Spring文件上传
默念x 人气:0添加依赖
主要用来解析request请求流,获取文件字段名、上传文件名、content-type、headers等内容组装成FileItem
<!--添加fileupload依赖-->
<dependency>
<groupId>commons-fileupload</groupId>
<artifactId>commons-fileupload</artifactId>
<version>1.3.3</version>
</dependency>构建单例bean
CommonsMultipartResolver,将request请求从类型HttpServletRequest转化成MultipartHttpServletRequest,从MultipartHttpServletRequest可以获取上传文件的各种信息文件名、文件流等内容
注意:该bean的beanName要写成multipartResolver,否则无法获取到该bean
@Bean
public CommonsMultipartResolver multipartResolver() {
CommonsMultipartResolver commonsMultipartResolver = new CommonsMultipartResolver();
// 上传限制最大字节数 -1表示没限制
commonsMultipartResolver.setMaxUploadSize(-1);
// 每个文件限制最大字节数 -1表示没限制
commonsMultipartResolver.setMaxUploadSizePerFile(-1);
commonsMultipartResolver.setDefaultEncoding(StandardCharsets.UTF_8.name());
return commonsMultipartResolver;
}
#DispatcherServlet
public static final String MULTIPART_RESOLVER_BEAN_NAME = "multipartResolver";
private void initMultipartResolver(ApplicationContext context) {
try {
this.multipartResolver = context.getBean(MULTIPART_RESOLVER_BEAN_NAME, MultipartResolver.class);
if (logger.isDebugEnabled()) {
logger.debug("Using MultipartResolver [" + this.multipartResolver + "]");
}
}
catch (NoSuchBeanDefinitionException ex) {
// Default is no multipart resolver.
this.multipartResolver = null;
if (logger.isDebugEnabled()) {
logger.debug("Unable to locate MultipartResolver with name '" + MULTIPART_RESOLVER_BEAN_NAME +
"': no multipart request handling provided");
}
}
}校验请求
protected HttpServletRequest checkMultipart(HttpServletRequest request) throws MultipartException {
// multipartResolver不为空 且 request请求头中的content-type以multipart/开头
if (this.multipartResolver != null && this.multipartResolver.isMultipart(request)) {
if (WebUtils.getNativeRequest(request, MultipartHttpServletRequest.class) != null) {
logger.debug("Request is already a MultipartHttpServletRequest - if not in a forward, " +
"this typically results from an additional MultipartFilter in web.xml");
}
else if (hasMultipartException(request)) {
logger.debug("Multipart resolution previously failed for current request - " +
"skipping re-resolution for undisturbed error rendering");
}
else {
try {
// 解析请求
return this.multipartResolver.resolveMultipart(request);
}
catch (MultipartException ex) {
if (request.getAttribute(WebUtils.ERROR_EXCEPTION_ATTRIBUTE) != null) {
logger.debug("Multipart resolution failed for error dispatch", ex);
// Keep processing error dispatch with regular request handle below
}
else {
throw ex;
}
}
}
}
// If not returned before: return original request.
return request;
}解析请求
@Override
public MultipartHttpServletRequest resolveMultipart(final HttpServletRequest request) throws MultipartException {
Assert.notNull(request, "Request must not be null");
MultipartParsingResult parsingResult = parseRequest(request);
return new DefaultMultipartHttpServletRequest(request, parsingResult.getMultipartFiles(),
parsingResult.getMultipartParameters(), parsingResult.getMultipartParameterContentTypes());
}
protected MultipartParsingResult parseRequest(HttpServletRequest request) throws MultipartException {
String encoding = determineEncoding(request);
// 获取FileUpload实例
FileUpload fileUpload = prepareFileUpload(encoding);
try {
// 将request请求解析成FileItem
List<FileItem> fileItems = ((ServletFileUpload) fileUpload).parseRequest(request);
return parseFileItems(fileItems, encoding);
}
catch (FileUploadBase.SizeLimitExceededException ex) {
throw new MaxUploadSizeExceededException(fileUpload.getSizeMax(), ex);
}
catch (FileUploadBase.FileSizeLimitExceededException ex) {
throw new MaxUploadSizeExceededException(fileUpload.getFileSizeMax(), ex);
}
catch (FileUploadException ex) {
throw new MultipartException("Failed to parse multipart servlet request", ex);
}
}
// ctx->将request进行了包装
public List<FileItem> parseRequest(RequestContext ctx)
throws FileUploadException {
List<FileItem> items = new ArrayList<FileItem>();
boolean successful = false;
try {
// 通过ctx构建FileItem流的迭代器
FileItemIterator iter = getItemIterator(ctx);
// FileItemFactory创建FileItem的工厂对象
FileItemFactory fac = getFileItemFactory();
if (fac == null) {
throw new NullPointerException("No FileItemFactory has been set.");
}
// 判断是否itemValid是否为true,是否有可读文件
while (iter.hasNext()) {
final FileItemStream item = iter.next();
// Don't use getName() here to prevent an InvalidFileNameException.
// 文件名称
final String fileName = ((FileItemIteratorImpl.FileItemStreamImpl) item).name;
// 构建FileItem
FileItem fileItem = fac.createItem(item.getFieldName(), item.getContentType(),
item.isFormField(), fileName);
items.add(fileItem);
try {
// 将FileItemStreamImpl流拷贝到fileItem的输出流中(系统会自建文件)
Streams.copy(item.openStream(), fileItem.getOutputStream(), true);
} catch (FileUploadIOException e) {
throw (FileUploadException) e.getCause();
} catch (IOException e) {
throw new IOFileUploadException(format("Processing of %s request failed. %s",
MULTIPART_FORM_DATA, e.getMessage()), e);
}
final FileItemHeaders fih = item.getHeaders();
fileItem.setHeaders(fih);
}
successful = true;
return items;
} catch (FileUploadIOException e) {
throw (FileUploadException) e.getCause();
} catch (IOException e) {
throw new FileUploadException(e.getMessage(), e);
} finally {
if (!successful) {
for (FileItem fileItem : items) {
try {
fileItem.delete();
} catch (Throwable e) {
// ignore it
}
}
}
}
}
#解析获取到的fileItems
protected MultipartParsingResult parseFileItems(List<FileItem> fileItems, String encoding) {
MultiValueMap<String, MultipartFile> multipartFiles = new LinkedMultiValueMap<>();
Map<String, String[]> multipartParameters = new HashMap<>();
Map<String, String> multipartParameterContentTypes = new HashMap<>();
// Extract multipart files and multipart parameters.
for (FileItem fileItem : fileItems) {
// 是否是表单字段(下面的解析可以看到构建时该字段传参 fileName == null),也就是文件名是否为空
if (fileItem.isFormField()) {
String value;
String partEncoding = determineEncoding(fileItem.getContentType(), encoding);
try {
value = fileItem.getString(partEncoding);
}
catch (UnsupportedEncodingException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Could not decode multipart item '" + fileItem.getFieldName() +
"' with encoding '" + partEncoding + "': using platform default");
}
value = fileItem.getString();
}
String[] curParam = multipartParameters.get(fileItem.getFieldName());
if (curParam == null) {
// simple form field
multipartParameters.put(fileItem.getFieldName(), new String[] {value});
}
else {
// array of simple form fields
String[] newParam = StringUtils.addStringToArray(curParam, value);
multipartParameters.put(fileItem.getFieldName(), newParam);
}
multipartParameterContentTypes.put(fileItem.getFieldName(), fileItem.getContentType());
}
else {
// multipart file field 构建MultipartFile
CommonsMultipartFile file = createMultipartFile(fileItem);
// 以文件字段名为key (files)
multipartFiles.add(file.getName(), file);
if (logger.isDebugEnabled()) {
logger.debug("Found multipart file [" + file.getName() + "] of size " + file.getSize() +
" bytes with original filename [" + file.getOriginalFilename() + "], stored " +
file.getStorageDescription());
}
}
}
return new MultipartParsingResult(multipartFiles, multipartParameters, multipartParameterContentTypes);
}主要逻辑是这行代码FileItemIterator iter = getItemIterator(ctx);,FileItem流迭代器的构造
#构造方法
FileItemIteratorImpl(RequestContext ctx)
throws FileUploadException, IOException {
if (ctx == null) {
throw new NullPointerException("ctx parameter");
}
// 获取request的content-type,需要以multipart/ 开头
String contentType = ctx.getContentType();
if ((null == contentType)
|| (!contentType.toLowerCase(Locale.ENGLISH).startsWith(MULTIPART))) {
throw new InvalidContentTypeException(
format("the request doesn't contain a %s or %s stream, content type header is %s",
MULTIPART_FORM_DATA, MULTIPART_MIXED, contentType));
}
// 获取request的输入流
InputStream input = ctx.getInputStream();
// 获取内容长度 content-length 从request中取
@SuppressWarnings("deprecation") // still has to be backward compatible
final int contentLengthInt = ctx.getContentLength();
// 通过request.getHeader()取
final long requestSize = UploadContext.class.isAssignableFrom(ctx.getClass())
// Inline conditional is OK here CHECKSTYLE:OFF
? ((UploadContext) ctx).contentLength()
: contentLengthInt;
// CHECKSTYLE:ON
// sizeMax限制流大小 -1则不限制
if (sizeMax >= 0) {
if (requestSize != -1 && requestSize > sizeMax) {
throw new SizeLimitExceededException(
format("the request was rejected because its size (%s) exceeds the configured maximum (%s)",
Long.valueOf(requestSize), Long.valueOf(sizeMax)),
requestSize, sizeMax);
}
input = new LimitedInputStream(input, sizeMax) {
@Override
protected void raiseError(long pSizeMax, long pCount)
throws IOException {
FileUploadException ex = new SizeLimitExceededException(
format("the request was rejected because its size (%s) exceeds the configured maximum (%s)",
Long.valueOf(pCount), Long.valueOf(pSizeMax)),
pCount, pSizeMax);
throw new FileUploadIOException(ex);
}
};
}
// 获取字符编码
String charEncoding = headerEncoding;
if (charEncoding == null) {
charEncoding = ctx.getCharacterEncoding();
}
// 通过content-type = multipart/form-data; boundary=--------------------------205940049223747054037567
// 获取boundary的值分隔符(一串随机字符?)并转化为字节数组
boundary = getBoundary(contentType);
if (boundary == null) {
throw new FileUploadException("the request was rejected because no multipart boundary was found");
}
// 进度更新器
notifier = new MultipartStream.ProgressNotifier(listener, requestSize);
try {
// 构建多元流
multi = new MultipartStream(input, boundary, notifier);
} catch (IllegalArgumentException iae) {
throw new InvalidContentTypeException(
format("The boundary specified in the %s header is too long", CONTENT_TYPE), iae);
}
// 设置请求头编码
multi.setHeaderEncoding(charEncoding);
// 跳过序言
skipPreamble = true;
// 开始找第一个文件项目
findNextItem();
}接着再来看下MultipartStream的构建
#MultipartStream构造
public MultipartStream(InputStream input, // request输入流
byte[] boundary, // 边界 字节数组
int bufSize, // 缓冲区大小 默认4096
ProgressNotifier pNotifier) {
if (boundary == null) {
throw new IllegalArgumentException("boundary may not be null");
}
// We prepend CR/LF to the boundary to chop trailing CR/LF from
// body-data tokens. CR 回车\r LF 换行\n
// protected static final byte[] BOUNDARY_PREFIX = {CR, LF, DASH, DASH};
this.boundaryLength = boundary.length + BOUNDARY_PREFIX.length;
// 缓冲区大小判断
if (bufSize < this.boundaryLength + 1) {
throw new IllegalArgumentException(
"The buffer size specified for the MultipartStream is too small");
}
this.input = input;
// 重新确定缓冲区大小
this.bufSize = Math.max(bufSize, boundaryLength * 2);
// 创建缓冲区 用来从读inputStream 接受数据
this.buffer = new byte[this.bufSize];
this.notifier = pNotifier;
// 边界数组
this.boundary = new byte[this.boundaryLength];
this.keepRegion = this.boundary.length;
// 将BOUNDARY_PREFIX数组和入参boundary数组的内容按序复制到新的boundary中
System.arraycopy(BOUNDARY_PREFIX, 0, this.boundary, 0,
BOUNDARY_PREFIX.length);
System.arraycopy(boundary, 0, this.boundary, BOUNDARY_PREFIX.length,
boundary.length);
// head和tail为缓冲区操作的索引
// 0 <= head < bufSize
// 0 <= tail <= bufSize
head = 0;
tail = 0;
}接着看findNextItem方法,找第一个文件项目
/**
* Called for finding the next item, if any.
*
* @return True, if an next item was found, otherwise false.
* @throws IOException An I/O error occurred.
*/
private boolean findNextItem() throws IOException {
if (eof) {
return false;
}
// 开始为null
if (currentItem != null) {
currentItem.close();
currentItem = null;
}
for (;;) {
boolean nextPart;
if (skipPreamble) {
// 丢弃直到边界分隔符的所有数据 再读取边界
nextPart = multi.skipPreamble();
} else {
// 直接读取边界
nextPart = multi.readBoundary();
}
if (!nextPart) {
if (currentFieldName == null) {
// Outer multipart terminated -> No more data
eof = true;
return false;
}
// Inner multipart terminated -> Return to parsing the outer
multi.setBoundary(boundary);
currentFieldName = null;
continue;
}
// 解析头部 multi.readHeaders()从缓冲区解析到所有请求头的字符串
// 接着getParsedHeaders将字符串按\r\n分隔,因为每一行数据都是一个请求头内容
FileItemHeaders headers = getParsedHeaders(multi.readHeaders());
if (currentFieldName == null) {
// We're parsing the outer multipart
// 获取上传文件字段参数名name = files
String fieldName = getFieldName(headers);
if (fieldName != null) {
String subContentType = headers.getHeader(CONTENT_TYPE); // img/jpeg
if (subContentType != null
&& subContentType.toLowerCase(Locale.ENGLISH)
.startsWith(MULTIPART_MIXED)) {
currentFieldName = fieldName;
// Multiple files associated with this field name
byte[] subBoundary = getBoundary(subContentType);
multi.setBoundary(subBoundary);
skipPreamble = true;
continue;
}
// 文件名 IMG_0908.JPG
String fileName = getFileName(headers);
// 根据字段名、文件名、请求头等构建FileItemStream对象
currentItem = new FileItemStreamImpl(fileName,
fieldName, headers.getHeader(CONTENT_TYPE),
fileName == null, getContentLength(headers));
// 设置请求头
currentItem.setHeaders(headers);
// ++items
notifier.noteItem();
// 当期有可用item
itemValid = true;
return true;
}
} else {
String fileName = getFileName(headers);
if (fileName != null) {
currentItem = new FileItemStreamImpl(fileName,
currentFieldName,
headers.getHeader(CONTENT_TYPE),
false, getContentLength(headers));
currentItem.setHeaders(headers);
notifier.noteItem();
itemValid = true;
return true;
}
}
multi.discardBodyData();
}
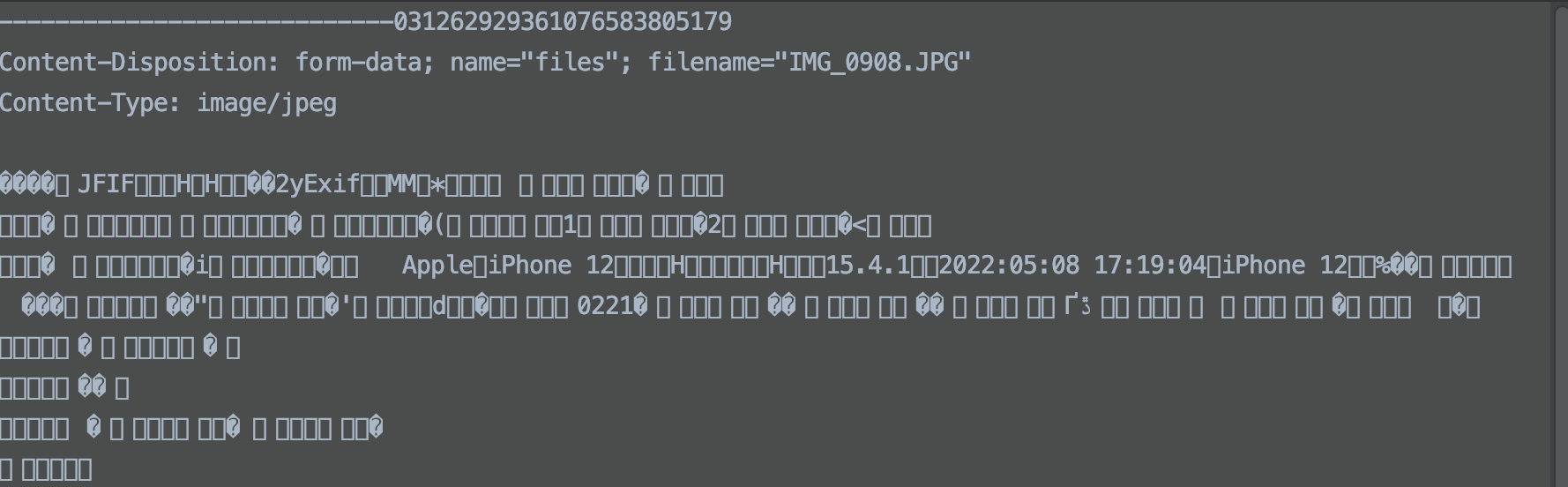
}下图为缓冲区数据,首行为boundary分隔符内容也就是上文提到的----加一串计算出来的随机字符,\r\n后接着为content-Disposition和content-type请求头,可以看到 HEADER_SEPARATOR头部分隔符\r\n\r\n 和分隔符之前的为请求头数据
另外boundary字节数组对应的内容为--------------------------031262929361076583805179,下图的首行内容比其多两个-
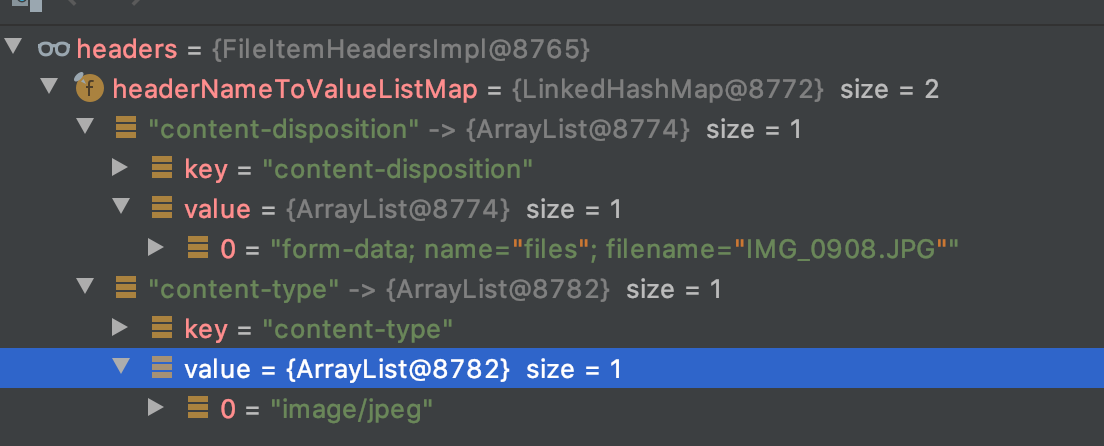
下图为解析完后的头部
接下来再看下FileItemStreamImpl的构造过程,比较简单
#FileItemStreamImpl构造方法
FileItemStreamImpl(String pName, String pFieldName,
String pContentType, boolean pFormField,
long pContentLength) throws IOException {
name = pName;
fieldName = pFieldName;
contentType = pContentType;
formField = pFormField;
// 创建itemStream流 本质上是从request的inputstream获取数据
// 从head位置再开始找boundary边界分隔符,若找到将边界的前一个索引赋值给pos变量,并且当前文件可读字符数为pos - head
final ItemInputStream itemStream = multi.newInputStream();
InputStream istream = itemStream;
// 若文件大小限制,超出长度会抛出异常
if (fileSizeMax != -1) {
if (pContentLength != -1
&& pContentLength > fileSizeMax) {
FileSizeLimitExceededException e =
new FileSizeLimitExceededException(
format("The field %s exceeds its maximum permitted size of %s bytes.",
fieldName, Long.valueOf(fileSizeMax)),
pContentLength, fileSizeMax);
e.setFileName(pName);
e.setFieldName(pFieldName);
throw new FileUploadIOException(e);
}
istream = new LimitedInputStream(istream, fileSizeMax) {
@Override
protected void raiseError(long pSizeMax, long pCount)
throws IOException {
itemStream.close(true);
FileSizeLimitExceededException e =
new FileSizeLimitExceededException(
format("The field %s exceeds its maximum permitted size of %s bytes.",
fieldName, Long.valueOf(pSizeMax)),
pCount, pSizeMax);
e.setFieldName(fieldName);
e.setFileName(name);
throw new FileUploadIOException(e);
}
};
}
stream = istream;
}再来看看ItemInputStream,上面的FileItemStreamImpl对象有这个类型参数,主要用来获取请求流的,因为ItemInputStream类是MultipartStream的内部类,能够调用MultipartStream中的input流。
ItemInputStream
public class ItemInputStream extends InputStream implements Closeable {
// 目前已经读取的字节数
private long total;
// 必须保持的字节数可能是分隔符boundary的一部分
private int pad;
// 缓冲区的当前偏移
private int pos;
// stream流是否关闭
private boolean closed;
// 构造方法
ItemInputStream() {
findSeparator();
}
// 寻找边界分隔符boundary的前一个索引
private void findSeparator() {
pos = MultipartStream.this.findSeparator();
if (pos == -1) {
if (tail - head > keepRegion) {
pad = keepRegion;
} else {
pad = tail - head;
}
}
}
// 可读取字节数
@Override
public int available() throws IOException {
// 可读=尾-首-边界长度
if (pos == -1) {
return tail - head - pad;
}
// pos !=-1 说明pos后面是边界了 只能读到这个边界之前的数据
// 可读 = 边界前的最后一个索引 - 首
return pos - head;
}
private static final int BYTE_POSITIVE_OFFSET = 256;
// 读取stream流的下一个字符
@Override
public int read() throws IOException {
if (closed) {
throw new FileItemStream.ItemSkippedException();
}
if (available() == 0 && makeAvailable() == 0) {
return -1;
}
++total;
int b = buffer[head++];
if (b >= 0) {
return b;
}
// 如果负的 加上256
return b + BYTE_POSITIVE_OFFSET;
}
// 读取字节到给定的缓冲区b中
@Override
public int read(byte[] b, int off, int len) throws IOException {
if (closed) {
throw new FileItemStream.ItemSkippedException();
}
if (len == 0) {
return 0;
}
int res = available();
if (res == 0) {
res = makeAvailable();
if (res == 0) {
return -1;
}
}
res = Math.min(res, len);
System.arraycopy(buffer, head, b, off, res);
// head加偏移
head += res;
total += res;
return res;
}
// 关闭输入流
@Override
public void close() throws IOException {
close(false);
}
/**
* Closes the input stream.
*
* @param pCloseUnderlying Whether to close the underlying stream
* (hard close)
* @throws IOException An I/O error occurred.
*/
public void close(boolean pCloseUnderlying) throws IOException {
if (closed) {
return;
}
if (pCloseUnderlying) {
closed = true;
input.close();
} else {
for (;;) {
int av = available();
if (av == 0) {
av = makeAvailable();
if (av == 0) {
break;
}
}
skip(av);
}
}
closed = true;
}
// 跳过缓冲区中给定长度的字节
@Override
public long skip(long bytes) throws IOException {
if (closed) {
throw new FileItemStream.ItemSkippedException();
}
int av = available();
if (av == 0) {
av = makeAvailable();
if (av == 0) {
return 0;
}
}
long res = Math.min(av, bytes);
head += res;
return res;
}
// 试图读取更多的数据,返回可读字节数
private int makeAvailable() throws IOException {
if (pos != -1) {
return 0;
}
// 将数据移到缓冲区的开头,舍弃边界
total += tail - head - pad;
System.arraycopy(buffer, tail - pad, buffer, 0, pad);
// Refill buffer with new data.
head = 0;
tail = pad;
for (;;) {
// 读取tail位置开始读 bufSize-tail长度的字节到buffer缓冲区中
int bytesRead = input.read(buffer, tail, bufSize - tail);
if (bytesRead == -1) {
// The last pad amount is left in the buffer.
// Boundary can't be in there so signal an error
// condition.
final String msg = "Stream ended unexpectedly";
throw new MalformedStreamException(msg);
}
if (notifier != null) {
notifier.noteBytesRead(bytesRead);
}
// tail加偏移
tail += bytesRead;
// 再尝试找boundary边界,赋值pos -1
findSeparator();
int av = available();
// 返回可读字节数
if (av > 0 || pos != -1) {
return av;
}
}
}
// 判断流是否关闭
public boolean isClosed() {
return closed;
}
}接受请求
请求解析完成后就可以以文件对象接收了,参数类型为MultipartFile,可强转为CommonsMultipartFile,参数名需要与上传文件的fieldName相对应或者也可以用@RequestParam注解指定参数名
@RequestMapping(value = "file/upload", method = RequestMethod.POST)
@ResponseBody
public Object uploadFile(MultipartFile[] files, HttpServletRequest request, HttpServletResponse response) throws IOException {
....... 上传逻辑
return CommonResult.succ("上传成功");
}可以用postman测试,content-type的boundary显示是请求发送时计算,不知道怎么算的反正是一串随机数,是用来分隔多个文件内容的,在源码中可以看到不能缺失否则解析过程中会报错
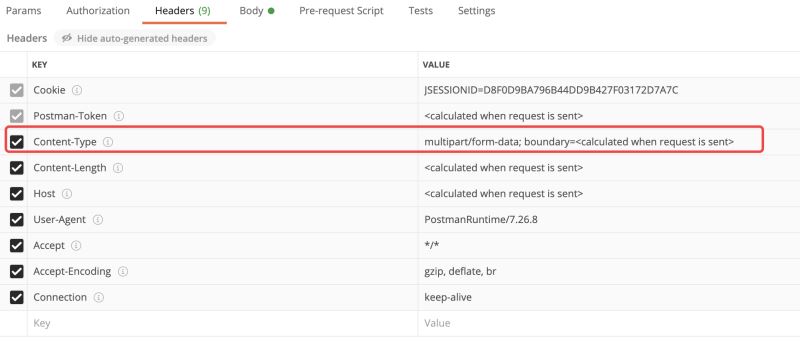
加载全部内容