Kotlin SharedFlow 缓存
fundroid 人气:0前言
Kotlin 为我们提供了两种创建“热流”的工具:StateFlow 和 SharedFlow。StateFlow 经常被用来替代 LiveData 充当架构组件使用,所以大家相对熟悉。其实 StateFlow 只是 SharedFlow 的一种特化形式,SharedFlow 的功能更强大、使用场景更多,这得益于其自带的缓存系统,本文用图解的方式,带大家更形象地理解 SharedFlow 的缓存系统。
创建 SharedFlow 需要使用到 MutableSharedFlow() 方法,我们通过方法的三个参数配置缓存:
fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): MutableSharedFlow<T>
接下来,我们通过时序图的形式介绍这三个关键参数对缓存的影响。正文之前让我们先统一一下用语:
- Emitter:Flow 数据的生产者,从上游发射数据
- Subcriber:Flow 数据的消费者,在下游接收数据
replay
当 Subscriber 订阅 SharedFlow 时,有机会接收到之前已发送过的数据,replay 指定了可以收到 subscribe 之前数据的数量。replay 不能为负数,默认值为 0 表示 Subscriber 只能接收到 subscribe 之后 emit 的数据:
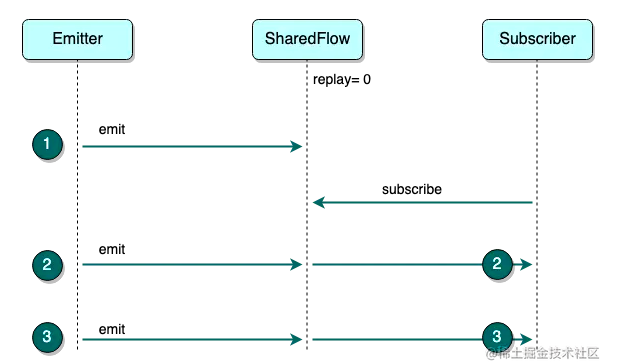
上图展示的是 replay = 0 的情况,Subscriber 无法收到 subscribe 之前 emit 的 ❶,只能接收到 ❷ 和 ❸。
当 replay = n ( n > 0)时,SharedFlow 会启用缓存,此时 BufferSize 为 n,意味着可以缓存发射过的最近 n 个数据,并发送给新增的 Subscriber。
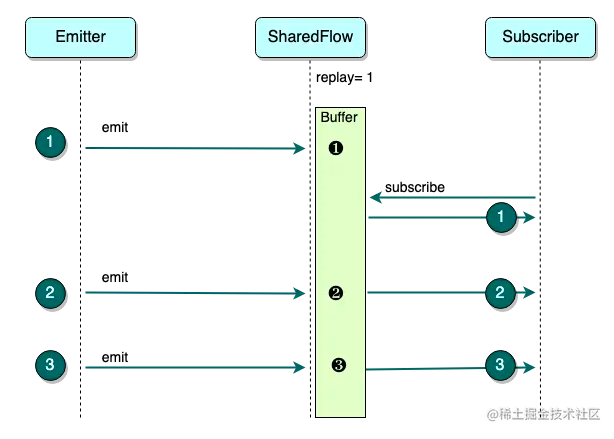
上图以 n = 1 为例 :
- Emitter 发送 ❶ ,并被 Buffer 缓存
- Subscriber 订阅 SharedFlow 后,接收到缓存的 ❶
- Emitter 相继发送 ❷ ❸ ,Buffer 缓存的数据相继依次被更新
在生产者消费者模型中,有时消费的速度赶不及生产,此时要加以控制,要么停止生产,要么丢弃数据。SharedFlow 也同样如此。有时 Subscriber 的处理速度较慢,Buffer 缓存的数据得不到及时处理,当 Buffer 为空时,emit 默认将会被挂起 ( onBufferOverflow = SUSPEND)
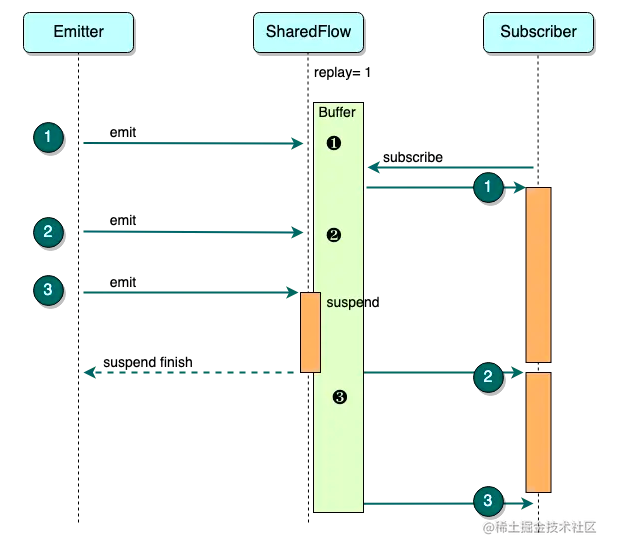
上面的图展示了 replay = 1 时 emit 发生 suspend 场景:
- Emitter 发送 ❶ 并被缓存
- Subscriber 订阅 SharedFlow ,接收 replay 的 ❶ 开始处理
- Emitter 发送 ❷ ,缓存数据更新为 ❷ ,由于 Subscriber 对 ❶ 的处理尚未结束,❷ 在缓存中没有及时被消费
- Emitter 发送 ❸,由于缓存的 ❷ 尚未被 Subscriber 消费,emit 发生挂起
- Subscriber 开始消费 ❷ ,Buffer 缓存 ❸ , Emitter 可以继续 emit 新数据
注意 SharedFlow 作为一个多播可以有多个 Subscriber,所以上面例子中,❷ 被消费的时间点,取决于最后一个开始处理的 Subscriber。
extraBufferCapacity
extraBufferCapacity 中的 extra 表示 replay-cache 之外为 Buffer 还可以额外追加的缓存。
若 replay = n, extraBufferCapacity = m,则 BufferSize = m + n。
extraBufferCapacity 默认为 0,设置 extraBufferCapacity 有助于提升 Emitter 的吞吐量
在上图的基础之上,我们再设置 extraBufferCapacity = 1,效果如下图:
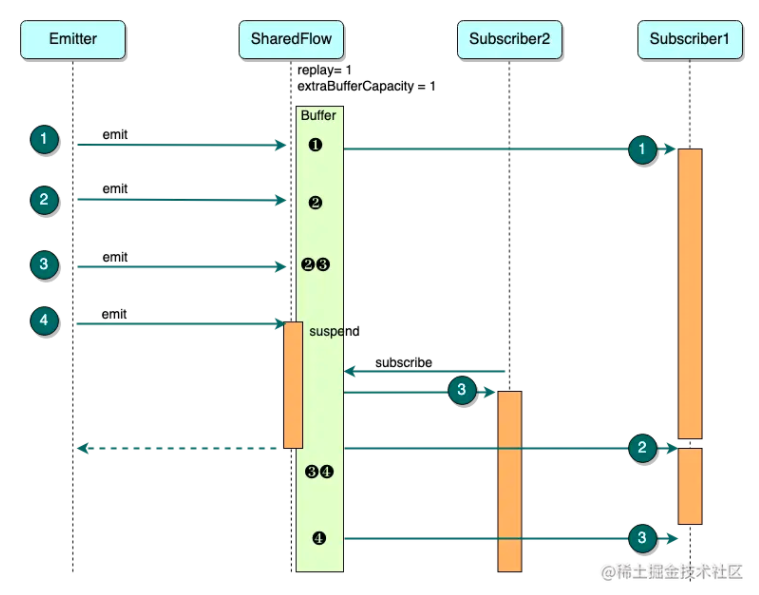
上图中 BufferSize = 1 + 1 = 2 :
- Emitter 发送 ❶ 并得到 Subscriber1 的处理 ,❶ 作为 replay 的一个数据被缓存,
- Emitter 发送 ❷,Buffer 中 replay-cache 的数据更新为 ❷
- Emitter 发送 ❸,Buffer 在存储了 replay 数据 ❷ 之上,作为 extra 又存储了 ❸
- Emitter 发送 ❹,此时 Buffer 已没有空余位置,emit 挂起
- Subscriber2 订阅 SharedFlow。虽然此时 Buffer 中存有 ❷ ❸ 两个数据,但是由于 replay = 1,所以 Subscriber2 只能收到最近的一个数据 ❸
- Subscriber1 处理完 ❶ 后,依次处理 Buffer 中的下一个数据,开始消费 ❷
- 对于 SharedFlow 来说,已经不存在没有消费 ❷ 的 Subscriber,❷ 移除缓存,❹ 的 emit 继续,并进入缓存,此时 Buffer 又有两个数据 ❸ ❹ ,
- Subscriber1 处理完 ❷ ,开始消费 ❸
- 不存在没有消费 ❸ 的 Subscriber, ❸ 移除缓存。
onBufferOverflow
前面的例子中,当 Buffer 被填满时,emit 会被挂起,这都是建立在 onBufferOverflow 为 SUSPEND 的前提下的。onBufferOverflow 用来指定缓存移除时的策略,除了默认的 SUSPEND,还有两个数据丢弃策略:
- DROP_LATEST:丢弃最新的数据
- DROP_OLDEST:丢弃最老的数据
需要特别注意的是,当 BufferSize = 0 时,extraBufferCapacity 只支持 SUSPEND,其他丢弃策略是无效的。这很好理解,因为 Buffer 中没有数据,所以丢弃无从下手,所以启动丢弃策略的前提是 Buffer 至少有一个缓冲区,且数据被填满
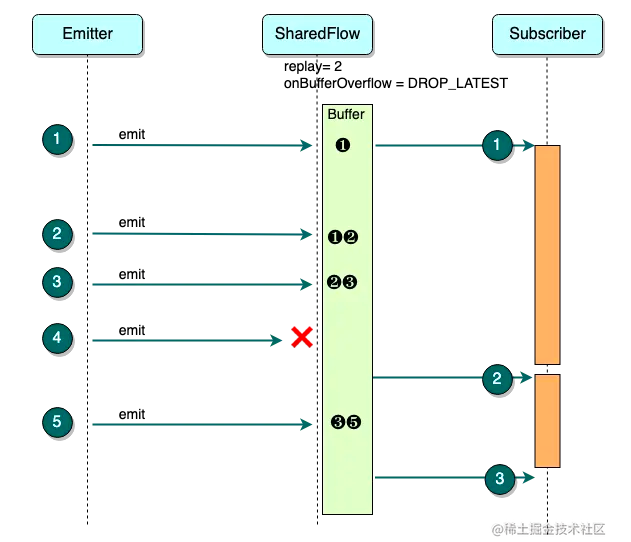
上图展示 DROP_LATEST 的效果。假设 replay = 2,extra = 0
- Emitter 发送 ❸ 时,由于 ❶ 已经被消费,所以 Buffer 数据从 ❶❷ 变为 ❷❸
- Emitter 发送 ❹ 时,由于 ❷ 还未被消费,Buffer 处于填满状态, ❹ 直接被丢弃
- Emitter 发送 ❺ 时,由于 ❷ 已经被费,可以移除缓存,Buffer 数据变为 ❸❺
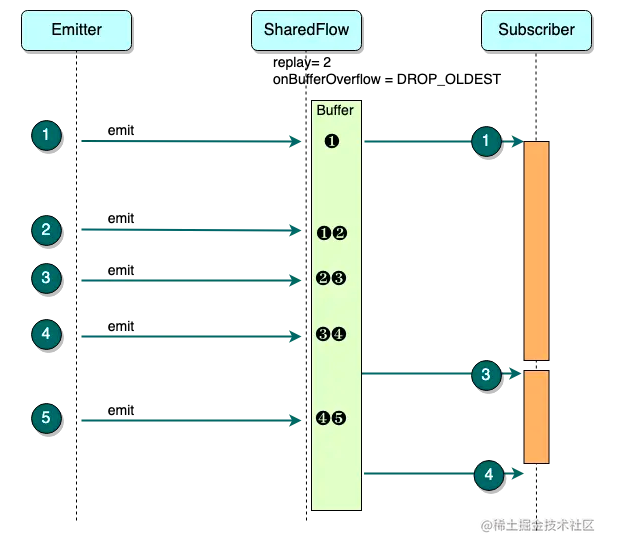
上图展示了 DROP_OLDEST 的效果,与 DROP_LATEST 比较后非常明显,缓存中永远会储存最新的两个数据,但是较老的数据不管有没有被消费,都可能会从 Buffer 移除,所以 Subscriber 可以消费当前最新的数据,但是有可能漏掉中间的数据,比如图中漏掉了 ❷
注意:当 extraBufferCapacity 设为 SUSPEND 可以保证 Subscriber 一个不漏的消费掉所有数据,但是会影响 Emitter 的速度;当设置为 DROP_XXX 时,可以保证 emit 调用后立即返回,但是 Subscriber 可能会漏掉部分数据。
如果我们不想让 emit 发生挂起,除了设置 DROP_XXX 之外,还有一个方法就是调用 tryEmit,这是一个非 suspend 版本的 emit
abstract suspend override fun emit(value: T) abstract fun tryEmit(value: T): Boolean
tryEmit 返回一个 boolean 值,你可以这样判断返回值,当使用 emit 会挂起时,使用 tryEmit 会返回 false,其余情况都是 true。这意味着 tryEmit 返回 false 的前提是 extraBufferCapacity 必须设为 SUSPEND,且 Buffer 中空余位置为 0 。此时使用 tryEmit 的效果等同于 DROP_LATEST。
SharedFlow Buffer
前面介绍的 MutableSharedFlow 的三个参数,其本质都是围绕 SharedFlow 的 Buffer 进行工作的。那么这个 Buffer 具体结构是怎样的呢?
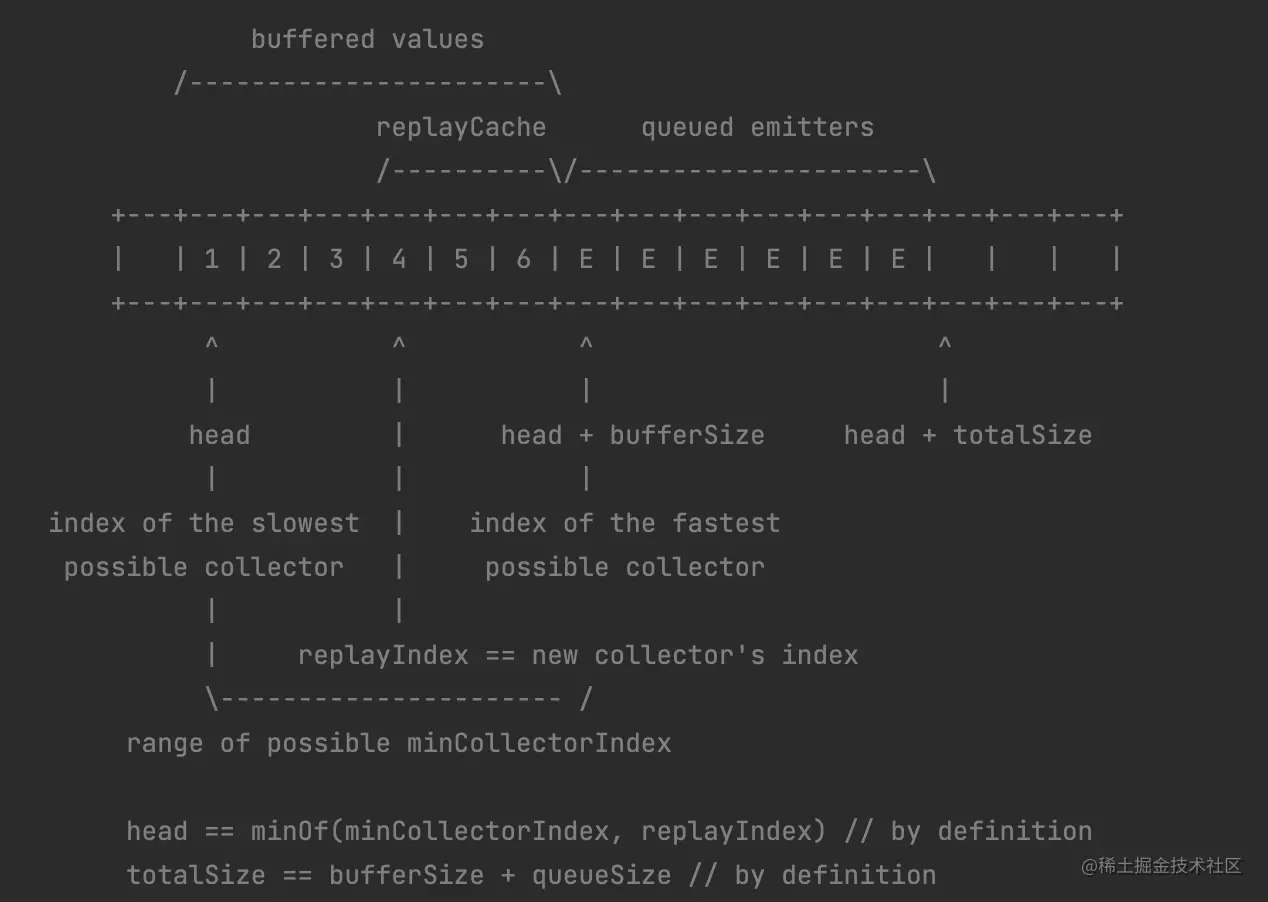
上面这个图是 SharedFlow 源码中关于 Buffer 的注释,这个图形象地告诉了我们 Buffer 是一个线性数据结构(就是一个普通的数组 Array<Any?>),但是这个图不能直观反应 Buffer 运行机制。下面通过一个例子,看一下 Buffer 在运行时的具体更新过程:
val sharedFlow = MutableSharedFlow<Int>(
replay = 2,
extraBufferCapacity = 2,
onBufferOverflow = BufferOverflow.SUSPEND
)
var emitValue = 1
fun main() {
runBlocking {
launch {
sharedFlow.onEach {
delay(200) // simulate the consume of data
}.collect()
}
repeat(12) {
sharedFlow.emit(emitValue)
emitValue++
delay(50)
}
}
}
上面的代码很简单,SharedFlow 的 BufferSize = 2+2 = 4,Emitter 生产的速度大于 Subscriber 消费的速度,所以过程中会出现 Buffer 的填充和更新,下面依旧用图的方式展示 Buffer 的变化
先看一下代码对应的时序图:
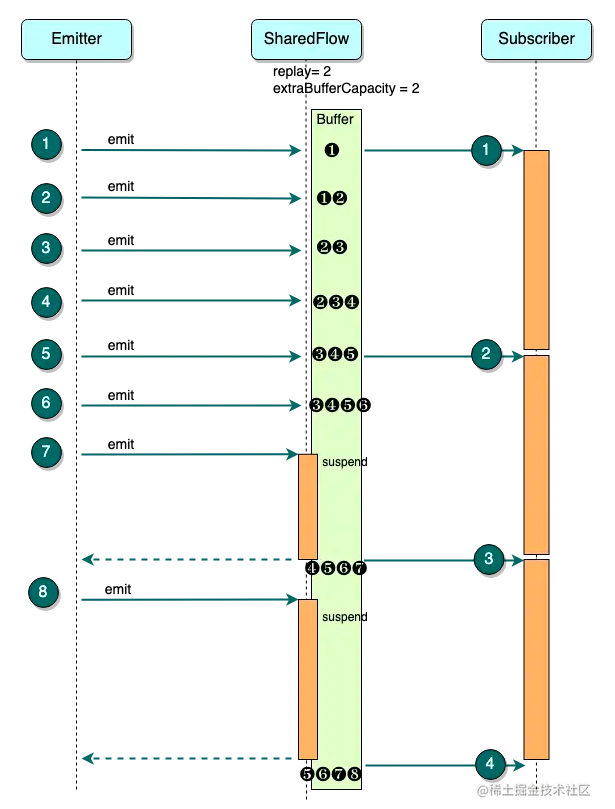
有前面的介绍,相信这个时序图很容易理解,这里就不再赘述了,下面重点图解一下 Buffer 的内存变化。SharedFlow 的 Buffer 本质上是一个基于 Array 实现的 queue,通过指针移动从往队列增删元素,避免了元素在实际数组中的移动。这里关键的指针有三个:
- head:队列的 head 指向 Buffer 的第一个有效数据,这是时间上最早进入缓存的数据,在数据被所有的 Subscriber 消费之前不会移除缓存。因此 head 也代表了最慢的 Subscriber 的处理进度
- replay:Buffer 为 replay-cache 预留空间的其实位置,当有新的 Subscriber 订阅发生时,从此位置开始处理数据。
- end:新数据进入缓存时的位置,end 这也代表了最快的 Subscriber 的处理进度。
如果 bufferSize 表示当前 Buffer 中存储数据的个数,则我们可知三指针 index 符合如下关系:
- replay <= head + bufferSize
- end = head + bufferSize
了解了三指针的含义后,我们再来看上图中的 Buffer 是如何工作的:
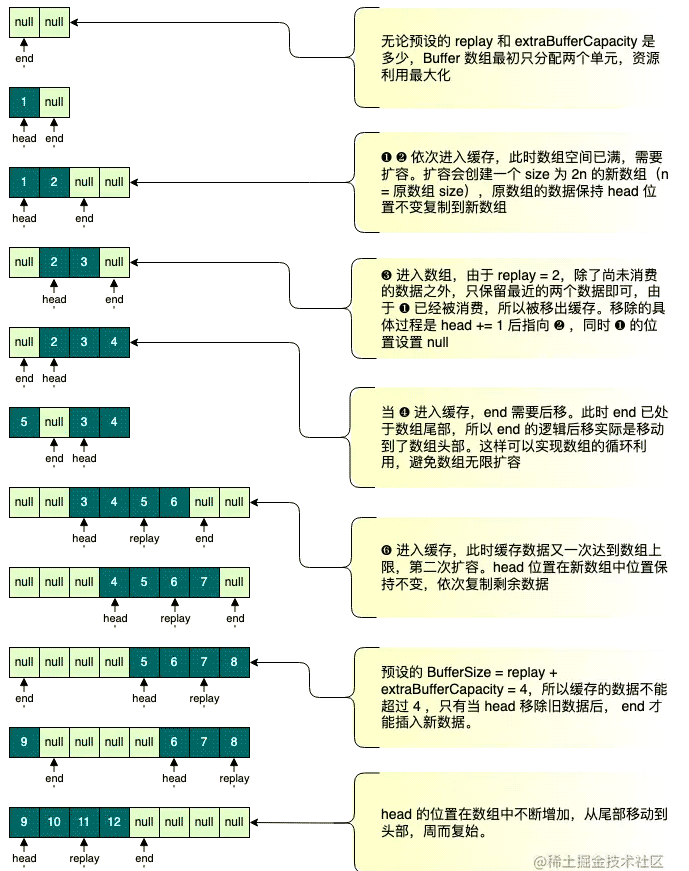
最后,总结一下 Buffer 的特点:
- 基于数组实现,当数组空间不够时进行 2n 的扩容
- 元素进入数组后的位置保持不变,通过移动指针,决定数据的消费起点
- 指针移动到数组尾部后,会重新指向头部,数组空间可循环使用
加载全部内容