Python梯度下降法
侯小啾 人气:01.首先读取数据集
导包并读取数据,数据自行任意准备,只要有两列,可以分为自变量x和因变量y即可即可。
import numpy as np
import matplotlib.pyplot as plt
data = np.loadtxt("data.csv", delimiter=",")
x_data = data[:, 0]
y_data = data[:, 1]
2.初始化相关参数
# 初始化 学习率 即每次梯度下降时的步长 这里设置为0.0001 learning_rate = 0.0001 # 初始化 截距b 与 斜率k b = 0 k = 0 # 初始化最大迭代的次数 以50次为例 n_iterables = 50
3.定义计算代价函数–>MSE
使用均方误差 MSE (Mean Square Error)来作为性能度量标准
假设共有m个样本数据,则均方误差:
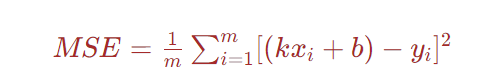
将该公式定义为代价函数,此外为例后续求导方便,则使结果在原mse的基础上,再乘以1/2。
def compute_mse(b, k, x_data, y_data):
total_error = 0
for i in range(len(x_data)):
total_error += (y_data[i] - (k * x_data[i] + b)) ** 2
# 为方便求导:乘以1/2
mse_ = total_error / len(x_data) / 2
return mse_
4.梯度下降
分别对上述的MSE表达式(乘以1/2后)中的k,b求偏导,
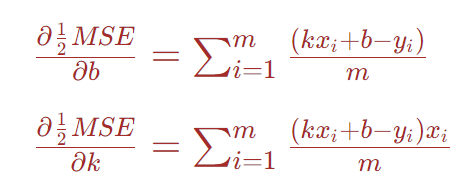
更新b和k时,使用原来的b,k值分别减去关于b、k的偏导数与学习率的乘积即可。至于为什么使用减号,可以这么理解:以斜率k为例,当其导数大于零的时候,则表示均方误差随着斜率的增大而增大,为了使均方误差减小,则不应该使斜率继续增大,所以需要使其减小,反之当偏导大于零的时候也是同理。其次,因为这个导数衡量的是均方误差的变化,而不是斜率和截距的变化,所以这里需要引入一个学习率,使得其与偏导数的乘积能够在一定程度上起到控制截距和斜率变化的作用。
def gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables):
m = len(x_data)
# 迭代
for i in range(n_iterables):
# 初始化b、k的偏导
b_grad = 0
k_grad = 0
# 遍历m次
for j in range(m):
# 对b,k求偏导
b_grad += (1 / m) * ((k * x_data[j] + b) - y_data[j])
k_grad += (1 / m) * ((k * x_data[j] + b) - y_data[j]) * x_data[j]
# 更新 b 和 k 减去偏导乘以学习率
b = b - (learning_rate * b_grad)
k = k - (learning_rate * k_grad)
# 每迭代 5 次 输出一次图形
if i % 5 == 0:
print(f"当前第{i}次迭代")
print("b_gard:", b_grad, "k_gard:", k_grad)
print("b:", b, "k:", k)
plt.scatter(x_data, y_data, color="maroon", marker="x")
plt.plot(x_data, k * x_data + b)
plt.show()
return b, k
5.执行
print(f"开始:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}")
print("开始迭代")
b, k = gradient_descent(x_data, y_data, b, k, learning_rate, n_iterables)
print(f"迭代{n_iterables}次后:截距b={b},斜率k={k},损失={compute_mse(b,k,x_data,y_data)}")
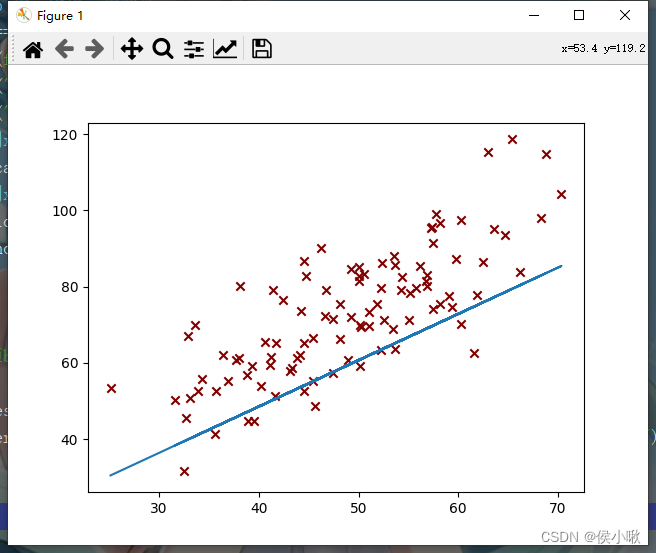
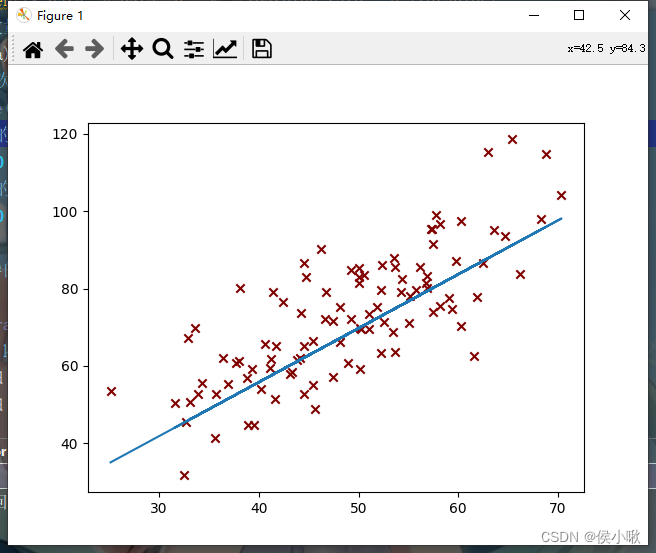
代码执行过程产生了一系列的图像,部分图像如下图所示,随着迭代次数的增加,代价函数越来越小,最终达到预期效果,如下图所示:
第5次迭代:
第10次迭代:
第50次迭代:
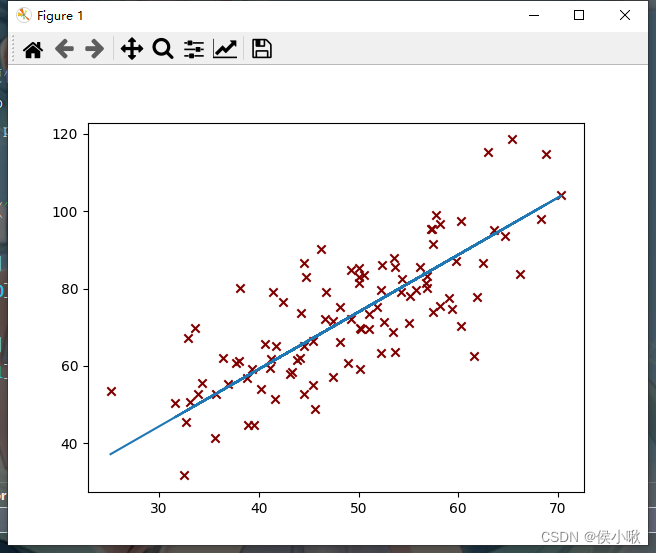
执行过程的输出结果如下图所示:
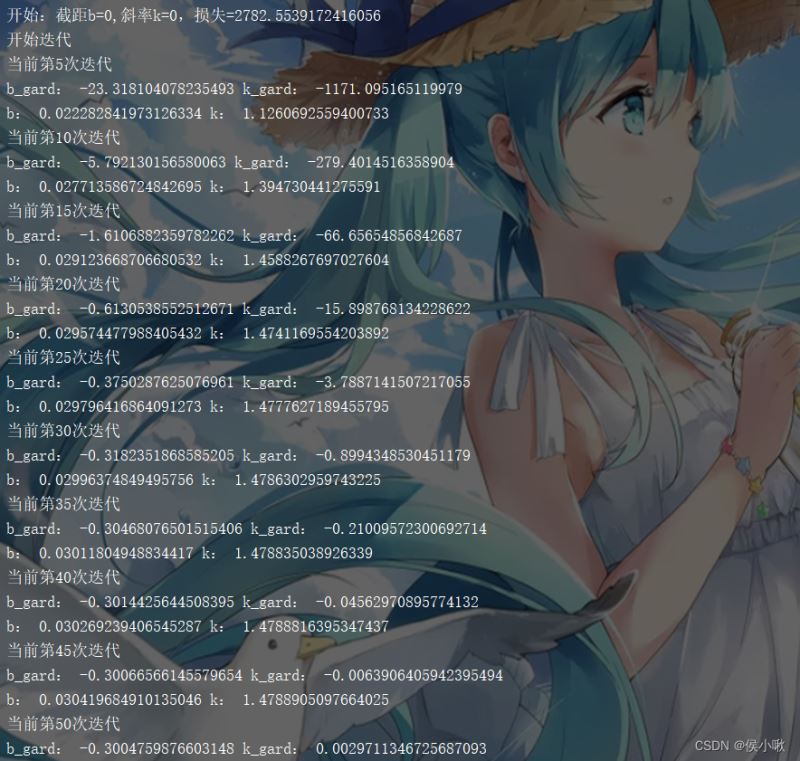
可以看到,随着偏导数越来越小,斜率与截距的变化也越来越细微。
加载全部内容