Python pandas.read_csv() 读取 csv
海拥 人气:0前言:
Python 是一种用于进行数据分析的出色语言,主要是因为以数据为中心的 Python 包的奇妙生态系统。Pandas 就是其中之一,它使导入和分析数据变得更加容易。
大多数用于分析的数据以表格格式的形式提供,例如 Excel 和逗号分隔文件 (CSV)。要访问 csv 文件中的数据,我们需要一个函数 read_csv() 以数据框的形式检索数据。在使用这个功能之前,我们必须导入 pandas 库。
导入 Pandas 库:
import pandas as pd
read_csv() 函数用于从 csv 文件中检索数据。read_csv() 方法的语法是:
pd.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None, engine=None, converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer',
thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None,
encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0,
doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None) 代码 #1 从 csv 文件中检索数据
# Import pandas
import pandas as pd
# 读取csv文件
pd.read_csv("filename.csv")这是带有默认值的参数列表。并非所有这些都很重要,但记住这些实际上可以节省自己执行某些功能的时间。通过在 jupyter notebook 中按 shift + tab 可以查看任何函数的参数。
下面给出了有用的和它们的用法:
- filepath_or_buffer:这是要使用此函数检索的文件的位置。它接受文件的任何字符串路径或 URL。
- sep:表示分隔符,默认为 ', ',如 csv(逗号分隔值)。
- header:它接受 int、int 列表、行号用作列名和数据的开头。如果没有传递名称,即header=None,那么它将显示第一列为0,第二列显示为1,以此类推。
- usecols:用于仅从 csv 文件中检索选定的列。
- nrows:表示要从数据集中显示的行数。
- index_col:如果没有,则没有索引号与记录一起显示。
- 挤压:如果为真且仅传递一列,则返回熊猫系列。
- skiprows:跳过新数据框中传递的行。
- 名称:它允许检索具有新名称的列。
| 范围 | Use |
|---|---|
| filepath_or_buffer | 文件的 URL 或目录位置 |
| sep | 代表分隔符,默认为 ', ' 如 csv(逗号分隔值) |
| index_col | 将传递的列作为索引而不是 0、1、2、3…r 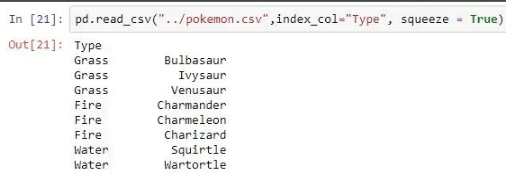 |
| header | 将传递的 row/s[int/int list] 作为标题 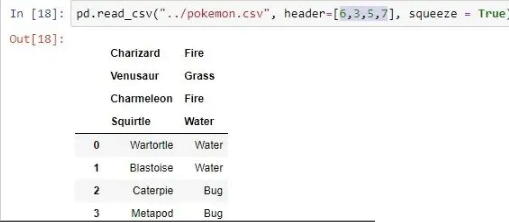 |
| use_cols | 仅使用传递的 col[string list] 来制作数据框 |
| squeeze | 如果为 true 且仅传递一列,则返回 pandas 系列 |
| skiprows | 跳过新数据框中传递的行 |
Code #2 :
# 导入 Pandas 库
import pandas as pd
pd.read_csv(filepath_or_buffer = "pokemon.csv")
# 使传递的行标题
pd.read_csv("pokemon.csv", header =[1, 2])
# 将传递的列作为索引而不是 0、1、2、3....
pd.read_csv("pokemon.csv", index_col ='Type')
# 仅将传递的 cols 用于数据框
pd.read_csv("pokemon.csv", usecols =["Type"])
# 如果只有一列,则返回熊猫系列
pd.read_csv("pokemon.csv", usecols =["Type"], squeeze = True)
# 跳过新系列中传递的行
pd.read_csv("pokemon.csv", skiprows = [1, 2, 3, 4])加载全部内容