Pandas DataFrame 重新索引
iter_better 人气:0Pandas DataFrame之重新索引
1.reindex可以对行和列索引
默认对行索引,加上关键字columns对列索引。
import pandas as pd data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]] df = pd.DataFrame(data,index=['d','b','c','a']) print(df)
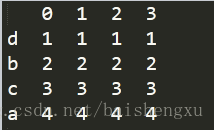
默认对列索引:如果是新的索引名将会用NaN
df=df.reindex(['a','b','c','d','e']) print(df)
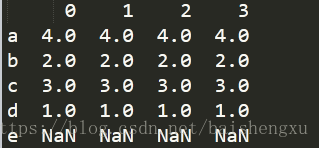
加上关键字columns对列重新索引:
df=df.reindex(columns=[2,1,3,4,0]) print(df)
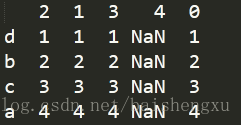
2.reindex插值处理
对于index为有序的数据,我们有时候可能会进行一些插值处理,只需要在reindex加上method参数即可,参数如下表

(图片来源:截图于 利用python进行数据分析 Wes McKinney 著)
例子:
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3]]
df = pd.DataFrame(data,index=range(3))
print(df)
df=df.reindex([0,1,2,3,4,5],method='ffill')
print('--------------')
print(df)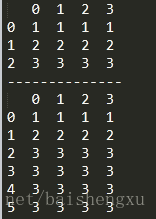
reindex函数的相关参数:

(图片来源:截图于 利用python进行数据分析 Wes McKinney 著)
Pandas DataFrame重置索引案例
import pandas as pd import numpy as np a=pd.DataFrame(np.random.randint(1,10,20).reshape(4,5)) print(a) 0 1 2 3 4 0 1 3 2 7 6 1 8 2 2 7 2 2 2 6 6 2 5 3 4 1 6 8 9 b=a.sort_values(by=4) print(b) 0 1 2 3 4 1 8 2 2 7 2 2 2 6 6 2 5 0 1 3 2 7 6 3 4 1 6 8 9 ### 重置索引:方法1 c=a.sort_values(by=4,ignore_index=True) print(c) 0 1 2 3 4 0 8 2 2 7 2 1 2 6 6 2 5 2 1 3 2 7 6 3 4 1 6 8 9 ### 重置索引:方法2 d=b.reset_index(drop=True) print(d) 0 1 2 3 4 0 8 2 2 7 2 1 2 6 6 2 5 2 1 3 2 7 6 3 4 1 6 8 9
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容