Python 条形码查询商品信息
Socialphobia_FOGO 人气:0提前说明,由于博文重在讲解,代码一体性有一定程度的破坏。如想要省事需要完整代码请至一下链接下载:完整代码下载
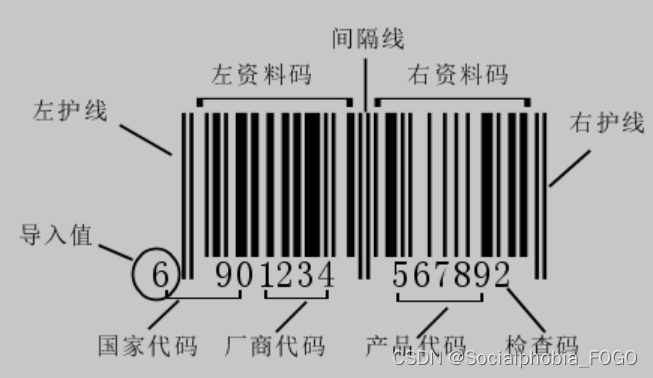
一 商品条形码
平日大家会购买许许多多的商品,无论是饮料、食品、药品、日用品等在商品的包装上都会有条形码。
商品条形码包括零售商品、非零售商品、物流单元、位置的代码和条码标识。我国采用国际通用的商品代码及条码标识体系,推广应用商品条形码,建立我国的商品标识系统。
零售商品是指在零售端通过POS扫描结算的商品。其条码标识由全球贸易项目代码(GTIN)及其对应的条码符号组成。零售商品的条码标识主要采用EAN/UPC条码。一听啤酒、一瓶洗发水和一瓶护发素的组合包装都可以作为一项零售商品卖给最终消费者。
总的来讲就是每一种在市面流通的商品都会有属于自己商品条形码。
二 查询商品条形码的目的
从技术方面来讲,本次利用Python通过商品条形码查询商品信息是为了练习爬虫技术。
从生活方面来讲,本次项目可以查询购买商品的信息,确保商品来源与成分可靠。
三 Python实现
3.1 爬取网站介绍
网站链接如下:条形码查询网站
网站截图如下:
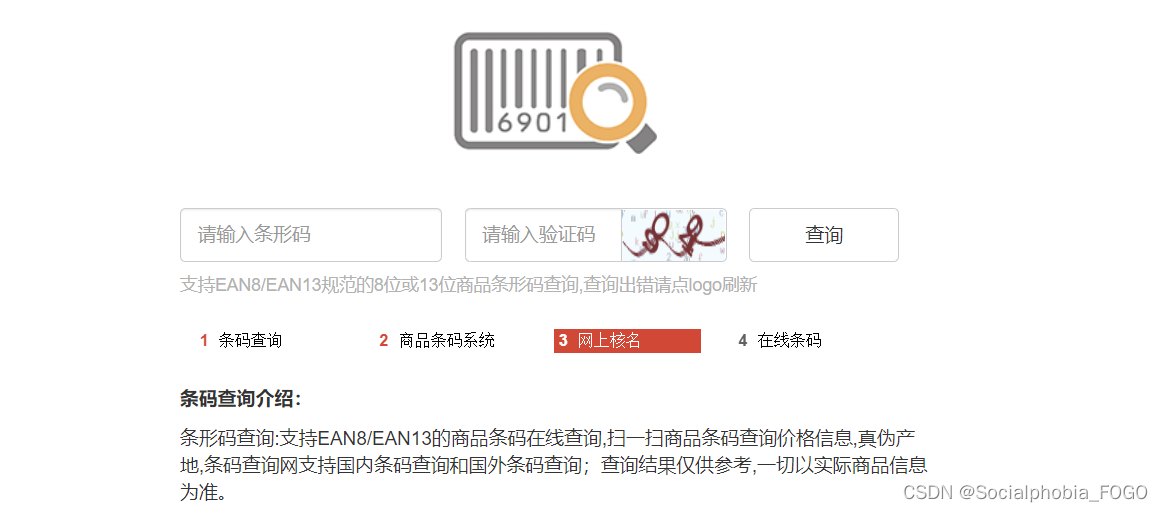
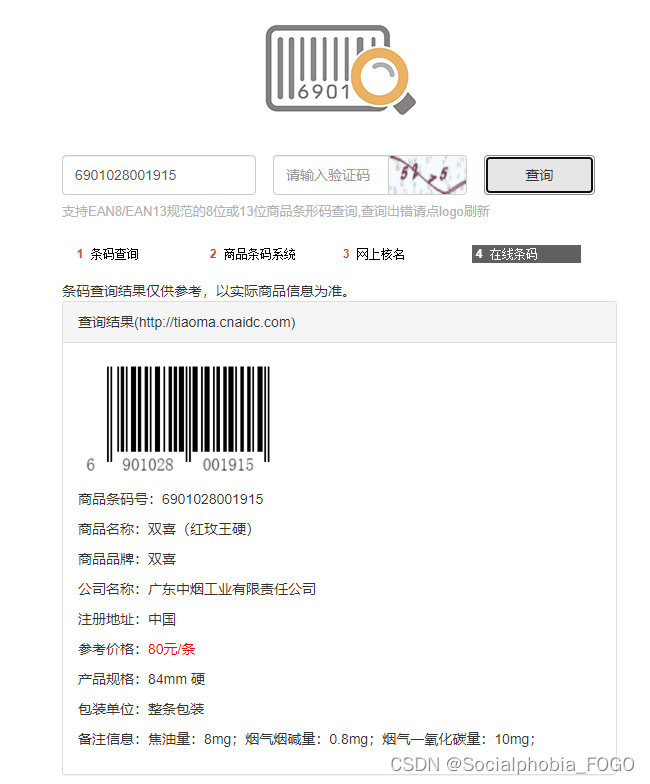
可以看到在该网站中输入某一商品的条形码,后输入验证码。点击查询即可查询到商品信息。以“6901028001915”为例,进行一次查询,截图如下:
3.2 python代码实现
3.2.1 日志模块
为保存操作记录在项目中添加日志模块,代码如下:
import logging
import logging.handlers
'''
日志模块
'''
LOG_FILENAME = 'msg_seckill.log'
logger = logging.getLogger()
def set_logger():
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(process)d-%(threadName)s - '
'%(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
file_handler = logging.handlers.RotatingFileHandler(
LOG_FILENAME, maxBytes=10485760, backupCount=5, encoding="utf-8")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
set_logger()
3.2.2 查询模块
有上面的截图可以看到,网站查询需要数字验证码验证,因此这里使用ddddocr包来识别验证码。导入相应的包:
from logging import fatal import ddddocr import requests import json import os import time import sys from msg_logger import logger
接下来是项目的主体代码,整个操作逻辑代码注释中有详细讲解:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'}
path = os.path.abspath(os.path.dirname(sys.argv[0]))
# json化
def parse_json(s):
begin = s.find('{')
end = s.rfind('}') + 1
return json.loads(s[begin:end])
# 创建目录
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
isExists=os.path.exists(path)
# 判断结果
if not isExists:
os.makedirs(path)
logger.info(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
logger.info(path + ' 目录已存在')
return False
# 爬取 "tiaoma.cnaidc.com" 来查找商品信息
def requestT1(shop_id):
url = 'http://tiaoma.cnaidc.com'
s = requests.session()
# 获取验证码
img_data = s.get(url + '/index/verify.html?time=', headers=headers).content
with open('verification_code.png','wb') as v:
v.write(img_data)
# 解验证码
ocr = ddddocr.DdddOcr()
with open('verification_code.png', 'rb') as f:
img_bytes = f.read()
code = ocr.classification(img_bytes)
logger.info('当前验证码为 ' + code)
# 请求接口参数
data = {"code": shop_id, "verify": code}
resp = s.post(url + '/index/search.html',headers=headers,data=data)
resp_json = parse_json(resp.text)
logger.info(resp_json)
# 判断是否查询成功
if resp_json['msg'] == '查询成功' and resp_json['json'].get('code_img'):
# 保存商品图片
img_url = ''
if resp_json['json']['code_img'].find('http') == -1:
img_url = url + resp_json['json']['code_img']
else:
img_url = resp_json['json']['code_img']
try:
shop_img_data = s.get(img_url, headers=headers, timeout=10,).content
# 新建目录
mkdir(path + '\\' + shop_id)
localtime = time.strftime("%Y%m%d%H%M%S", time.localtime())
# 保存图片
with open(path + '\\' + shop_id + '\\' + str(localtime) +'.png','wb') as v:
v.write(shop_img_data)
logger.info(path + '\\' + shop_id + '\\' + str(localtime) +'.png')
except requests.exceptions.ConnectionError:
logger.info('访问图片URL出现错误!')
if resp_json['msg'] == '验证码错误':
requestT1(shop_id)
return resp_json
3.2.3 运行结果
if __name__ == "__main__":
try:
dict_info = requestT1('6901028001915')['json']
print(dict_info['code_sn'])
print(dict_info['code_name'])
print(dict_info['code_company'])
print(dict_info['code_address'])
print(dict_info['code_price'])
except:
print('商品无法查询!')
尝试运行代码,以“6901028001915”为例,查看运行结果:
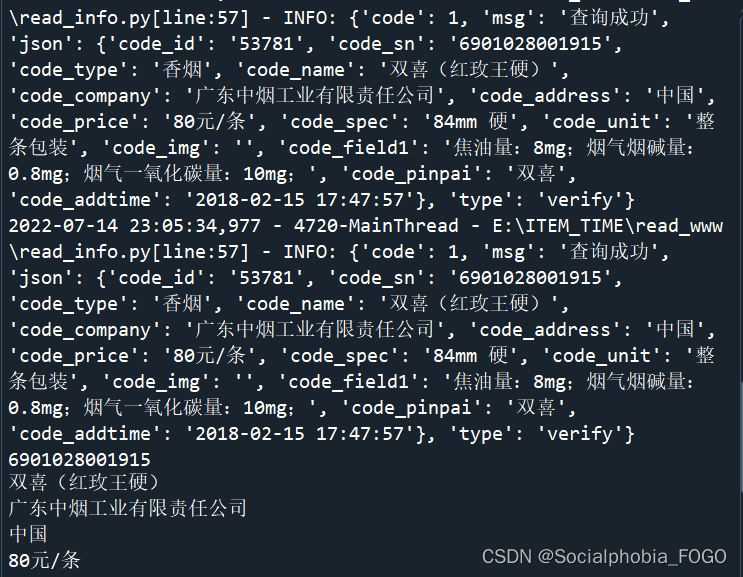
可见商品的信息成功查询出来。
加载全部内容