正则表达式匹配img标签图片地址
阿熊 人气:0前言
有玩过爬虫的人应该都有过在又臭又长的HTML中找寻信息的经历,虽然有各种工具和各种框架可以辅助查找,但是解析HTML的规则也是人想的,制定规则也是十分麻烦的。
恰好在个人的项目中,需要从某个网站中爬取图片,好在需求比较简单,所以试着使用正则表达式来解决。
分析
每个网站中展示图片的地方,无非就是img标签或者style中background-image和background,先解决img标签中的图片。
首先,地址在标签的src属性之中,所以找寻src的位置是必须的。但是不只有img标签拥有src属性,video和style也同样拥有src属性。因此,只匹配src的位置是不够,还得确保这个src的位置在img标签中。
然后,就是匹配src后面的地址,匹配地址的方法已经有许多文章描述过了,不再多说,但本文中用了一个比较取巧的方式去匹配。
总的思路就是先匹配src的位置,在获取图片地址。
正则表达式
- 首先是匹配src的位置,既然是找位置,那就需要用的正则表达式中预查(?),因为需要的图片地址是在src后面,所以用反向肯定预查,所以初步确定正则表达式可写成:
/(?<=判断条件)/ 至于反向肯定预查的判断条件,就是在img之后的src,所以正则表达式改成如下: /(?<=(img src="))/ 之所以匹配src=", 是因为想要直接就匹配到地址的开头位置,于是就顺手加上。
但是,因为img和src之间可能还存在class或者其他自定义属性,所以还要加上这些可能存在字符的匹配。但是因为这些字符的种类比较多,如双引号"",英文、数字、甚至是中文等等,一一匹配过于麻烦,有个取巧的方式就是匹配非>。
众所周知,>在HTML中是一个标签的结尾,所以它不可能出现在img标签内的img字符和src字符的中间,所以匹配位置的正则表达式可写成: /(?<=(img[^>]*src="))/
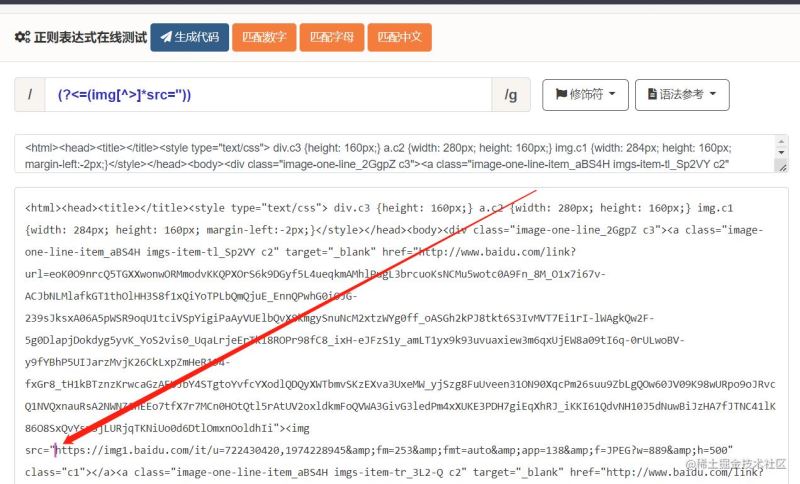
可以看到,能够成功找到图片地址的开头位置。
- 既然位置找到了,那剩下的就是匹配地址了。这里可以使用其他相关文章说的匹配地址的正则表达式,但是和上面一样,同样可以取巧。
在HTML标签中,图片地址是以双引号"开头和结尾的,上面的匹配位置已经匹配到图片开头的双引号之后,那么图片地址还剩下一个双引号,就是结尾的那个。
那么,直接匹配所有连续不为"的字符不就可以了,思路可能有点复杂,但是写起来简单:
/[^"]*/
- 因此,总的正则表达式为:
/(?<=(img[^>]*src="))[^"]*/g结尾加个g是表示匹配所有符合条件的字符串,现在就可以匹配出图片地址了:
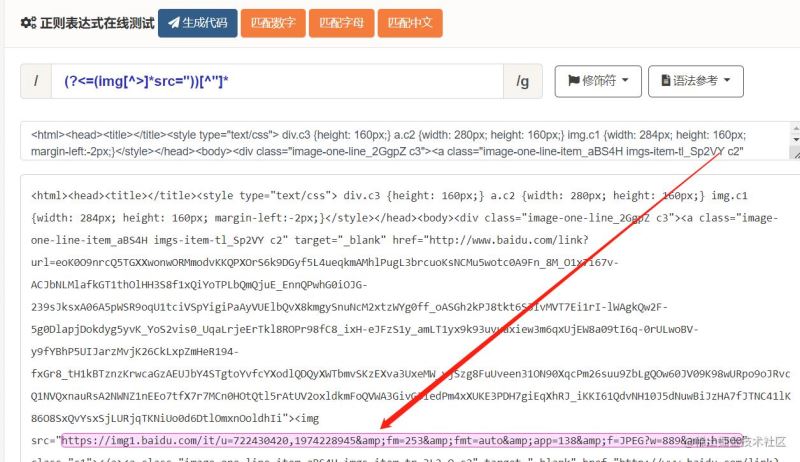
总结
加载全部内容