedriver已经添加环境变量
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
time.sleep(3)
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击'百度搜索'
driver.find_element_by_id('su').click()
time.sleep(6)
# 退出浏览器
driver.quit()运行结果
webdriver.Chrome(executable_path='./chromedriver') 中executable参数指定的是下载好的
chromedriver文件的路径
driver.find_element_by_id('kw').send_keys('python') 定位id属性值是'kw'的标签,并向其中输入字符 串'python'
driver.find_element_by_id('su').click() 定位id属性值是su的标签,并点击
click函数作用是:触发标签的js的click事件
三、selenium提取数据
1、driver对象常用的属性和方法
在使用selenium过程中,实例化driver对象后,driver对象有一些常用的属性和方法
- driver.page_source 获取当前标签页浏览器渲染之后的网页源代码
- driver.current_url获取当前标签页的url
- driver.close() 关闭当前标签页,如果只个一个标签页则关闭整个浏览器
- driver.quit() 关闭浏览器
- driver.forward() 页面前进
- driver.back() 页面后退
- driver.screen_shot(img_name) 页面截图
示例
打印当前标签页的url
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
time.sleep(3)
# 打印当前标签页的url
print(driver.current_url)
driver.quit()运行结果:
2、driver对象定位标签元素获取标签对象的方法
在selenium中可以通过多种方式来定位标签,返回标签元素对象
| 方式 | 功能 |
|---|---|
| find_element_by_id | 返回一个元素 |
| find_element(s)_by_class_name | 根据类名获取元素列表 |
| find_element(s)_by_name | 根据标签的name属性值返回包含标签对象元素的列表 |
| find_element(s)_by_xpath | 返回一个包含元素的列表 |
| find_element(s)_by_link_text | 根据连接文本获取元素列表 |
| find_element(s)_by_partial_link_text | 根据链接包含的文本获取元素列表 |
| find_element(s)_by_tag_name; | 根据标签名获取元素列表 |
| find_element(s)_by_css_selector | 根据css选择器来获取元素列表 |
注意
find_element和find_elements的区别:
- 多了个s就返回列表,没有s就返回匹配到的第一个标签对象
- find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
by_link_text 和 by_partial_link_tex 的区别:全部文本和包含某个文本
以上函数的使用方法:
driver.find_element_by_id('id_str')
id_str是id值
示例
接下来我们就通过代码来模拟百度搜索(具体讲解)
首先我们先打开百度页面,然后点击网页检查 ,定位搜索框,可以看见搜索框的input标签的id值为kw
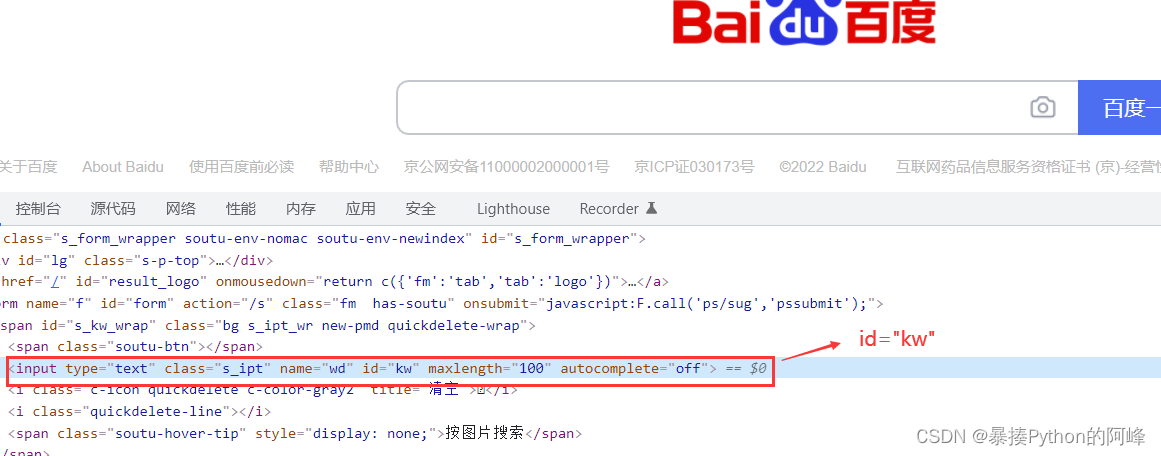
- 于是开始编写基础代码
- 通过driver.get()获取网页
- 通过find_element_by_id('kw')定位搜索框
- 通过.send_keys('python')向搜索框输入搜索信息
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
time.sleep(3)
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')再定位搜索按钮:“百度一下” ,其id值为su
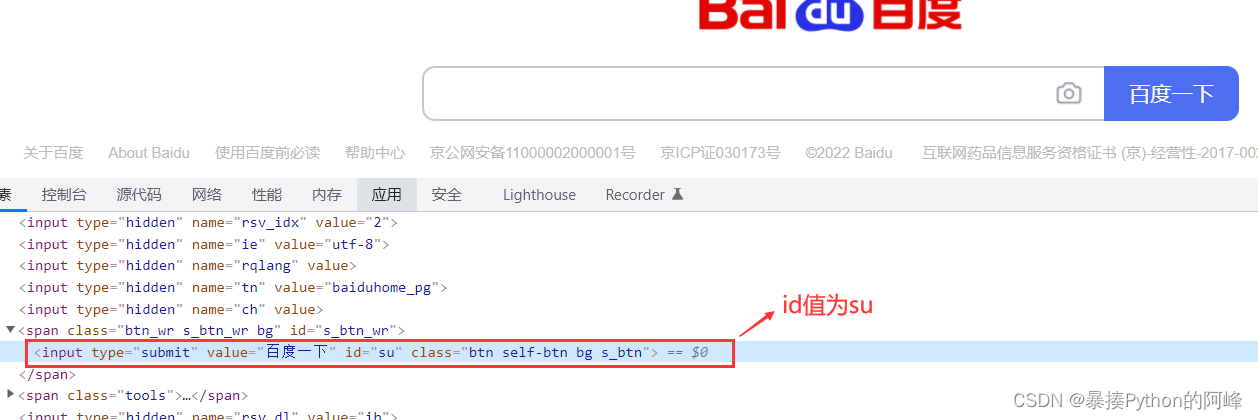
完善代码,通过 .click() 实现点击搜索
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
time.sleep(3)
# 在百度搜索框中搜索'python'
driver.find_element_by_id('kw').send_keys('python')
# 点击'百度搜索'
driver.find_element_by_id('su').click()
time.sleep(6)
# 退出浏览器
driver.quit()运行结果
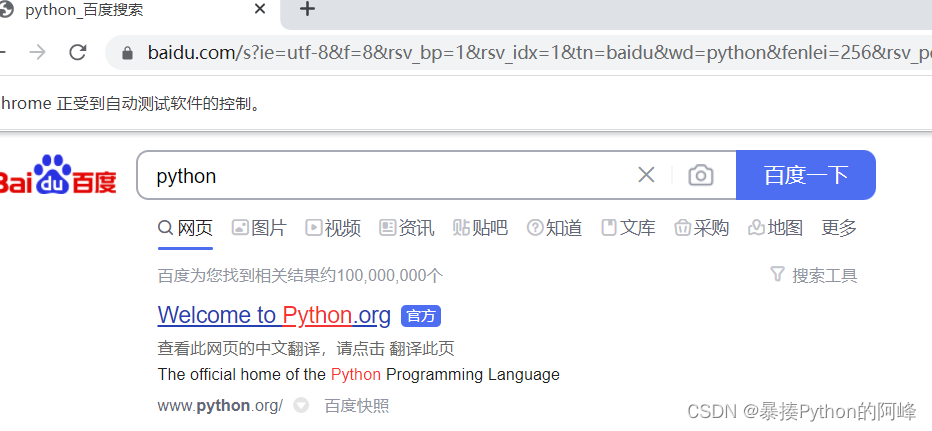
3、标签对象提取文本内容和属性值
find_element仅仅能够获取元素,不能够直接获取其中的数据,如果需要获取数据需要使用以下方法
对元素执行点击操作: element.click()
对定位到的标签对象进行点击操作
向输入框输入数据: element.send_keys(data)
对定位到的标签对象输入数据
获取文本: element.text
通过定位获取的标签对象的 text 属性,获取文本内容
获取属性值: element.get_attribute("属性名")
通过定位获取的标签对象的 get_attribute 函数,传入属性名,来获取属性的值
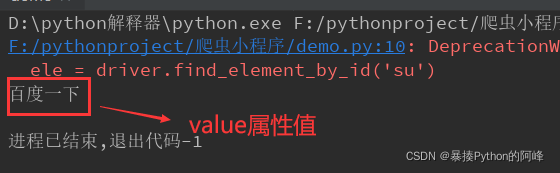
获取 “百度一下”搜索按钮的value属性值
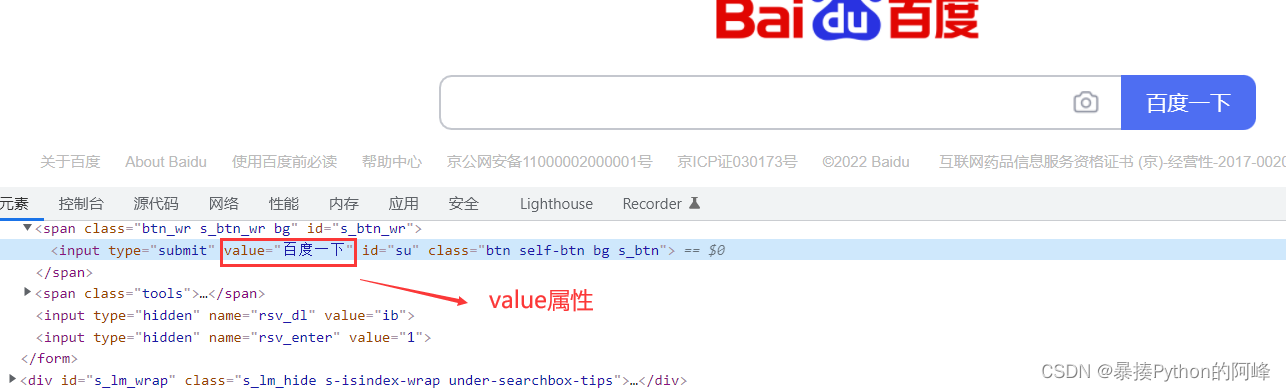
import time
from selenium import webdriver
driver = webdriver.Chrome()
# 控制浏览器访问url地址
driver.get("https://www.baidu.com/")
time.sleep(3)
# 点击'百度搜索',用ele变量接受获取的元素
ele = driver.find_element_by_id('su')
print(ele.get_attribute('value'))
time.sleep(6)
# 退出浏览器
driver.quit()运行结果
四、selenium无头模式
我们知道,当我们利用 dirver.get() 获取网页时会自动打开一个网页,但是有时候我们可能不需要通过打开浏览器获取数据,于是就可以通过给driver对象设置无头模式 。
# 给driver对象设置无头模式
op = webdriver.ChromeOptions()
op.add_argument('--headless')
driver = webdriver.Chrome(options=op)加载全部内容