Python Pandas数据分析
海拥 人气:0Pandas是最流行的用于数据分析的 Python 库。它提供高度优化的性能,后端源代码完全用C或Python编写。
我们可以通过以下方式分析 pandas 中的数据:
1.Series
2.数据帧
Series
Series 是 pandas 中定义的一维(1-D)数组,可用于存储任何数据类型。
代码 #1
创建 Series
# 创建 Series 的程序 # 导入 Panda 库 import pandas as pd # 使用数据和索引创建 Series a = pd.Series(Data, index = Index)
在这里,数据可以是:
- 一个标量值,可以是 integerValue、字符串
- 可以是键值对的Python 字典
- 一个Ndarray
注意:默认情况下,索引从 0、1、2、...(n-1) 开始,其中 n 是数据长度。
代码 #2
当 Data 包含标量值时
# 使用标量值创建 Series 的程序 # 数值数据 Data =[1, 3, 4, 5, 6, 2, 9] # 使用默认索引值创建系列 s = pd.Series(Data) # 预定义的索引值 Index =['a', 'b', 'c', 'd', 'e', 'f', 'g'] # 创建具有预定义索引值的系列 si = pd.Series(Data, Index)
输出:

具有默认索引的标量数据

带索引的标量数据
代码#3
当数据包含字典时
# 创建词典 Series 程序
dictionary ={'a':1, 'b':2, 'c':3, 'd':4, 'e':5}
# 创建字典类型 Series
sd = pd.Series(dictionary)
输出:
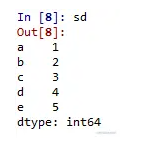
字典类型数据
代码 #4
当 Data 包含 Ndarray
# 创建 ndarray series 的程序 # 定义二维数组 Data =[[2, 3, 4], [5, 6, 7]] # 创建一系列二维数组 snd = pd.Series(Data)
输出:

数据作为 Ndarray
数据框
DataFrames是 pandas 中定义的二维(2-D)数据结构,由行和列组成。
代码 #1
创建 DataFrame
# 创建 DataFrame 的程序 # 导入库 import pandas as pd # 使用数据创建 DataFrame a = pd.DataFrame(Data)
在这里,数据可以是:
- 一本或多本词典
- 一个或多个Series
- 2D-numpy Ndarray
代码 #2
当数据是字典时
# 使用两个字典创建数据框的程序
# 定义字典 1
dict1 ={'a':1, 'b':2, 'c':3, 'd':4}
# 定义字典 2
dict2 ={'a':5, 'b':6, 'c':7, 'd':8, 'e':9}
# 用 dict1 和 dict2 定义数据
Data = {'first':dict1, 'second':dict2}
# 创建数据框
df = pd.DataFrame(Data)
输出:
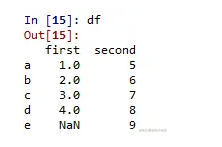
带有两个字典的 DataFrame
代码 #3
当数据是Series时
# 创建三个系列的Dataframe的程序
import pandas as pd
# 定义 series 1
s1 = pd.Series([1, 3, 4, 5, 6, 2, 9])
# 定义 series 2
s2 = pd.Series([1.1, 3.5, 4.7, 5.8, 2.9, 9.3])
# 定义 series 3
s3 = pd.Series(['a', 'b', 'c', 'd', 'e'])
# 定义 Data
Data ={'first':s1, 'second':s2, 'third':s3}
# 创建 DataFrame
dfseries = pd.DataFrame(Data)
输出:

三个 Series 的 DataFrame
代码 #4
当 Data 为 2D-numpy ndarray注意:在创建 2D 数组的 DataFrame 时必须保持一个约束 - 2D 数组的维度必须相同。
# 从二维数组创建 DataFrame 的程序
# 导入库
import pandas as pd
# 定义 2d 数组 1
d1 =[[2, 3, 4], [5, 6, 7]]
# 定义 2d 数组 2
d2 =[[2, 4, 8], [1, 3, 9]]
# 定义 Data
Data ={'first': d1, 'second': d2}
# 创建 DataFrame
df2d = pd.DataFrame(Data)
输出:

带有 2d ndarray 的 DataFrame
加载全部内容