Java海量数据处理
码农研究僧 人气:1前言
硬件扩容是难满足海量数据处理需要的,如何利用现有条件进行海量信息处理
海量信息处理日益成为当前程序员笔试面试中一个新的亮点
基本方法
通过查询网上的方方面面知识点,以及阅读一些相关书籍
常见的方法有Hash法、Bit - map法、Bloom filter法、数据库优化法、倒排索引法、外排序法、Trie树、堆、双层桶法以及 MapRe-duce法等
1.1 哈希算法
也被叫做散列(映射关系)。数据元素中的关键字为key,按散列函数计算出hash ( key),也就是计算出它的存储地址,从而对数据进行一些操作
冲突指的就是两个关键字对应同一个函数值,也就是映射相同的地址
为了减少冲突,散列函数也很有讲究。尽量简单,函数值域要在其范围内,也要减少其冲突
在数据结构这本书中也有提及
- 常用的构造散列函数的方法主要有:直接寻址法(按照关键字的线性关系)、取模法、数字分析法、平方取中法等
- 常见的解决冲突的方法主要有:开放地址法(遇到冲突的时候按照某种方法进行探测)、链地址法等等
1.2 位图法
B使用位数组来表示某些元素是否存在(可用于查重,也可用于判断某个数据是否存在)适用于海量数据的快速查找、判重、删除等。
具体的操作是生成N位字符,如果有数字标为1,没数字标为0。(用空间来换取时间,其排序的时间复杂度为 O(n))

1.3 Bloom Filter
检测一个元素是否属于一个集合。牺牲正确率换取空间效率与时间效率的提高。
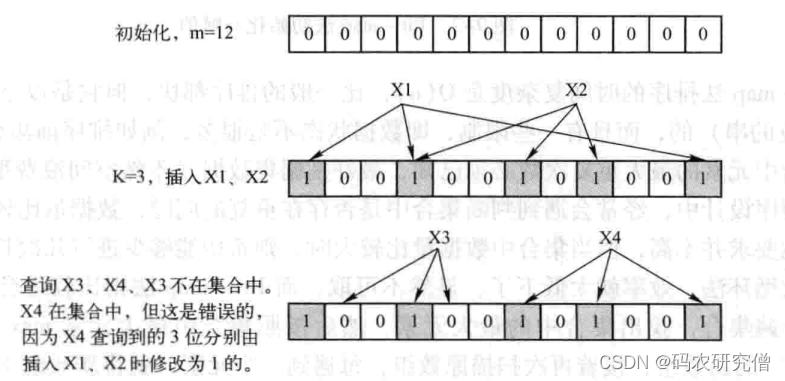
基本原理是位数组与Hash函数的结合,包含m位数组(初始化为0),定义k个不同的hash函数(每个函数映射到位数组的k个位置)联合使用。向集合插入元素时,根据k个Hash函数可以得到位数组中的k个位(设置为1),查询查询某个元素是否属于集合,k个为1(存在),k个位不为1(不存在)。在插人其他元素时,可能会将其他位置为1,产生了错误。
1.4 数据库优化
可以通过数据库的工具、数据分区、索引、缓存机制、优化查询、排序等
1.5 倒排索引法
根据关键字的某些值进行排序从而建立索引
存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射,它是文档检索系统中最常用的数据结构
有两种不同的反向索引形式:
- 第一种形式是一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表;
- 第二种形式是一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
- 第二种形式提供了更多的兼容性(例如短语搜索),但是需要更多的时间和空间来创建。
一般情况下可以采用矩阵的方式存储来存储,但会浪费大量的空间
1.6 外排序法
定义:在内存中不能一次处理过多的对象,须以文件形式外放。排序需一步步调入内存处理(相对大文件,无法一次装入内存中,需多次交换数据)
可采用归并排序或者二路归并排序的手法
适用于大数据的排序和查重,但是效率比较低,因为要用到io的操作
1.7 字典树
利用字符串的公共前缀来减少时空开销(空间换时间)。用于快速字符串检索的多叉树结构
统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
优点是:最大限度地减少无谓的字符串比较,查询效率比散列表高。
Trie树一般具有3个基本特性:
- 根结点不包含字符,除根结点外每一个结点都只包含一个字符。
- 从根结点到某一结点,路径上经过的字符连接起来,为该结点对应的字符串。
- 每个结点的所有子结点包含的字符都不相同。
2. 经典问题分析
2.1 top k问题
频率最高的k个数或者找出最大的k个数等,目前比较好的方法是分治+Trie树/hash +小顶堆。
- hash方法分解成多个小数据集(如果有重复的数字的话,通过去重减少很多的数据集)
- Trie树或者hash统计每个小数据集中的query词频
- 小顶堆求出每个数据集中出频率最高的前K个数
- 最后在所有top K中求出最终的top K
在实际应用中,可能有足够大的内存,那么直接将数据扔到内存中一次性处理即可,也可能机器有多个核,这样可以采用多线程处理整个数据集。
2.2 重复问题
该问题可通过位图法进行,此方法最优
具体的执行代码可看书籍中的展示,此为该书籍的展示代码



2.3 排序问题
数据库排序(要求数据库的规格比较好)
分治法(虽然缩小内存,但是编码复杂,速度变慢)
位图法
加载全部内容