MySQL子查询
ppppppatrick 人气:00.概念
子查询:一个查询语句嵌套在另一个查询语句内部
1.需求分析与问题解决
1.1提出具体问题:
# 法一:效率低
SELECT last_name,salary
FROM employees
WHERE last_name = 'ABEL'
SELECT last_name,salary
FROM employees
WHERE salary > 11000;
#法二:自连接
SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e2.`salary` > e1.`salary`
AND e1.`last_name` = 'Abel';
#法三:子查询
SELECT last_name,salary
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE last_name = 'ABEL'
);
# 称谓的规范:外查询(主查询),内查询(子查询)1.2 子查询的基本使用: 子查询的基本语法结构:

子查询(内查询)在主查询之前一次执行完成。
子查询的结果被主查询(外查询)使用 。
注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
1.3 子查询的分类
角度一:从内查询返回结果的条目数
| 单行子查询 | 多行子查询 |
|---|---|
| 子查询结果只有一个数据 | 子查询数据返回多个 |
角度二:内查询是否被执行多次
| 相关子查询 | 不相关子查询 |
|---|---|
| 查询工资大于本部门平均工资的员工信息 | 查询工资大于本公司平均工资的员工信息 |
2.单行子查询
| 操作符 | 含义 |
|---|---|
| = | equal to |
| > | greater than |
| >= | greater than or equal to |
| < | less than |
| <= | less than or equal to |
| <> | not equal to |
2.1实例:
# 查询工资大于149号员工工资的信息
SELECT salary,last_name,employee_id
FROM employees
WHERE salary > (
SELECT salary
FROM employees
WHERE employee_id = 149
);
# 返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (SELECT job_id
FROM employees
WHERE employee_id = 141)
AND
salary > (SELECT salary
FROM employees
WHERE employee_id = 143
);
# 返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name,job_id,salary
FROM employees
WHERE salary = (
SELECT MIN(salary)
FROM employees
);
# 查询与141号员工的manager_id和department_id相同的其他员工的employee_id,
# manager_id,department_id
SELECT employee_id,manager_id,department_id
FROM employees
WHERE
manager_id = (SELECT manager_id
FROM employees
WHERE employee_id = 141)
AND
department_id =(SELECT department_id
FROM employees
WHERE employee_id = 141)
AND
employee_id <> 141;
#方式二:成对查询
SELECT employee_id,manager_id,department_id
FROM employees
WHERE (manager_id,department_id) = (
SELECT manager_id,department_id
FROM employees
WHERE employee_id = 141
)
AND employee_id <> 141;
# 查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT MIN(salary),department_id,salary
FROM employees
GROUP BY department_id
HAVING MIN(salary) > (
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
)
ORDER BY MIN(salary) DESC;
# 题目:显式员工的employee_id,last_name和location。
# 其中,若员工department_id与location_id为1800
# 的department_id相同,则location为'Canada',其余则为'USA'。
SELECT employee_id,last_name,
CASE department_id
WHEN ( SELECT department_id
FROM departments
WHERE location_id = 1800) THEN 'Canada'
ELSE 'USA'
END "location"
FROM employees;2.2空值问题
SELECT last_name FROM employees WHERE employee_id NOT IN ( SELECT manager_id FROM employees );
内查询的结果是NULL空值,不会报错,但是也不会显示数据
2.3非法使用子查询
SELECT employee_id, last_name FROM employees WHERE salary = (SELECT MIN(salary) FROM employees GROUP BY department_id);
这里内查询返回的结果是一列数据,不能使用等于号连接,必须使用in
3.多行子查询
- 也称为集合比较子查询
- 内查询返回多行
- 使用多行比较操作符
3.1多行比较操作符
| 操作符 | 含义 |
|---|---|
| IN | 等于列表中的任意一个 |
| ANY | 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 |
| ALL | 需要和单行比较操作符一起使用,和子查询返回的所有值比较 |
| SOME | 实际上是ANY的别名,作用相同,一般常使用ANY |
3.2代码实例
SELECT employee_id, last_name FROM employees WHERE salary in (SELECT MIN(salary) FROM employees GROUP BY department_id);
返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id 以及salary
#返回其它job_id中比job_id为‘IT_PROG'部门任一工资低的员工的员工号、姓名、job_id 以及salary SELECT employee_id,last_name,job_id,salary FROM employees WHERE salary < ANY( SELECT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id <> 'IT_PROG'; #返回其它job_id中比job_id为‘IT_PROG'部门所有工资低的员工的员工号、姓名、job_id 以及salary SELECT employee_id,last_name,job_id,salary FROM employees WHERE salary < ALL( SELECT salary FROM employees WHERE job_id = 'IT_PROG' ) AND job_id <> 'IT_PROG';
查询平均工资最低的部门id
相当于创建了一张临时的表
# 聚合函数不能嵌套,单行函数才能嵌套使用 SELECT employee_id FROM employees GROUP BY department_id HAVING AVG(salary) = (SELECT MIN(avg_sal) FROM ( SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id )t_dept_avg_sal); #方式二 SELECT employee_id FROM employees GROUP BY department_id HAVING AVG(salary) <= ALL( SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id );
3.3空值问题
SELECT last_name FROM employees WHERE employee_id NOT IN ( SELECT manager_id FROM employees #where manager_id is not null );
4.相关子查询
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 .相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
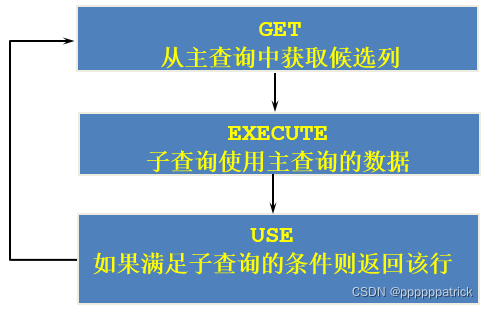

4.1代码实例
题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
#回顾:查询员工中工资大于本公司平均工资的员工的last_name,salary和其department_id SELECT last_name,salary,department_id FROM employees e1 WHERE salary > ( SELECT AVG(salary) FROM employees e2 ); #题目:查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id SELECT last_name,salary,department_id FROM employees e1 WHERE salary > ( SELECT AVG(salary) FROM employees e2 WHERE department_id = e1.`department_id` ); #方式二,在from中声明子查询 SELECT e.last_name,e.salary,e.department_id FROM employees e,(SELECT department_id,AVG(salary) avg_sal FROM employees GROUP BY department_id) temp WHERE e.department_id = temp.department_id AND e.salary > temp.avg_sal;
题目:查询员工的id,salary,按照department_name 排序
SELECT employee_id,salary FROM employees e1 ORDER BY ( SELECT department_name FROM departments d WHERE e1.`department_id` = d.`department_id` );
题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
#若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同 #id的员工的employee_id,last_name和其job_id SELECT employee_id,last_name,job_id FROM employees e WHERE 2 <= (SELECT COUNT(*) FROM job_history j WHERE e.`employee_id` = j.`employee_id` );
4.2结论:
在哪里可以写子查询:
在select中,除了GROUP BY 和 LIMIT之外,其他位置都可以声明子查询
4.3EXISTS 与 NOT EXISTS关键字
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行:
- 条件返回 FALSE
- 继续在子查询中查找
如果在子查询中存在满足条件的行: - 不在子查询中继续查找
- 条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
题目:查询departments表中,不存在于employees表中的部门的department_id和department_name
#方式一:自连接 SELECT DISTINCT e1.employee_id,e1.last_name,e1.job_id,e1.department_id FROM employees e1 JOIN employees e2 WHERE e1.`employee_id` = e2.`manager_id` #方式二:子查询 SELECT DISTINCT manager_id FROM employees SELECT employee_id,last_name,job_id,department_id FROM employees WHERE employee_id IN ( SELECT DISTINCT manager_id FROM employees ) #方式三:exists SELECT employee_id,last_name,job_id,department_id FROM employees e1 WHERE EXISTS ( SELECT * FROM employees e2 WHERE e1.`employee_id`= e2.`manager_id` )
查询departments表中,不存在于employees表中的部门的department_id和department_name
#方式一: SELECT d.department_id,d.department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id WHERE e.department_id IS NULL; #方式二: SELECT department_id,department_name FROM departments d WHERE NOT EXISTS ( SELECT * FROM employees e WHERE d.`department_id` = e.`department_id` );
5.相关更新
UPDATE table1 alias1 SET column = (SELECT expression FROM table2 alias2 WHERE alias1.column = alias2.column);
使用相关子查询依据一个表中的数据更新另一个表的数据。
题目:在employees中增加一个department_name字段,数据为员工对应的部门名称
# 1) ALTER TABLE employees ADD(department_name VARCHAR2(14)); # 2) UPDATE employees e SET department_name = (SELECT department_name FROM departments d WHERE e.department_id = d.department_id);
5.相关删除
DELETE FROM table1 alias1 WHERE column operator (SELECT expression FROM table2 alias2 WHERE alias1.column = alias2.column);
使用相关子查询依据一个表中的数据删除另一个表的数据.
题目:删除表employees中,其与emp_history表皆有的数据
DELETE FROM employees e WHERE employee_id in (SELECT employee_id FROM emp_history WHERE employee_id = e.employee_id);
问题:谁的工资比Abel的高?
解答:
#方式1:自连接 SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e1.last_name = 'Abel' AND e1.`salary` < e2.`salary` #方式2:子查询 SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
问题:以上两种方式有好坏之分吗?
解答:自连接方式好!
题目中可以使用子查询,也可以使用自连接。一般情况建议你使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
可以这样理解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。
总结
加载全部内容