优化sql中的orderBy
wind_huise 人气:0在使用数据库进行数据查询时,难免会遇到基于某些字段对查询的结果集进行排序的需求。在sql中通常使用orderby语句来实现。将需要排序的字段放到 该关键词后,如果有多个字段的话,就用","分割。
select * from table t order by t.column1,t.column2;
上面的sql表示查询表table中数据,然后先按照column1排序,如果column1相同的话,在按照column2排序,排序的方式默认是降序。当然排序方式也是可以指定的。在被排序字段后添加 DESC,ASE,分别表示降序和升序。
使用该orderby可以很方便的实现日常的排序操作。使用的多了,不知道你有没有遇到过这种场景:有时候使用orderby后,sql执行效率非常慢,有时候却比较快,由于整天被curd缠身,也没有时间研究,反正就是觉得很神奇。趁这个周末比较闲,就来研究下,mysql中orderby是怎么实现的。
为了方便描述,我们先建立一个数据表 t1,如下:
CREATE TABLE `t1` ( `id` int(11) NOT NULL not null auto_increment, `a` int(11) DEFAULT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) , KEY `a` (`a`) USING BTREE ) ENGINE=InnoDB;
并插入数据:
insert into t1 (a,b,c) values (1,1,3); insert into t1 (a,b,c) values (1,4,5); insert into t1 (a,b,c) values (1,3,3); insert into t1 (a,b,c) values (1,3,4); insert into t1 (a,b,c) values (1,2,5); insert into t1 (a,b,c) values (1,3,6);
为了使索引生效,插入10000行 7,7,7,无关数据,数据量少的情况下,会直接全表扫描
insert into t1 (a,b,c) values (7,7,7);
我们现在需要查找 a=1的所有记录,然后按照b字段进行排序。
查询sql为
select a,b,c from t1 where a = 1 order by b limit 2;
为了防止在查询过程中全表扫描,我们在字段a上添加了索引。
首先我们先通过语句
explain select a,b,c from t1 where a = 1 order by b lmit 2;
查看sql的执行计划,如下所示:

在extra中我们可以看到出现了Using filesort,这个表示 该sql执行过程中,执行了排序操作,排序操作在 sort_buffer中完成,sort_buffer是mysql分配给每个线程的一个内存缓冲区,该缓冲区专门用来完成排序,大小默认是1M,其大小由变量 sort_buffer_size 进行控制。
mysql在对orderby进行实现时,根据放入到sort_buffer中的字段内容不同,进行了两种不同实现方式:全字段排序和rowid排序。
全字段排序
首先我们先通过一张图整体看一下sql执行过程:
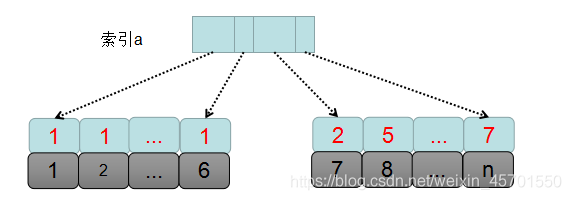
mysql先根据查询条件确定需要排序的数据集,也就是表中 a=1的数据集,即主键id从1到6的这些记录。
整个sql的执行的过程如下:
1.创建并初始化sort_buffer,并确定需要放到该缓冲区中的字段,也就是a,b,c这三个字段。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表到id索引,取出整行数据,然后从整行数据中,取出a,b,c的值,放入到sort_buffer中。
4.从索引a中按照顺序找到下一个a=1的主键id。
5.重复步骤3和步骤4,直到获取到最后一个a=1的记录,也就是主键id=5。
6.此时满足条件a=1的所有记录的 a,b,c字段,全部读放到了sort_buffer中,然后,对这些数据按照b的值进行进行排序,排序的方式是快速排序。就是那个面试经常面到的快速排序,时间复杂度为log2n的快速排序。
7.然后从排序后的结果集中取出前2行数据。
上面是就是msql中orderby的执行流程。因为放入到sort_buffer中的数据是需要输出的全部字段,所以这种排序被称为全排序。
看到这里不知道你是否会有疑问?如果需要排序的数据量很大的话,sort_buffer装不下怎么办?
的确,如果a=1的数据行特别多,且需要存放到sort_buffer中的字段比较多,可能不止a,b,c三个字段,有些业务可能需要输出更多字段。那么默认大小只有1M的sort_buffer很可能容纳不下。
当sort_buffer容纳不下的时候,mysql会创建一批临时的磁盘文件来辅助排序。默认情况下会创建12个临时文件,将需要排序的数据分成12份,每一份单独排序,形成12个内部数据有序的文件,然后把这12个有序文件在合并成一个有序的大文件,最终完成数据的排序。
基于文件的排序,相比基于内存的排序,排序效率要低很多,为了提高排序的效率,应该尽量避免基于文件的排序,要想避免基于文件排序,就需要让sort_buffer可以容纳需要排序的数据量。
所以对于sort_buffer容纳不下的情况,mysql进行了优化。就是在排序时候,降低存放到sort_buffer中的字段个数。
具体优化方式,就是下面的rowId排序
RowId 排序
在全字段排序实现中,排序的过程中,要把需要输出的字段全部放到sort_buffer中,当输出的字段比较多的时候,可以放到sort_buffer中的数据行就会变少。也就增大了sort_buffer无法容纳数据的风险,直至出现基于文件的排序。
rowId排序对全字段排序的优化手段,主要是减少了放到sort_buffer中字段个数。
在rowId排序中,只会将需要排序的字段和主键Id放到sort_buffer中。
select a,b,c from t1 where a = 1 order by b limit 2;
在rowId的排序中的执行流程如下:
1.初始化并创建sort_buffer,并确认要放入的的字段,id和b。
2.从索引树a中找到第一个满足a=1的主键id,也就是id=1。
3.回表主键索引id,取出整行数据,从整行数据中取出id和b,存入sort_buffer中。
4.从索引a中取出下一条满足a=1的 记录的主键id。
5.重复步骤3和4,直到最后一个满足a=1的主键id,也就是a=6。
6.对sort_buffer中的数据,按照字段b排序。
7.从sort_buffer中的有序数据集中,取出前2个,因为此时取出的数据只有id和b,要想获取a和c字段,需要根据id字段,回表到主键索引中取出整行数据,从整行数据中获取需要的数据。
根据rowId排序的执行步骤,可以发现:相比全字段排序,rowId排序的实现方式,减少了存放到sort_buffer中的数据量,降低了基于文件的外部排序的可能性。
那rowid排序有不足的地方吗?肯定有的,要不然全字段排序就没有存在的意义了。rowid排序不足之处在于,在最后的步骤7中,增加了回表的次数,不过这个回表的次数,取决于limit后的值,如果返回的结果集比较小的话,回表的次数还是比较小的。
mysql是如何在全字段排序和rowId排序的呢?其实是根据存放的sort_buffer中每行字段的长度决定的,如果mysql认为每次放到sort_buffer中的数据量很大的话,那么就用rowId排序实现,否则使用全字段排序。那么多大算大呢?这个大小的阈值有一个变量的值来决定,这个变量就是 max_length_for_sort_data。如果每次放到sort_buffer中的数据大小大于该字段值的话,就使用rowId排序,否则使用全字段排序。
orderby的优化
上面讲述了orderby的两种排序的方式,以及一些优化策略,优化的目的主要就是避免基于磁盘文件的外部排序。因为基于磁盘文件的排序效率要远低于基于sort_buffer的内存排序。
但是当数据量比较大的时候,即使sort_buffer比较大,所有数据全部放在内存中排序,sql的整体执行效率也不高,因为排序这个操作,本身就是比较消耗性能的。
试想,如果基于索引a获取到所有a=1的数据,按照字段b,天然就是有序的,那么就不用执行排序操作,直接取出来的数据,就是符合结果的数据集,那么sql的执行效率就会大幅度增长。
其实要实现整个sql执行过程中,避免排序操作也不难,只需要创建一个a和b的联合索引即可。
alter table t1 add index a_b (a,b);
添加a和b的联合索引后,sql执行流程就变成了:
1.从索引树(a,b)中找到第一个满足a=1的主键id,也就是id=1。
2.回表到主键索引树,取出整行数据,并从中取出a,b,c,直接作为结果集的一部分返回。
3.从索引树(a,b)上取出下一个满足a=1的主键id。
4.重复步骤2和3,直到找到第二个满足a=1的主键id,并回表获取字段a,b,c。
此时我们可以通过查看sql的执行计划,来判断sql的执行过程中是否执行了排序操作。
explain select a,b from t1 where a = 1 order by b lmit 2;

通过查看执行计划,我们发现extra中已经没有了using filesort了,也就是没有执行排序操作了。
其实还可以通过覆盖索引,对该sql进一步优化,通过在索引中覆盖字段c,来避免回表的操作。
alter table t1 add index a_b_c (a,b,c);
添加索引a_b_c后,sql的执行过程如下:
1.从索引树(a,b,c)中找到第一个满足a=1的索引,从中取出a,b,c。直接作为结果集的一部分直接返回。
2.从索引(a,b,c)中取出下一个,满足a=1的记录作为结果集的一部分。
3.重复执行步骤2,直到查到第二个a=1或者不满足a=1的记录。
此时通过查看执行sql的的还行计划可以发现 extra中只有 Using index。
explain select a,b from t1 where a = 1 order by b lmit 2;

总结
通过对该sql的多次优化,sql的最终执行效率和没有排序的普通sql的查询效率基本是一样的。之所以可以避免orderby的排序操作,就是利用了索引天然有序的特点。
但是我们都知道,索引可以加快查询的效率,但是索引的维护成本比较大,对数据表中数据的新增和修改都会涉及索引的变动,所以索引也不是越多越好,有时候,并不能因为一些不常用的查询和排序,而增加了过多的索引,得不偿失。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容