python百度翻译
叫我阿杰 人气:0一、分析网页
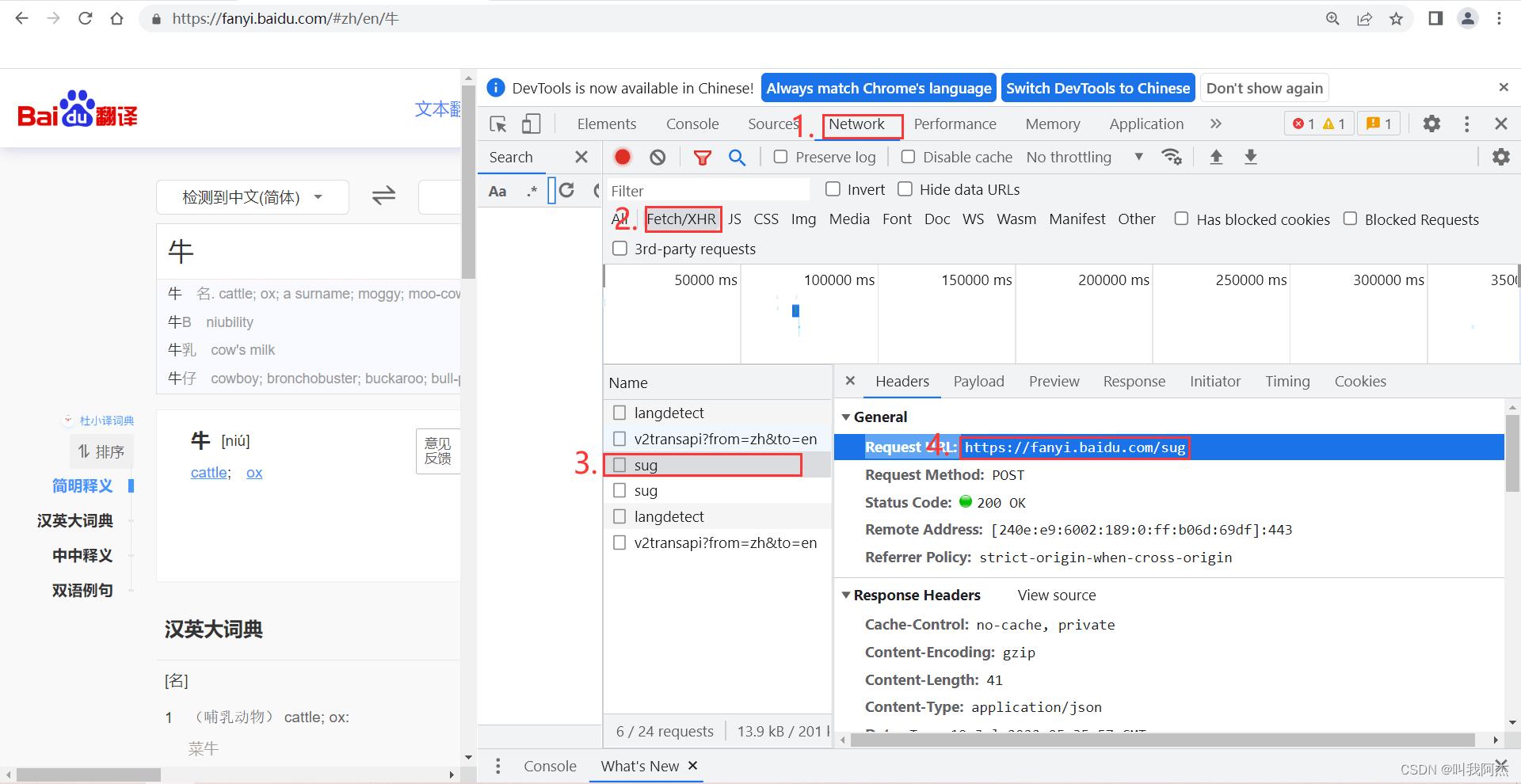
1. 打开网页,在搜索框输入百度翻译并进入百度翻译网站中。F12调出开发者工具,点击Network(网络)\ Fetch/XHR,同时在翻译框中任意输入搜索内容,此时就会发现有一个名称为sug的包。点击该包,点击后会看到有Heders、Payload、Preview和Rsponse等选项。点击Heders选项,将Request URL:后面的网址复制,这就是我们代码中需要的url。
2.在Heders选项中鼠标滚轮到最下方,找到User-Agent:并将后面的参数复制,就是我们所需的headers(请求头参数)。
3.页面中点击Payload选项,在Form Data选项下我们会看到有键值对的参数。前面的”键“相当于百度翻译中的搜索框,而后面的值就是我们输入的翻译内容。这部分参数就是data参数,data参数是以字典方式传递,所以这个”键“即kw就是我们所需的data参数的键。
激动人心的时刻,找到以上参数就可以下一步了!!!
二、使用步骤
1.导入库
代码如下(示例):
import requests import json
2.键盘输入内容
代码如下(示例):
fan_yi = input("请输入要翻译的内容:") # 2.键盘输入翻译内容该处使用的url网络请求的数据。
3.构建url/headers/data参数
这里面的headers参数因为设备不同可能会报错,大家可以根据我上面的网页分析去找自己电脑浏览器的参数,复制过来就行了。
注意事项:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
代码如下(示例):
import requests # 1.导入库
import json
fan_yi = input("请输入要翻译的内容:") # 2.键盘输入翻译内容
url = "https://fanyi.baidu.com/sug" # 3.写入url
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "} # 4.构建headers
data = {"kw":fan_yi} # 5.构建data
rsponse1 = requests.post(url = url,headers = headers,data = data) # 6.发起请求
rsponse2 = rsponse1.text # 获取响应数据
jie_xi = json.loads(rsponse2) # 解析数据
print(jie_xi) # 输出结果4.发起请求响应数据
代码如下(示例):
rsponse1 = requests.post(url = url,headers = headers,data = data) # 发起请求 rsponse2 = rsponse1.text # 获取响应数据
5.解析数据输出结果
代码如下(示例):
jie_xi = json.loads(rsponse2) # 解析数据 print(jie_xi) # 输出结果
三、完整代码
注意事项:headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "} 这一部分中的"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "我已经删减所以直接复制过去运行会报错,因按照如下图找到自己电脑浏览器的User-Agent:后面的参数复制进代码修改才行。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。

方法一:中规中矩写
代码如下(示例):
import requests # 导入库
import json
fan_yi = input("请输入要翻译的内容:") # 键盘输入翻译内容
url = "https://fanyi.baidu.com/sug" # 写入url
# 构建headers
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "}
data = {"kw":fan_yi} 构建data
rsponse1 = requests.post(url = url,headers = headers,data = data) # 发起请求
rsponse2 = rsponse1.text # 获取响应数据
jie_xi = json.loads(rsponse2) # 解析数据
print(jie_xi) # 输出结果方法二:将代码封装到函数里
def fangYi(data1):
url = "https://fanyi.baidu.com/sug"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)
data = {"kw":data1}
rsponse1 = requests.post(url = url,headers = headers,data = data)
rsponse2 = rsponse1.content.decode()
json1 = json.loads(rsponse2)
print(json1)
if __name__ == '__main__':
while True:
data1 = input("+++++请在下方输入要翻译的内容,退出请输入”no“+++++\n\t请输入要翻译的内容:")
if data1 == "no":
break
else:
fangYi(data1)加载全部内容