Kafka GroupCoordinator
石臻臻的杂货铺 人气:0协调器的生命周期
- 什么是协调器
- 协调器工作原理
- 协调器的Rebalance机制
GroupCoordinator的创建
在Kafka启动的时候, 会自动创建并启动GroupCoordinator

这个GroupCoordinator对象创建的时候传入的几个属性需要介绍一下
new GroupCoordinator(config.brokerId, groupConfig, offsetConfig, groupMetadataManager, heartbeatPurgatory, joinPurgatory, time, metrics)
offsetConfig相关配置
private[group] def offsetConfig(config: KafkaConfig) = OffsetConfig(
maxMetadataSize = config.offsetMetadataMaxSize,
loadBufferSize = config.offsetsLoadBufferSize,
offsetsRetentionMs = config.offsetsRetentionMinutes * 60L * 1000L,
offsetsRetentionCheckIntervalMs = config.offsetsRetentionCheckIntervalMs,
offsetsTopicNumPartitions = config.offsetsTopicPartitions,
offsetsTopicSegmentBytes = config.offsetsTopicSegmentBytes,
offsetsTopicReplicationFactor = config.offsetsTopicReplicationFactor,
offsetsTopicCompressionCodec = config.offsetsTopicCompressionCodec,
offsetCommitTimeoutMs = config.offsetCommitTimeoutMs,
offsetCommitRequiredAcks = config.offsetCommitRequiredAcks
)
| 属性 | 介绍 | 默认值 |
|---|---|---|
| offset.metadata.max.bytes | ||
| offsets.load.buffer.size | ||
| offsets.retention.minutes | ||
| offsets.retention.check.interval.ms | ||
| offsets.topic.num.partitions | ||
| offsets.commit.timeout.ms | ||
| offsets.topic.segment.bytes | ||
| offsets.topic.replication.factor | ||
| offsets.topic.compression.codec | ||
| offsets.commit.timeout.ms | ||
| offsets.commit.required.acks |
groupConfig相关配置
| 属性 | 介绍 | 默认值 |
|---|---|---|
| group.min.session.timeout.ms | ||
| group.max.session.timeout.ms | ||
| group.initial.rebalance.delay.ms | ||
| group.max.size | ||
| group.initial.rebalance.delay.ms |
groupMetadataManager
组元信息管理类
heartbeatPurgatory
心跳监测操作,每一秒执行一次
joinPurgatory
GroupCoordinator的启动
def startup(enableMetadataExpiration: Boolean = true): Unit = {
info("Starting up.")
groupManager.startup(enableMetadataExpiration)
isActive.set(true)
info("Startup complete.")
}
这个启动对于GroupCoordinator来说只是给属性isActive标记为了true, 但是同时呢也调用了GroupMetadataManager.startup
定时清理Group元信息
这个Group元信息管理类呢启动了一个定时任务, 名字为:delete-expired-group-metadata
每隔600000ms的时候就执行一下 清理过期组元信息的操作, 这个600000ms时间是代码写死的。
TODO:GroupMetadataManager#cleanupGroupMetadata
GroupCoordinator OnElection
当内部topic __consumer_offsets 有分区的Leader变更的时候,比如触发了 LeaderAndIsr的请求, 发现分区Leader进行了切换。
那么就会执行 GroupCoordinator#OnElection 的接口, 这个接口会把任务丢个一个单线程的调度程序, 专门处理offset元数据缓存加载和卸载的。线程名称前缀为group-metadata-manager- ,一个分区一个任务
最终执行的任务内容是:GroupMetadataManager#doLoadGroupsAndOffsets
__consumer_offsets 的key有两种消息类型
key version 0: 消费组消费偏移量信息 -> value version 0: [offset, metadata, timestamp]
key version 1: 消费组消费偏移量信息-> value version 1: [offset, metadata, commit_timestamp, expire_timestamp]
key version 2: 消费组的元信息 -> value version 0: [protocol_type, generation, protocol, leader,
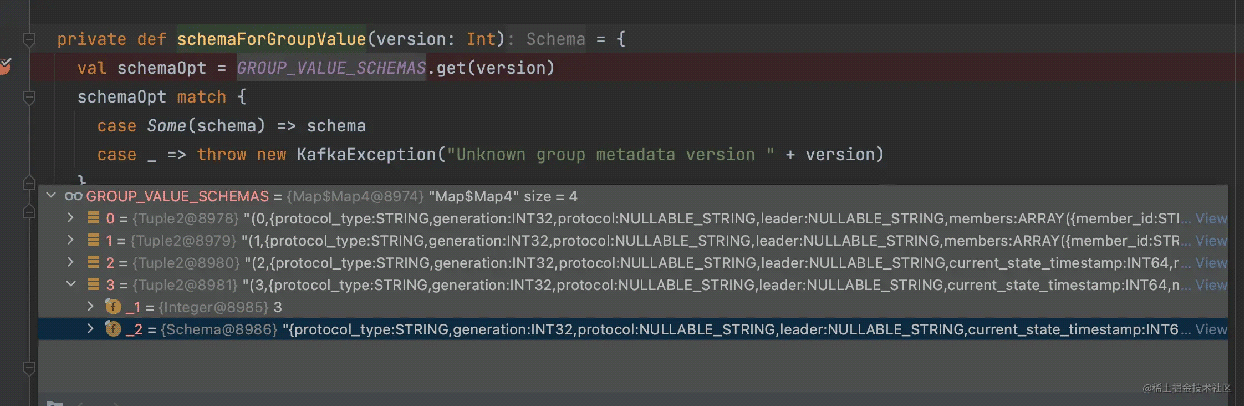
例如 version:3 的schemaForGroupValue
Version-0
{
protocol_type: STRING,
generation: INT32,
protocol: NULLABLE_STRING,
leader: NULLABLE_STRING,
members: ARRAY({
member_id: STRING,
client_id: STRING,
client_host: STRING,
session_timeout: INT32,
subscription: BYTES,
assignment: BYTES
})
}
Version-1
{
protocol_type: STRING,
generation: INT32,
protocol: NULLABLE_STRING,
leader: NULLABLE_STRING,
members: ARRAY({
member_id: STRING,
client_id: STRING,
client_host: STRING,
rebalance_timeout: INT32,
session_timeout: INT32,
subscription: BYTES,
assignment: BYTES
})
}
Version-2
{
protocol_type: STRING,
generation: INT32,
protocol: NULLABLE_STRING,
leader: NULLABLE_STRING,
current_state_timestamp: INT64,
members: ARRAY({
member_id: STRING,
client_id: STRING,
client_host: STRING,
rebalance_timeout: INT32,
session_timeout: INT32,
subscription: BYTES,
assignment: BYTES
})
}
Version-3
{
protocol_type: STRING,
generation: INT32,
protocol: NULLABLE_STRING,
leader: NULLABLE_STRING,
current_state_timestamp: INT64,
members: ARRAY({
member_id: STRING,
group_instance_id: NULLABLE_STRING,
client_id: STRING,
client_host: STRING,
rebalance_timeout: INT32,
session_timeout: INT32,
subscription: BYTES,
assignment: BYTES
})
}
Value每个版本的 Scheme如下
private val GROUP_METADATA_VALUE_SCHEMA_V0 = new Schema(
new Field(PROTOCOL_TYPE_KEY, STRING),
new Field(GENERATION_KEY, INT32),
new Field(PROTOCOL_KEY, NULLABLE_STRING),
new Field(LEADER_KEY, NULLABLE_STRING),
new Field(MEMBERS_KEY, new ArrayOf(MEMBER_METADATA_V0)))
private val GROUP_METADATA_VALUE_SCHEMA_V1 = new Schema(
new Field(PROTOCOL_TYPE_KEY, STRING),
new Field(GENERATION_KEY, INT32),
new Field(PROTOCOL_KEY, NULLABLE_STRING),
new Field(LEADER_KEY, NULLABLE_STRING),
new Field(MEMBERS_KEY, new ArrayOf(MEMBER_METADATA_V1)))
private val GROUP_METADATA_VALUE_SCHEMA_V2 = new Schema(
new Field(PROTOCOL_TYPE_KEY, STRING),
new Field(GENERATION_KEY, INT32),
new Field(PROTOCOL_KEY, NULLABLE_STRING),
new Field(LEADER_KEY, NULLABLE_STRING),
new Field(CURRENT_STATE_TIMESTAMP_KEY, INT64),
new Field(MEMBERS_KEY, new ArrayOf(MEMBER_METADATA_V2)))
private val GROUP_METADATA_VALUE_SCHEMA_V3 = new Schema(
new Field(PROTOCOL_TYPE_KEY, STRING),
new Field(GENERATION_KEY, INT32),
new Field(PROTOCOL_KEY, NULLABLE_STRING),
new Field(LEADER_KEY, NULLABLE_STRING),
new Field(CURRENT_STATE_TIMESTAMP_KEY, INT64),
new Field(MEMBERS_KEY, new ArrayOf(MEMBER_METADATA_V3)))
GroupCoordinator onResignation
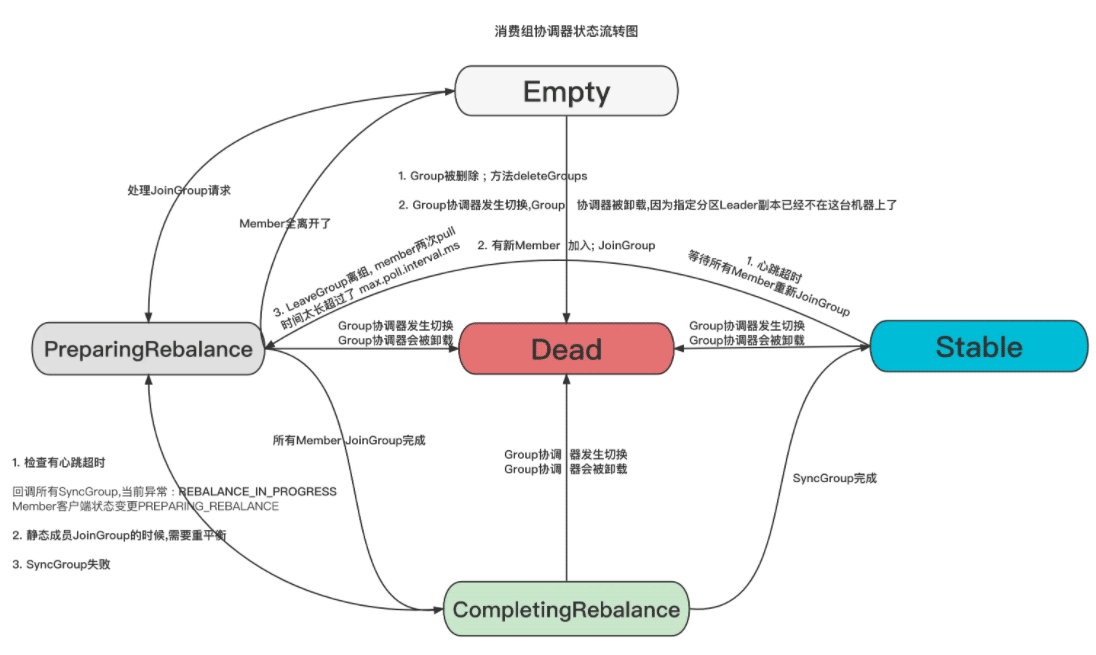
加载全部内容