Java Kafka延迟队列
整点bug 人气:0kafka作为一个使用广泛的消息队列,很多人都不会陌生,但当你在网上搜索“kafka 延迟队列”,出现的都是一些讲解时间轮或者只是提供了一些思路,并没有一份真实可用的代码实现,今天我们就来打破这个现象,提供一份可运行的代码,抛砖引玉,吸引更多的大神来分享。
基于kafka如何实现延迟队列
想要解决一个问题,我们需要先分解问题。kafka作为一个高性能的消息队列,只要消费能力足够,发出的消息都是会立刻收到的,因此我们需要想一个办法,让消息延迟发送出去。
网上已经有大神给出了如下方案:
- 在发送延迟消息时不直接发送到目标topic,而是发送到一个用于处理延迟消息的topic,例如
delay-minutes-1 - 写一段代码拉取
delay-minutes-1中的消息,将满足条件的消息发送到真正的目标主题里。
就像画一匹马一样简单。

方案是好的,但是我们还需要更多细节。
完善细节
问题出在哪里?
问题出在延迟消息发出去之后,代码程序就会立刻收到延迟消息,要如何处理才能让延迟消息等待一段时间才发送到真正的topic里面。
可能有同学会觉得很简单嘛,在代码程序收到消息之后判断条件不满足,就调用sleep方法,过了一段时间我再进行下一个循环拉取消息。
真的可行吗?
一切好像都很美好,但这是不可行的。
这是因为在轮询kafka拉取消息的时候,它会返回由max.poll.records配置指定的一批消息,但是当程序代码不能在max.poll.interval.ms配置的期望时间内处理这些消息的话,kafka就会认为这个消费者已经挂了,会进行rebalance,同时你这个消费者就无法再拉取到任何消息了。
举个例子:当你需要一个24小时的延迟消息队列,在代码里面写下了Thread.sleep(1000*60*60*24);,为了不发生rebalance,你把max.poll.interval.ms 也改成了1000*60*60*24,这个时候你或许会感觉到一丝丝的怪异,我是谁?我在哪?我为什么要写出来这样的代码?
其实我们可以更优雅的处理这个问题。
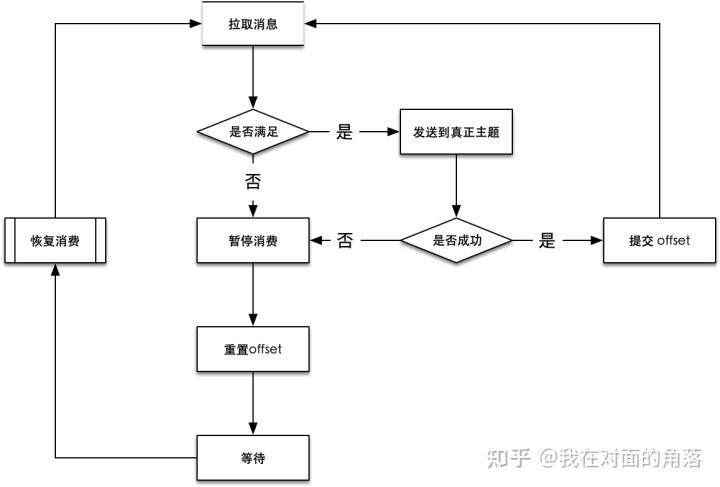
KafkaConsumer 提供了暂停和恢复的API函数,调用消费者的暂停方法后就无法再拉取到新的消息,同时长时间不消费kafka也不会认为这个消费者已经挂掉了。另外为了能够更加优雅,我们会启动一个定时器来替换sleep。,完整流程如下图,当消费者发现消息不满足条件时,我们就暂停消费者,并把偏移量seek到上一次消费的位置以便等待下一个周期再次消费这条消息。
Java代码实现
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.Duration;
import java.util.*;
import java.util.concurrent.ExecutionException;
@SpringBootTest
public class DelayQueueTest {
private KafkaConsumer<String, String> consumer;
private KafkaProducer<String, String> producer;
private volatile Boolean exit = false;
private final Object lock = new Object();
private final String servers = "";
@BeforeEach
void initConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "d");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, "5000");
consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer());
}
@BeforeEach
void initProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
}
@Test
void testDelayQueue() throws JsonProcessingException, InterruptedException {
String topic = "delay-minutes-1";
List<String> topics = Collections.singletonList(topic);
consumer.subscribe(topics);
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
synchronized (lock) {
consumer.resume(consumer.paused());
lock.notify();
}
}
}, 0, 1000);
do {
synchronized (lock) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(200));
if (consumerRecords.isEmpty()) {
lock.wait();
continue;
}
boolean timed = false;
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
long timestamp = consumerRecord.timestamp();
TopicPartition topicPartition = new TopicPartition(consumerRecord.topic(), consumerRecord.partition());
if (timestamp + 60 * 1000 < System.currentTimeMillis()) {
String value = consumerRecord.value();
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(value);
JsonNode jsonNodeTopic = jsonNode.get("topic");
String appTopic = null, appKey = null, appValue = null;
if (jsonNodeTopic != null) {
appTopic = jsonNodeTopic.asText();
}
if (appTopic == null) {
continue;
}
JsonNode jsonNodeKey = jsonNode.get("key");
if (jsonNodeKey != null) {
appKey = jsonNode.asText();
}
JsonNode jsonNodeValue = jsonNode.get("value");
if (jsonNodeValue != null) {
appValue = jsonNodeValue.asText();
}
// send to application topic
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(appTopic, appKey, appValue);
try {
producer.send(producerRecord).get();
// success. commit message
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(consumerRecord.offset() + 1);
HashMap<TopicPartition, OffsetAndMetadata> metadataHashMap = new HashMap<>();
metadataHashMap.put(topicPartition, offsetAndMetadata);
consumer.commitSync(metadataHashMap);
} catch (ExecutionException e) {
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed = true;
break;
}
} else {
consumer.pause(Collections.singletonList(topicPartition));
consumer.seek(topicPartition, consumerRecord.offset());
timed = true;
break;
}
}
if (timed) {
lock.wait();
}
}
} while (!exit);
}
}
这段程序是基于SpringBoot 2.4.4版本和 kafka-client 2.7.0版本编写的一个单元测试,需要修改私有变量servers为kafka broker的地址。
在启动程序后,向Topic delay-minutes-1 发送如以下格式的json字符串数据
{
"topic": "target",
"key": "key1",
"value": "value1"
}
同时启动一个消费者监听topic target,在一分钟后,将会收到一条 key="key1", value="value1"的数据。
还需要做什么
创建多个topic用于处理不同时间的延迟消息,例如delay-minutes-1 delay-minutes-5 delay-minutes-10 delay-minutes-15以提供指数级别的延迟时间,这样比一个topic要好很多,毕竟在顺序拉取消息的时候,有一条消息不满足条件,后面的将全部进行排队。
到此这篇关于Java Kafka实现延迟队列的示例代码的文章就介绍到这了,更多相关Java Kafka延迟队列内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容