go按行读取文件
CK持续成长 人气:01. 使用ioutil读取文本
// 全部读取后按换行拆分
func ReadFile1(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
readBytes, err := ioutil.ReadAll(fileHanle)
if err != nil {
return err
}
results := strings.Split(string(readBytes), "\n")
fmt.Printf("read result:%v", results)
return nil
}实现方式:使用iouitl一次性读取全部文件内容,然后使用"\n"进行分割成行。
这种实现最简单,但是只适合都内容比较小的文件,当读取大文件的时候,一次读到内存需要占用比较大的内存。
2. 使用bufio.Reader的ReadLine读取
func ReadFile2(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
reader := bufio.NewReader(fileHanle)
var results []string
// 按行处理txt
for {
line, _, err := reader.ReadLine()
if err == io.EOF {
break
}
results = append(results, string(line))
}
fmt.Printf("read result:%v\n", results)
return nil
}实现方式:使用NewReader创建bufio.Reader,循环调用Reader的ReadLine按行读取,直接读到文件结束标记EOF。
bufio.Reader封装了io, 并实现了缓冲I/O,同时它也实现了io.Reader的方法的Read方法。bufio缓冲区有默认大小是4K。
从ReadLine返回的文本不包括行尾(“\r\n”或“\n”)。
如果一行大于缓存,isPrefix 会被设置为 true,同时返回该行的开始部分(等于缓存大小的部分)。该行剩余的部分就会在下次调用的时候返回。当下次调用返回该行剩余部分时,isPrefix 将会是 false 。
bufio.Reader的ReadLine最终调用的是ReadSlice方法,而ReadSlice返回的[]byte是指向Reader 中的buffer的一个slice,而不是copy一份返回,所以读取的slice可能会被一下读取操作重新,所以官方建议是使用ReadBytes和ReadString方法。
要注意是ReadBytes和ReadString返回的结果中包含传入的界定符,如果最终结果不需要界定符的话需要自己处理。
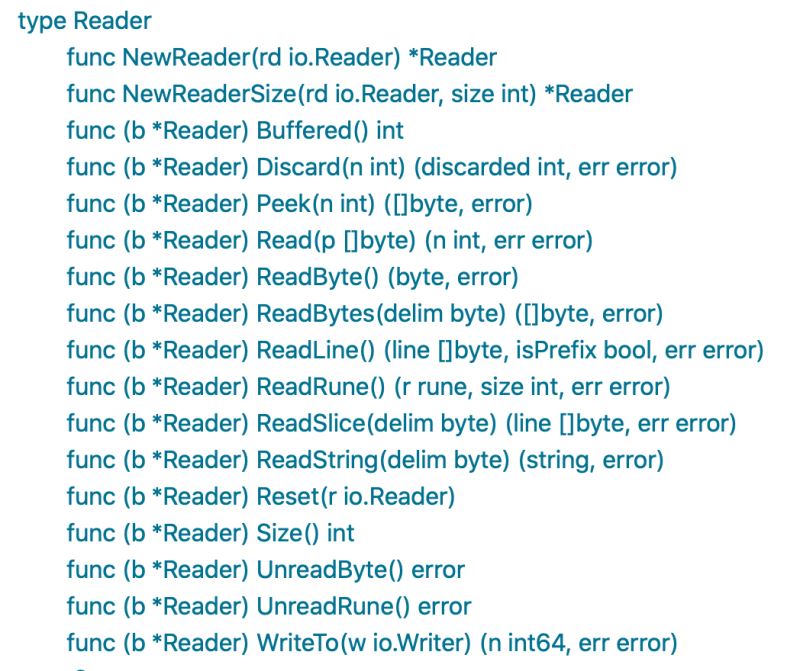
bufio.Reader除了有ReadLine按行读取外,他还封装了按指定标记分割的方法。如下图
3.使用bufio.Scanner读取
func ReadFile3(path string) error {
fileHanle,err := os.OpenFile(path, os.O_RDONLY, 0666)
if err != nil {
return err
}
defer fileHanle.Close()
scanner := bufio.NewScanner(fileHanle)
var results []string
// 按行处理txt
for scanner.Scan(){
lineTxt := strings.TrimSpace(scanner.Text())
if len(lineTxt) == 0 {
continue
}
results = append(results, lineTxt)
}
fmt.Printf("read result:%v\n", results)
return nil
}实现方式:使用NewScanner创建bufio.Scanner,使用循环调用scanner的Scan判断是否扫描到数据,然后通过scannner.Text()方法获取到扫描的字符串。
bufio.Scanner它底层封装了io.Reader, 它的实现就跟Scanner名称一样,是一个按字节流扫描的扫描器,当扫描到满足Split函数条件的字节数据后,就直接返回对应的扫描到的内容。
默认情况下,它64k行限制,如果想更大,可以自己通过Buffer函数进行设置。
Scanner默认提供了以下方法:

Scanner 类型具有 Split 函数,该函数接受 SplitFunc 函数来确定 Scanner 如何拆分给定的字节片。默认的 SplitFunc 是 ScanLines,它将返回文本的每一行,并删除行尾标记。Split的函数定义如下:
type SplitFunc func(data []byte, atEOF bool) (advance int, token []byte, err error)
我们可以自定义实现SpiteFunc来实现不同的拆分方式,比如我们可以使用bufio.ScanWords实现方式来按单词拆分,如下:
func WordCounter(){
const input = "Now is the winter of our discontent,\nMade glorious summer by this sun of York.\n"
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(bufio.ScanWords)
count := 0
for scanner.Scan() {
count++
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "reading input:", err)
}
fmt.Printf("%d\n", count)
}我可以跟踪到bufio包scan.go的文件可以看到ScanWords的实现代码如下:
func ScanWords(data []byte, atEOF bool) (advance int, token []byte, err error) {
// Skip leading spaces.
start := 0
for width := 0; start < len(data); start += width {
var r rune
r, width = utf8.DecodeRune(data[start:])
if !isSpace(r) {
break
}
}
// Scan until space, marking end of word.
for width, i := 0, start; i < len(data); i += width {
var r rune
r, width = utf8.DecodeRune(data[i:])
if isSpace(r) {
return i + width, data[start:i], nil
}
}
// If we're at EOF, we have a final, non-empty, non-terminated word. Return it.
if atEOF && len(data) > start {
return len(data), data[start:], nil
}
// Request more data.
return start, nil, nil
}该函数签名和SplitFunc定义实现一致。
总结
加载全部内容