python处理Excel表格
lainwith 人气:0前言
- 一个Excel电子表格文档称为一个工作簿
- 一个工作簿保存在一个扩展名为.xlsx的文件中
- 一个工作簿可以包含多个表
- 用户当前查看的表(或关闭Excel前最后查看的表)称为活动表
- 在特定行和列的方格称为单元格、格子

处理Excel表格需要用到openpyxl模块,该模块需要手动安装
pip install openpyxl
xls和xlsx
简单来说:
xls是excel2003及以前版本所生成的文件格式
xlsx是excel2007及以后版本所生成的文件格式
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式)
excel后缀.xls和.xlsx有什么区别
文件核心结构不同:
xls核心结构是复合文档类型的;
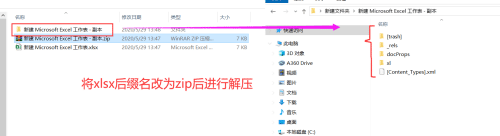
xlsx 的核心结构是 XML 类型的结构,并且基于XML进行压缩(占用空间更小),所以也可以看做zip文件,将一个“.xlsx”文件的后缀改为ZIP后,用解压软件解压,可以看到里面有一个xml文件和文件的主要内容。
版本不同:
- xls是excel2003及以前版本所生成的文件格式
- xlsx是excel2007及以后版本所生成的文件格式
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式)

最大行列得数量不同:
- xls最大只有65536行、256列
- xlsx可以有1048576行、16384列
二者转换问题:
任何能够打开“.xlsx”文件的文字处理软件都可以将该文档另存为“.xls”文件
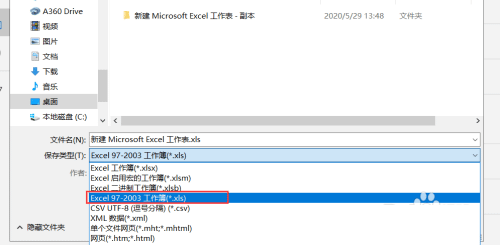
- 如果要将xlsx格式的文件转换为.xls格式的一定要注意将文件转换为xls格式之后只保存256列,其余的列都会被删掉
基本操作
用到的test.xlsx表格
在这里插入图片描述
1:用openpyxl模块打开Excel文档,查看所有sheet表
openpyxl.load_workbook()函数接受文件名,返回一个workbook数据类型的值。这个workbook对象代表这个Excel文件,这个有点类似File对象代表一个打开的文本文件。
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
# 结果:
# ['Sheet1', 'Sheet2']1.2:通过sheet名称获取表格
在第10行,使用workbook['Sheet1']获取指定sheet表
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
sheet = workbook['Sheet1'] # 获取指定sheet表
print(sheet)
# 结果:
# ['Sheet1', 'Sheet2']
# <Worksheet "Sheet1">1.2:获取活动表
使用workbook.active获取活动表
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print(sheet)
# 结果:
# <Worksheet "Sheet1">2:获取表格的尺寸
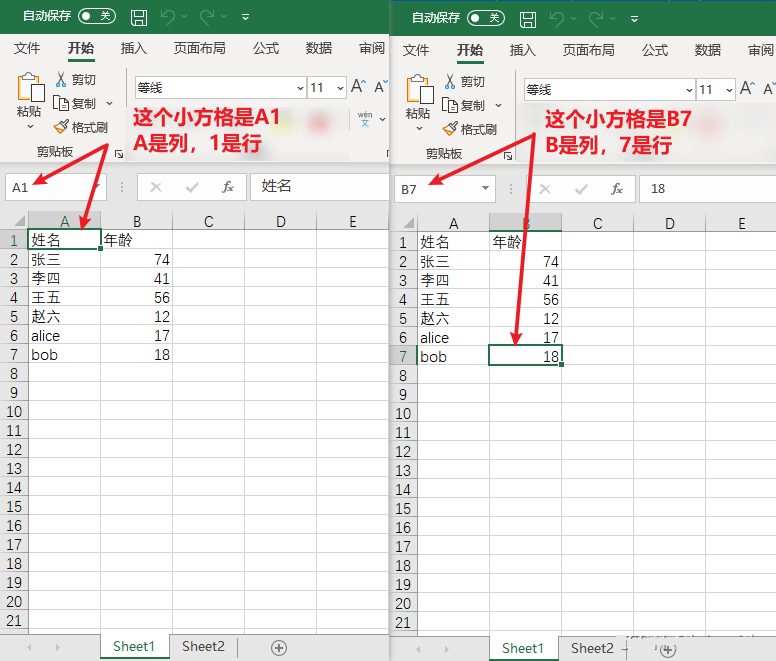
这里所说的尺寸大小,指的是excel表格中的数据有几行几列,针对的是不同的sheet而言
使用sheet.dimensions获取表格的尺寸
下面打印的A1:B7是什么意思呢?
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook['Sheet1'] # 获取指定sheet表
print(sheet.dimensions) # 获取表格的尺寸大小
# 结果:
# A1:B72.1:获取单元格中的数据
方法1:指定坐标的方式
sheet[“A1”]
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
# print(sheet.dimensions) # 获取表格的尺寸大小
cell1 = sheet['A1'] # 获取A1单元格的数据
cell2 = sheet['B7'] # 获取B7单元格的数据
# cell2 = sheet['B7'].value # 另一种写法
# 正确示范
# cell1.value获取单元格A1中的值
# cell2.value获取单元格B7中的值
print(cell1.value,cell2.value) # 姓名 18
# 错误示范
print(cell1,cell2) # <Cell 'Sheet1'.A1> <Cell 'Sheet1'.B7>方法2: 指定行列的方式
sheet.cell(row=, column=)方式
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
# print(sheet.dimensions) # 获取表格的尺寸大小
cell1 = sheet.cell(row=1,column=1) # 获取第1行第1列的数据
cell2 = sheet.cell(row=3,column=2) # 获取第3行第4的数据
# 正确示范
# cell1.value获取单元格A1中的值
# cell2.value获取单元格B7中的值
print(cell1.value,cell2.value) # 姓名 412.2:获取单元格的行、列、坐标
.row获取某个格子的行数;.columns获取某个格子的列数;.coordinate获取某个格子的坐标;
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
# print(sheet.dimensions) # 获取表格的尺寸大小
cell = sheet.cell(row=3, column=2) # 获取第3行第4的数据
print(cell.value, cell.row, cell.column, cell.coordinate)
'''
结果:
41 3 2 B3
'''3:获取区间内的数据
获取单行单列数据的时候,使用一层for循环;获取多行多列、指定区间的数据时,使用两层for循环
获取指定区间的数据:
- 使用
sheet['A1:A5']拿到指定区间 - 使用两个for循环拿到数据
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:')
print(sheet)
cell = sheet['A1:A5'] # 获取A1到A5的数据
print(cell)
# 打印A1到A5的数据
for i in cell:
for j in i:
print(j.value)
# 结果:
# 当前活动表是:
# <Worksheet "Sheet1">
# ((<Cell 'Sheet1'.A1>,), (<Cell 'Sheet1'.A2>,), (<Cell 'Sheet1'.A3>,), (<Cell 'Sheet1'.A4>,), (<Cell 'Sheet1'.A5>,))
# 姓名
# 张三
# 李四
# 王五
# 赵六获取指定行列的数据:
- sheet[“A”] — 获取A列的数据
- sheet[“A:C”] — 获取A,B,C三列的数据
- sheet[5] — 只获取第5行的数据
下面的代码,获取一列数据的时候,使用一层for循环
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
cell = sheet['2'] # 获取第2行的数据
# 打印A1到A5的数据
for i in cell:
print(i.value)
# 结果:
# 当前活动表是:<Worksheet "Sheet1">
# 张三
# 74下面代码,获取两列数据的时候,使用两层for循环。注意到,两列的结果打印到一起了,可读性较差
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
cell = sheet['A:B'] # 获取AB列的数据
# 打印AB列数据
for i in cell:
for j in i:
print(j.value)
# 结果:
# 当前活动表是:<Worksheet "Sheet1">
# 姓名
# 张三
# 李四
# 王五
# 赵六
# alice
# bob
# 年龄
# 74
# 41
# 56
# 12
# 17
# 18按行、列获取值:
iter_rows():按行读取iter_cols():按列读取
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
# 按行获取值
print('按行获取值')
for i in sheet.iter_rows(min_row=2, max_row=5, min_col=1, max_col=2):
for j in i:
print(j.value)
# 按列获取值
print('按列获取值')
for i in sheet.iter_cols(min_row=2, max_row=5, min_col=1, max_col=2):
for j in i:
print(j.value)
# 结果:
# 当前活动表是:<Worksheet "Sheet1">
# 按行获取值
# 张三
# 74
# 李四
# 41
# 王五
# 56
# 赵六
# 12
# 按列获取值
# 张三
# 李四
# 王五
# 赵六
# 74
# 41
# 56
# 12
获取活动表的行列数:
方法1:使用
- sheet.max_row 获取行数
- sheet.max_column 获取列数
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('2.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
rows = sheet.max_row # 获取行数
column = sheet.max_column # 获取列数
print(rows)
print(column)
'''
结果:
当前活动表是:<Worksheet "Sheet1">
381
6
'''方法2:自己写一个for循环
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
row = []
column = []
# 获取当前活动表有多少行
for i in sheet.rows:
row.append(list(i)) # i是元组类型,转为列表
# 获取当前活动表有多少列
for i in sheet.columns:
column.append(list(i)) # i是元组类型,转为列表
print('行数:'+str(len(row)))
print('列数:'+str(len(column)))
'''
结果:
当前活动表是:<Worksheet "1号sheet">
行数:12
列数:3
'''操作
创建新的excel
第9行代码用来指定创建的excel的活动表的名字:
- 不写第9行,默认创建sheet
- 写了第9行,创建指定名字的sheet表
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = '1号sheet'
workbook.save('1.xlsx')修改单元格、excel另存为
第9行代码,通过给单元格重新赋值,来修改单元格的值
第9行代码的另一种写法sheet['B1'].value = 'age'
第10行代码,保存时如果使用原来的(第7行)名字,就直接保存;如果使用了别的名字,就会另存为一个新文件
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
sheet['A1'] = 'name'
workbook.save('test.xlsx')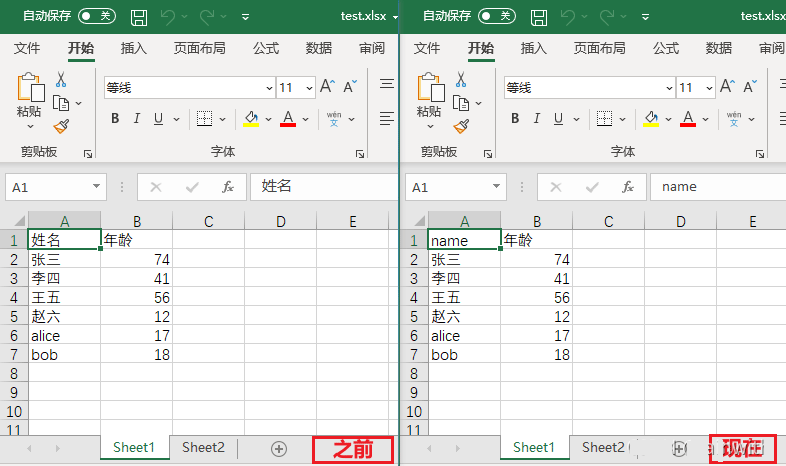
添加数据
插入有效数据
使用append()方法,在原来数据的后面,按行插入数据
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
data = [
['素子',23],
['巴特',24],
['塔奇克马',2]
]
for row in data:
sheet.append(row) # 使用append插入数据
workbook.save('test.xlsx')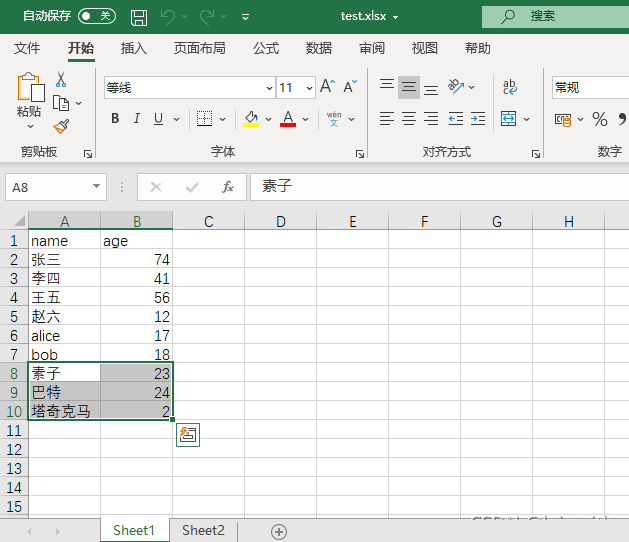
插入空行空列
- insert_rows(idx=数字编号, amount=要插入的行数),插入的行数是在idx行数的下方插入
- insert_cols(idx=数字编号, amount=要插入的列数),插入的位置是在idx列数的左侧插入
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
sheet.insert_rows(idx=3, amount=2)
sheet.insert_cols(idx=2, amount=1)
workbook.save('test.xlsx')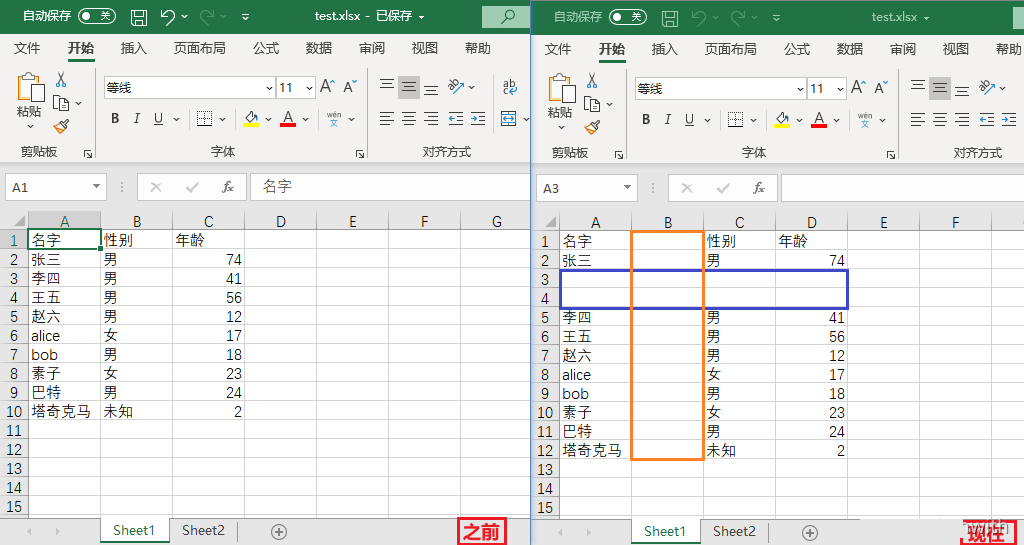
删除行、列
- delete_rows(idx=数字编号, amount=要删除的行数)
- delete_cols(idx=数字编号, amount=要删除的列数)
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
sheet.delete_rows(idx=10) # 删除第10行
sheet.delete_cols(idx=1, amount=2) # 删除第1列,及往右共2列
workbook.save('test.xlsx')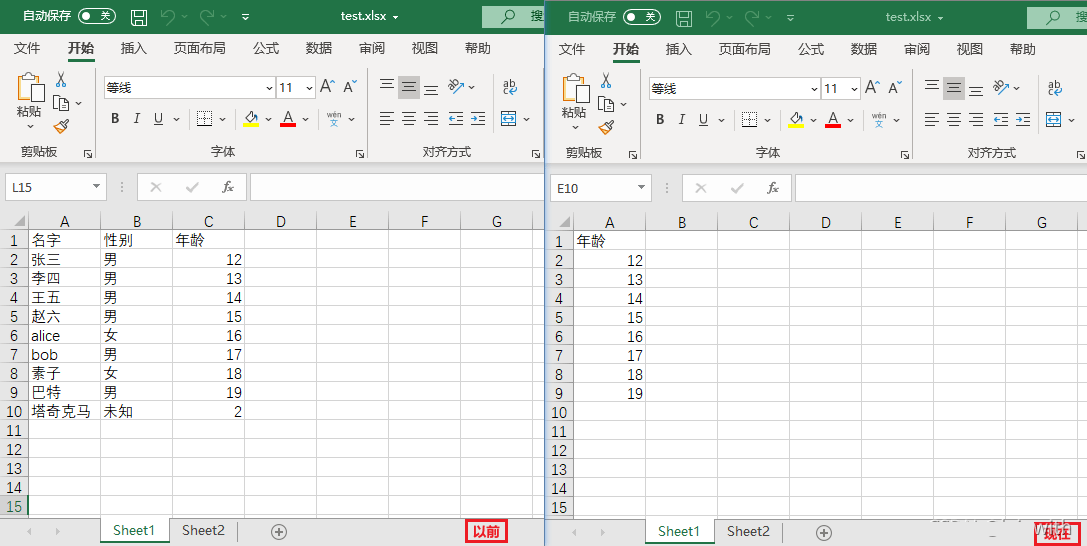
移动指定区间的单元格(move_range)
move_range(“数据区域”,rows=,cols=):正整数为向下或向右、负整数为向左或向上
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
sheet.move_range('D11:F12',rows=0,cols=-3) # 移动D11到F12构成的矩形格子
workbook.save('test.xlsx')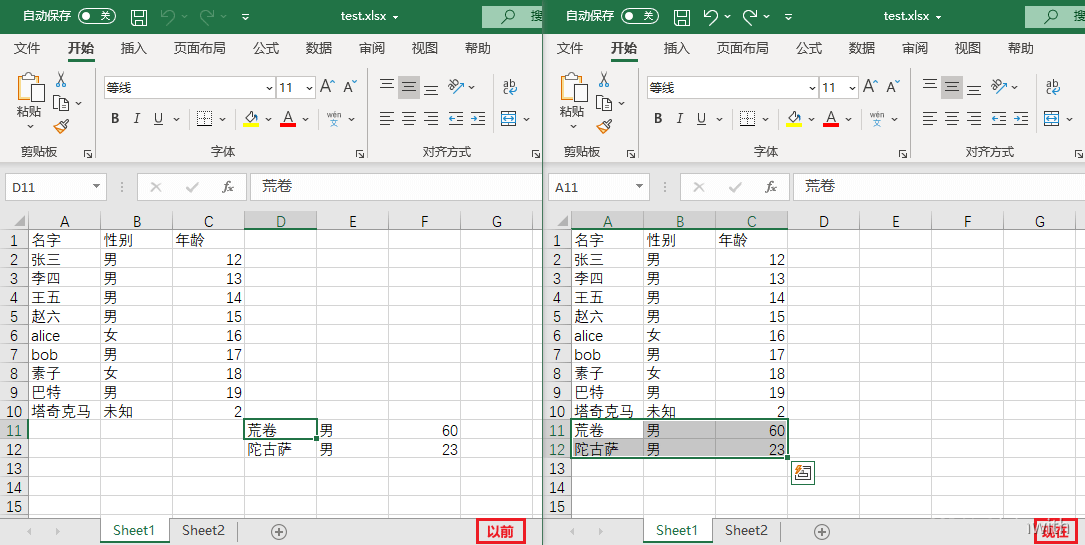
字母列号与数字列号之间的转换
核心代码:
from openpyxl.utils import get_column_letter, column_index_from_string
# 根据列的数字返回字母
print(get_column_letter(2)) # B
# 根据字母返回列的数字
print(column_index_from_string('D')) # 4举个例子:
import os
import openpyxl
from openpyxl.utils import get_column_letter, column_index_from_string
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('2.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
# 根据列的数字返回字母
print(get_column_letter(2)) # B
# 根据字母返回列的数字
print(column_index_from_string('D')) # 4字体样式
查看字体样式
import os
import openpyxl
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:'+str(sheet))
cell = sheet['A1']
font = cell.font
print('当前单元格的字体样式是')
print(font.name, font.size, font.bold, font.italic, font.color)
'''
当前活动表是:<Worksheet "1号sheet">
当前单元格的字体样式是
等线 11.0 False False <openpyxl.styles.colors.Color object>
Parameters:
rgb=None, indexed=None, auto=None, theme=1, tint=0.0, type='theme'
'''修改字体样式
openpyxl.styles.Font(name=字体名称,size=字体大小,bold=是否加粗,italic=是否斜体,color=字体颜色)
其中,字体颜色中的color是RGB的16进制表示
import os
import openpyxl
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print(sheet)
cell = sheet['A1']
cell.font = openpyxl.styles.Font(name="微软雅黑", size=20, bold=True, italic=True, color="FF0000")
workbook.save('test.xlsx')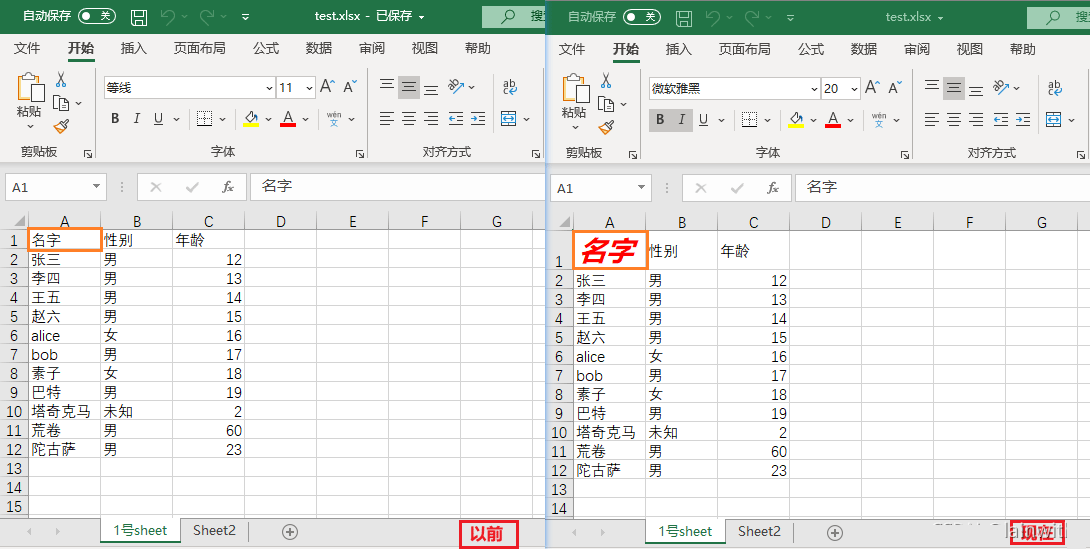
再者,可以使用for循环,修改多行多列的数据,
import os
import openpyxl
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print(sheet)
cell = sheet['A']
for i in cell:
i.font = openpyxl.styles.Font(name="微软雅黑", size=20, bold=True, italic=True, color="FF0000")
workbook.save('test.xlsx')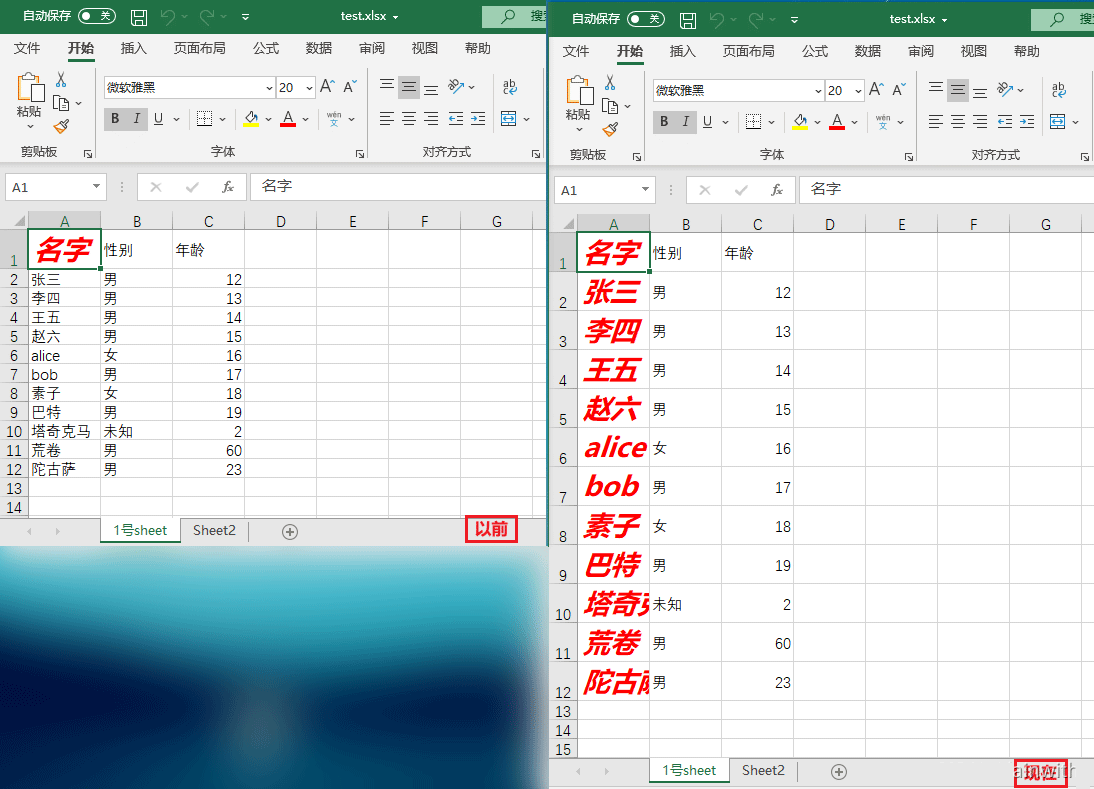
设置对齐格式
Alignment(horizontal=水平对齐模式,vertical=垂直对齐模式,text_rotation=旋转角度,wrap_text=是否自动换行)
水平对齐:‘distributed’,‘justify’,‘center’,‘left’, ‘centerContinuous’,'right,‘general’
垂直对齐:‘bottom’,‘distributed’,‘justify’,‘center’,‘top’
import os
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
cell = sheet['A1']
alignment = openpyxl.styles.Alignment(horizontal="center", vertical="center", text_rotation=0, wrap_text=True)
cell.alignment = alignment
workbook.save('test.xlsx')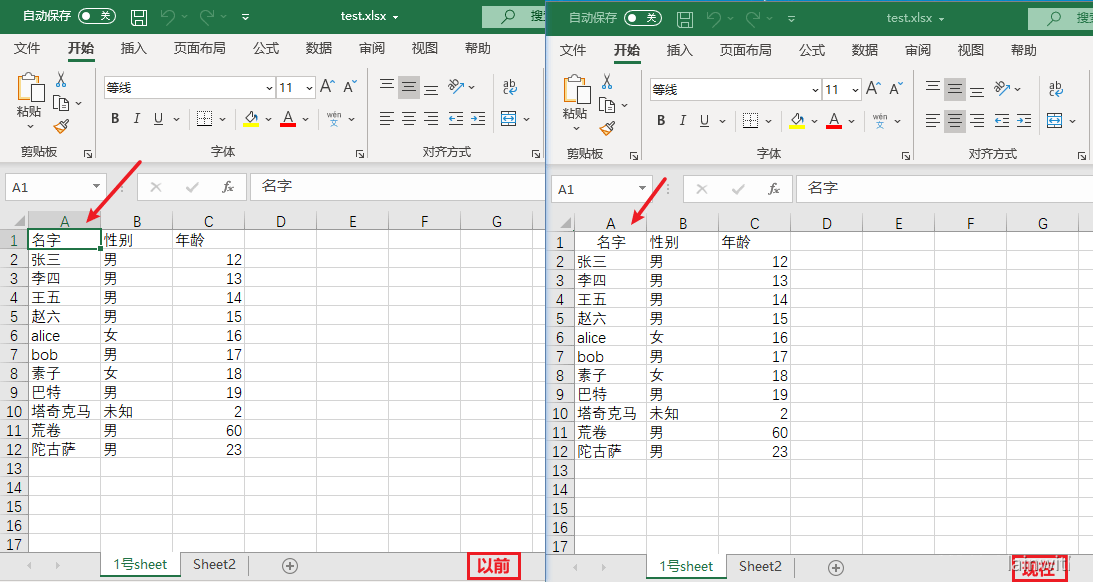
当然,你仍旧可以调用for循环来实现对多行多列的操作
import os
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
cell = sheet['A']
alignment = openpyxl.styles.Alignment(horizontal="center", vertical="center", text_rotation=0, wrap_text=True)
for i in cell:
i.alignment = alignment
workbook.save('test.xlsx')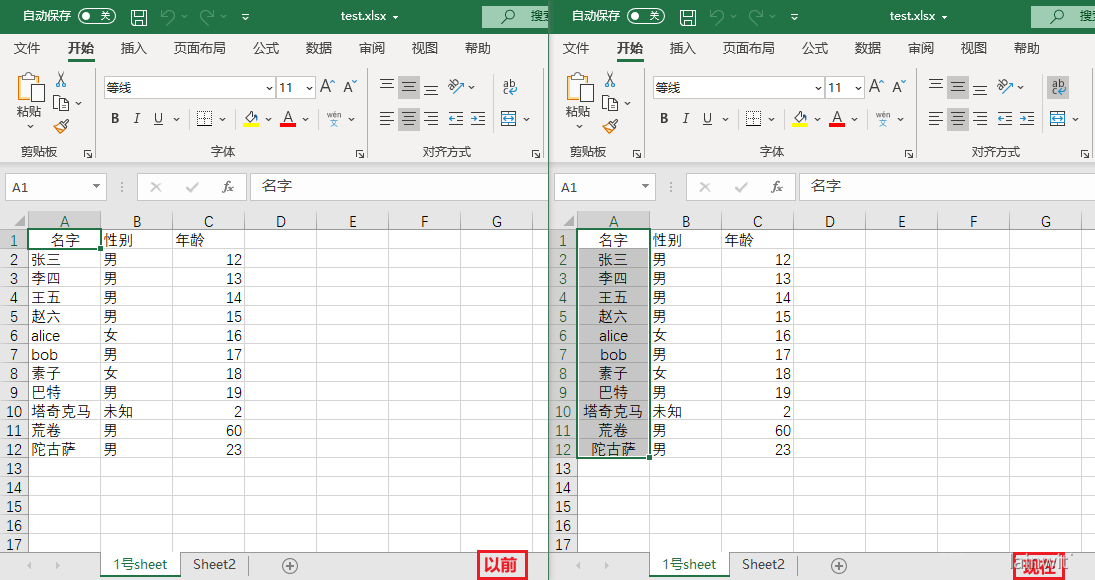
设置行高列宽
设置行列的宽高:
- row_dimensions[行编号].height = 行高
- column_dimensions[列编号].width = 列宽
import os
import openpyxl
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
# 设置第1行的高度
sheet.row_dimensions[1].height = 50
# 设置B列的卷度
sheet.column_dimensions['B'].width = 20
workbook.save('test.xlsx')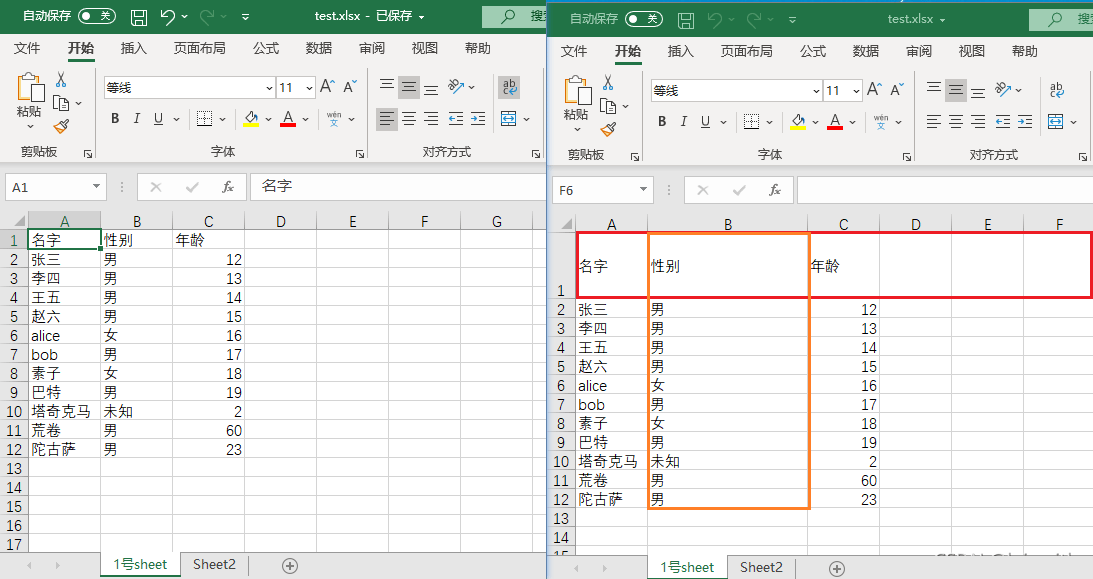
设置所有单元格(显示的结果是设置所有,有数据的单元格的)
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
import os
os.chdir(r'C:\Users\asuka\Desktop')
workbook = load_workbook('1.xlsx')
print(workbook.sheetnames) # 打印所有的sheet表
ws = workbook[workbook.sheetnames[0]] # 选中最左侧的sheet表
width = 2.0 # 设置宽度
height = width * (2.2862 / 0.3612) # 设置高度
print("row:", ws.max_row, "column:", ws.max_column) # 打印行数,列数
for i in range(1, ws.max_row + 1):
ws.row_dimensions[i].height = height
for i in range(1, ws.max_column + 1):
ws.column_dimensions[get_column_letter(i)].width = width
workbook.save('test.xlsx')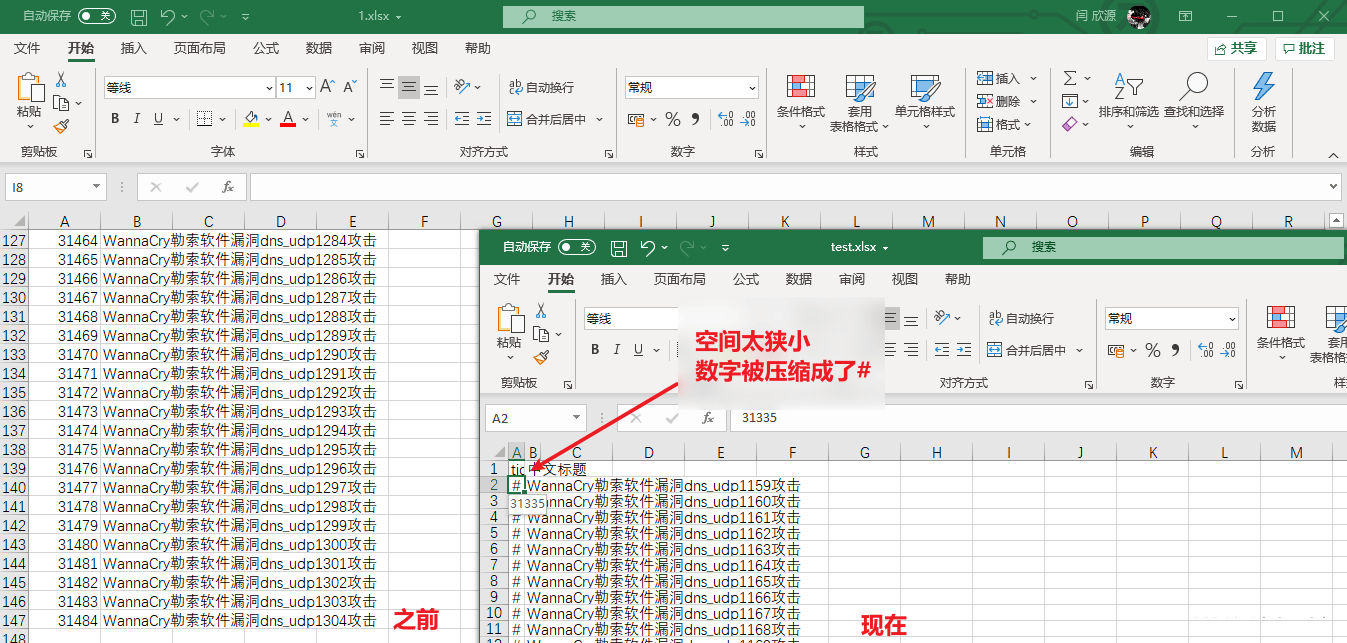
合并、拆分单元格
合并单元格有下面两种方法,需要注意的是,如果要合并的格子中有数据,即便python没有报错,Excel打开的时候也会报错。
- merge_cells(待合并的格子编号)
- merge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
import os
import openpyxl
import openpyxl.styles
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
# 方法1:
sheet.merge_cells('A12:B13')
# 方法2:
sheet.merge_cells(start_row=12, start_column=3, end_row=13, end_column=4)
# 加一个居中对齐
cell = sheet['A12']
alignment = openpyxl.styles.Alignment(horizontal="center", vertical="center", text_rotation=0, wrap_text=True)
cell.alignment = alignment
cell = sheet['C12']
alignment = openpyxl.styles.Alignment(horizontal="center", vertical="center", text_rotation=0, wrap_text=True)
cell.alignment = alignment
workbook.save('test.xlsx')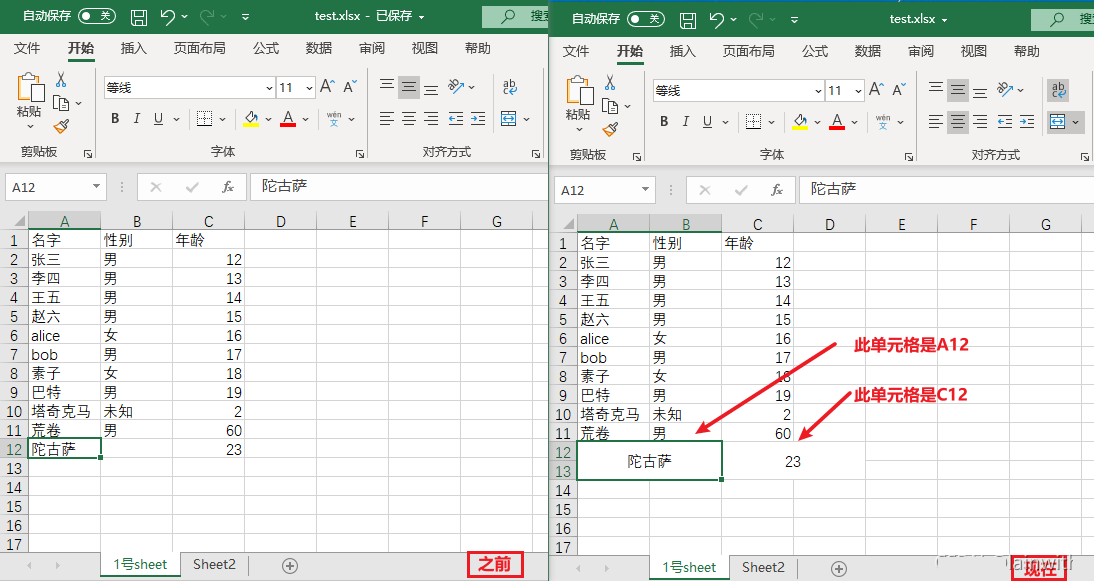
拆分单元格的方法同上
- unmerge_cells(待合并的格子编号)
- unmerge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
sheet表
创建新的sheet(create_sheet)
create_sheet(“新的sheet名”):创建一个新的sheet表
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
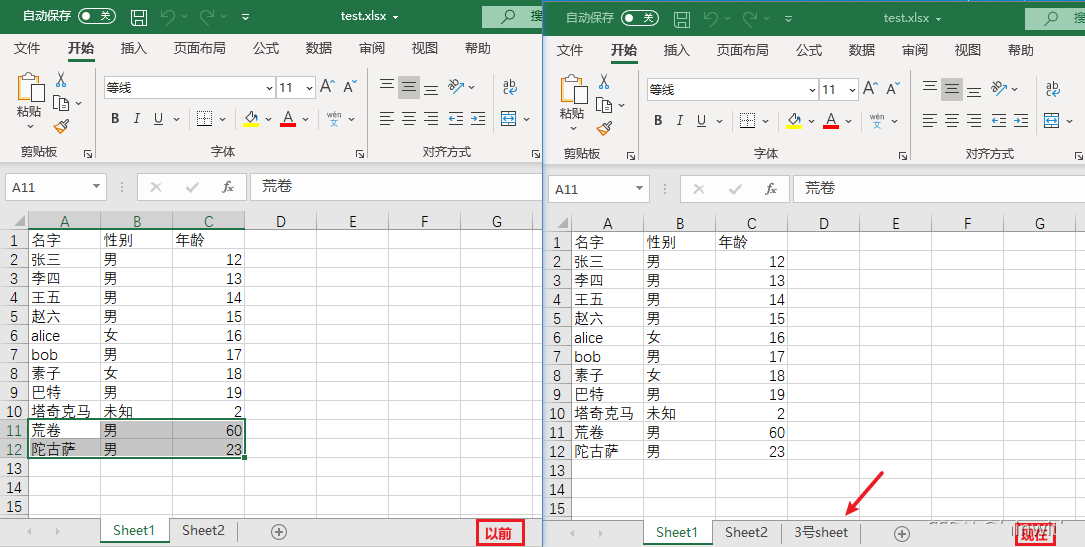
workbook.create_sheet('3号sheet') # 创建新的sheet表
print(workbook.sheetnames) # 查看所有的sheet表
workbook.save('test.xlsx')
'''
当前活动表是:<Worksheet "Sheet1">
['Sheet1', 'Sheet2', '3号sheet']
'''
修改sheet名字(title)
第11行,使用title修改sheet表的名字
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
sheet.title = '1号sheet' # 修改sheet表
workbook.save('test.xlsx')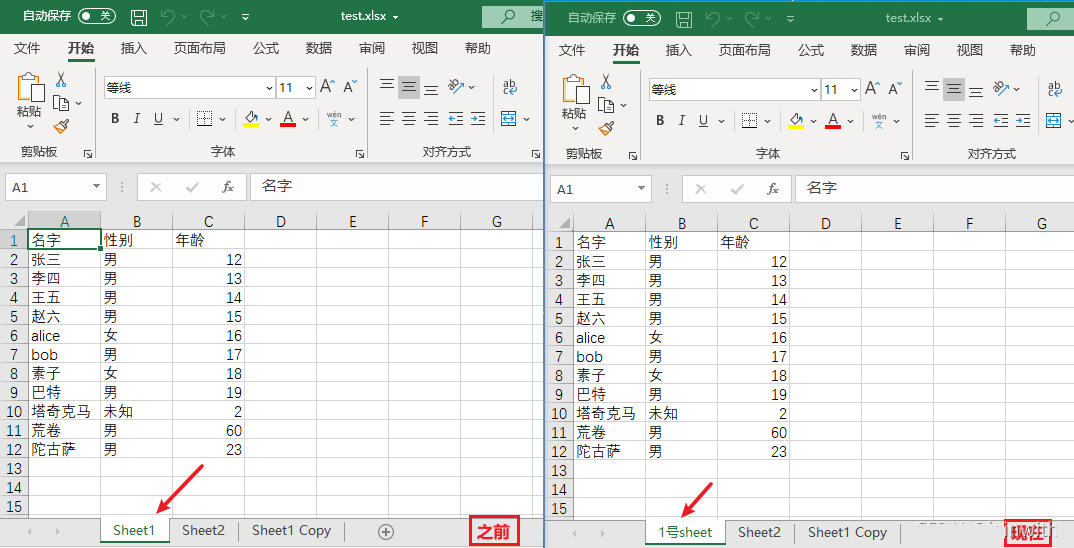
复制sheet表(copy_worksheet)
在“操作”>“修改单元格、excel另存为”中提到了另存为,其实复制sheet表就是一个另存为的过程,你要是在12行代码保存的时候使用第7行的文件名,那么复制的sheet表就保存到自己身上,内容跟copy.xlsx一样。
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
workbook.copy_worksheet(sheet) # 复制sheet表
workbook.save('copy.xlsx')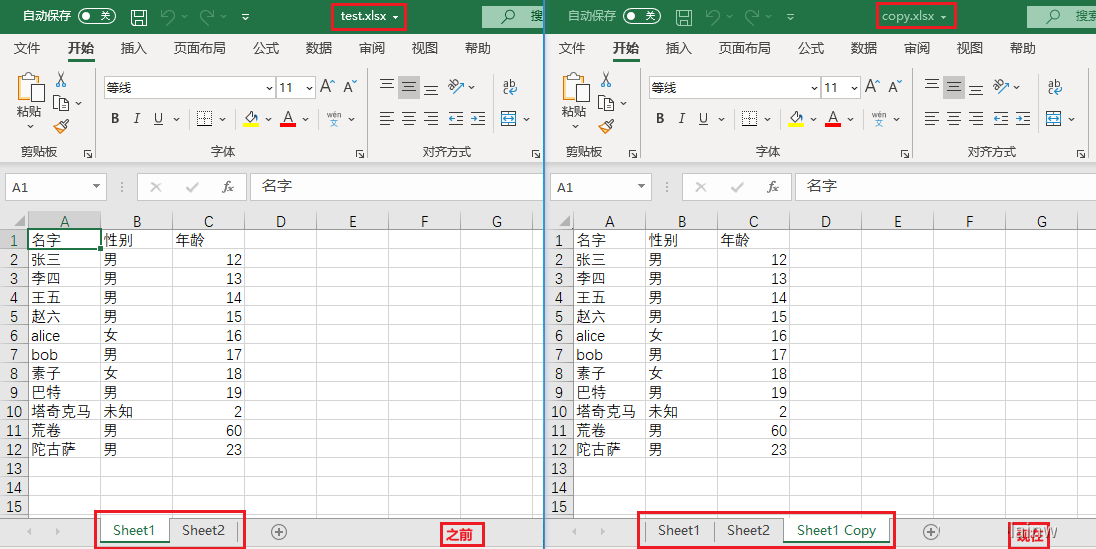
删除sheet表(remove)
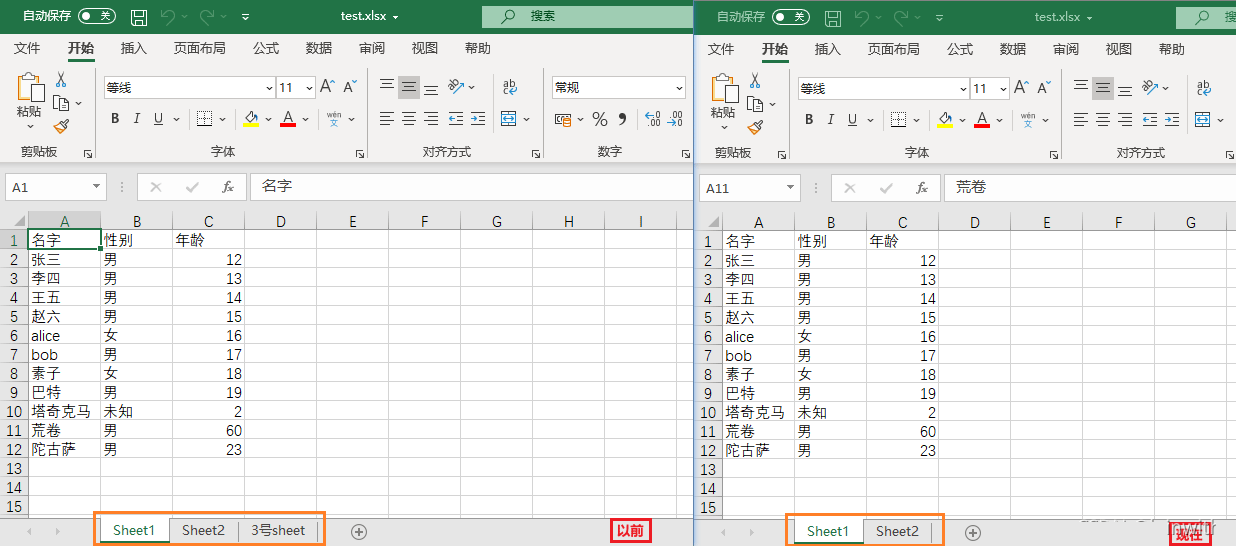
remove(“sheet名”):删除某个sheet表
要删除某sheet表,需要激活这个sheet表,即:将其作为活动表(关于活动表的定义请看前面文章开头写的有)下面8~11行代码展示了原始活动表与手动更换活动表,第13行代码删掉活动表
import os
import openpyxl
path = r"C:\Users\asuka\Desktop"
os.chdir(path) # 修改工作路径
workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
sheet = workbook['3号sheet'] # 手动切换到要删除的sheet表,一旦切换,这张表就是活动表
print('当前活动表是:' + str(sheet))
workbook.remove(sheet) # 删除当前活动表
print(workbook.sheetnames)
workbook.save('test.xlsx')
'''
当前活动表是:<Worksheet "Sheet1">
当前活动表是:<Worksheet "3号sheet">
['Sheet1', 'Sheet2']
'''
操作多个Excel表
其实想用openpyxl玩这个,但是网上用的是别的库,就有点无语,以后熟练的话在自己写一个函数实现吧
背景知识
numpy与pandas:
NumPy是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库;pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的,我们需要利用Pandas进行Excel的合并
下面的代码生成了一个5行3列的包含15个字符的嵌套列表
(注意,第4行代码:15是等于35的,如果是15对应43,或者16对应5*3都会报错)
(注意,第5行代码,虽然5行3列是15个数据,但是可以指定数据从1开头,到16结束)
import numpy as np import pandas as pd xx = np.arange(15).reshape(5, 3) yy = np.arange(1, 16).reshape(5, 3) print(xx) print(yy) ''' [[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11] [12 13 14]] [[ 1 2 3] [ 4 5 6] [ 7 8 9] [10 11 12] [13 14 15]] '''
添加表头
使用pandas库的DataFrame来添加表头。关于打印的结果,把最左侧的一列去掉之后会发现结果很和谐,这是因为最左侧的一列代表行号。此时xx变量的类型是<class ‘pandas.core.frame.DataFrame’>
import numpy as np import pandas as pd xx = np.arange(15).reshape(5, 3) yy = np.arange(1, 16).reshape(5, 3) xx = pd.DataFrame(xx, columns=["语文", "数学", "外语"]) yy = pd.DataFrame(yy, columns=["语文", "数学", "外语"]) print(xx) print(yy) ''' 结果: 语文 数学 外语 0 0 1 2 1 3 4 5 2 6 7 8 3 9 10 11 4 12 13 14 语文 数学 外语 0 1 2 3 1 4 5 6 2 7 8 9 3 10 11 12 4 13 14 15 '''
合并两个矩阵
pd.concat(list)括号中传入的是一个列表;ignore_list=True表示忽略原有索引,重新生成一组新的索引;
或者直接可以写成z = pd.concat([xx,yy],ignore_list=True);
不知道为什么失败,暂时搁浅
xlsxwriter
xlsxwriter模块一般是和xlrd模块搭配使用的,
xlsxwriter:负责写入数据,
xlrd:负责读取数据。
创建一个工作簿
import xlsxwriter
import os
path = r"C:\Users\asuka\Desktop"
os.chdir(path)
# 这一步相当于创建了一个新的"工作簿";
# "demo.xlsx"文件不存在,表示新建"工作簿";
# "demo.xlsx"文件存在,表示新建"工作簿"覆盖原有的"工作簿";
workbook = xlsxwriter.Workbook("demo.xlsx")
# close是将"工作簿"保存关闭,这一步必须有,否则创建的文件无法显示出来。
workbook.close()创建sheet表
import xlsxwriter
import os
path = r"C:\Users\asuka\Desktop"
os.chdir(path)
workbook = xlsxwriter.Workbook("cc.xlsx") # 创建一个名为cc.xlsx的文件
worksheet = workbook.add_worksheet("2018年销售量") # 创建一个名为“2018年销售量”的sheet表
workbook.close()写入数据
import xlsxwriter
import os
path = r"C:\Users\asuka\Desktop"
os.chdir(path)
# 创建一个名为【demo.xlsx】工作簿;
workbook = xlsxwriter.Workbook("demo.xlsx")
# 创建一个名为【2018年销售量】工作表;
worksheet = workbook.add_worksheet("2018年销售量")
# 使用write_row方法,为【2018年销售量】工作表,添加一个表头;
headings = ['产品', '销量', "单价"]
worksheet.write_row('A1', headings)
# 使用write方法,在【2018年销售量】工作表中插入一条数据;
# write语法格式:worksheet.write(行,列,数据)
data = ["苹果", 500, 8.9]
for i in range(len(headings)):
worksheet.write(1, i, data[i])
workbook.close()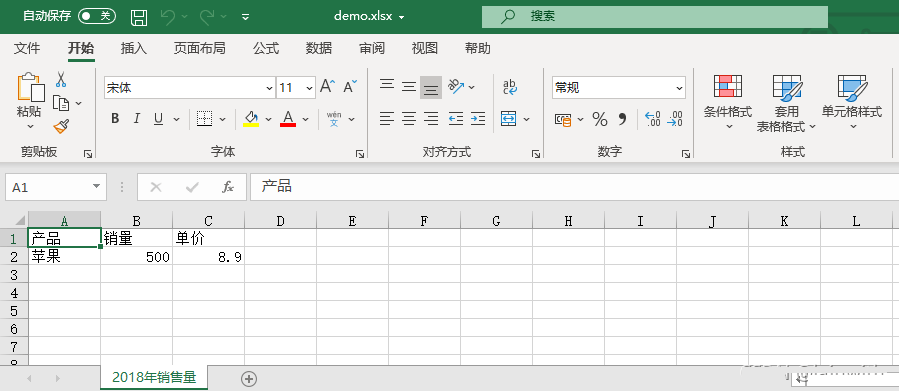
加载全部内容