Python文本文件转Excel
ZackSock 人气:0一、前言
Excel文件是我们常用的一种文件,在工作中使用非常频繁。Excel中有许多强大工具,因此用Excel来处理文件会给我们带来很多便捷。但是有时候我们拿到了文件不是Excel文件,而且我们又想用Excel中的工具,这个时候我们就可以想办法把这个文件转换成Excel文件了。今天我们就来实现一下,需要注意我们只能把有规律的文件转换成Excel,而且今天的内容也不是普遍通用的。只提供一种思路。
二、openpyxl模块
openpyxl模块是用来操作Excel文件的一个模块,还有很多模块可以做同样的事情,这里就不介绍了。
1、安装
安装只需要执行下面语句即可:
pip install openpyxl
然后在代码中导入工作簿:
from openpyxl import Workbook
这样我们就可以开始操作了。
2、简单操作
我们来看一些简单的操作:
from openpyxl import Workbook
# 创建工作簿
wb = Workbook()
# 激活
ws = wb.active
# 设置指定格的数据
ws['A1'] = 41
# 在下一行添加数据
ws.append([1, 2, 3])
# 保存
wb.save("1.xlsx")
这里前面两步是基本操作,首先创建Workbook对象,然后调用active函数激活。然后我们通过下标的方式给指定坐标的位置添加数据。最后调用save方法保存文件。
三、文本文件转excel文件
上面的几个操作就足够我们今天的操作了,下面我们来看看如何将文本文件转换成Excel文件。
1、寻找规律
在文章开头说了,我们只能将有规律的文本文件转换成Excel,不然没有太多意义。所以我们第一步就是找规律。比如我们下面这个文件:
姓名,性别,年龄 zack,男,21 rudy,男,22 alice,女,20 atom,男, 23
我们来看一下上面的数据,其中第一行是数据的字段。而后面几行就是真实数据了。而单个数据的属性值又由逗号隔开。这种规律非常明显,很适合我们今天的内容。不管仔细观察可以看到,逗号有中文的也有英文的,而且有的里面还包含了空格。知道这些后我们在转换的时候就需要针对性的处理一下了。
2、开始转换
首先我们要处理文本,然后再写入Excel,具体代码如下:
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
# 处理文件
with open("test.txt", "r", encoding="utf-8") as f:
# 把逗号替换成统一的\t
content = f.read().replace(",", "\t").replace(",", "\t")
# 根据换行拆分内容
lines = content.split("\n")
# 提取标题
titles = lines[0].split("\t")
titles.insert(0, "")
# 标题写入excel
ws.append(titles)
# 写入内容
for i, line in enumerate(lines[1:]):
item = line.split("\t")
item.insert(0, i)
ws.append(item)
wb.save("1.xlsx")
经过上面的处理,我们就成功将文本转换成excel了,下面是结果图:
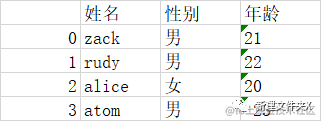
excel表格
效果正是我们想要的,大家可以根据不同需求不同文件来修改处理的代码。
补充
Python对于Excel文件的操作当然不仅仅是可以将文本文件转为Excel,还可以将PDF转为Excel,下面是实现代码,希望对你有所帮助
import pdfplumber
import pandas as pd
path = 'test.pdf'
pdf = pdfplumber.open(path)
i=1
#writer=pd.ExcelWriter('output.xlsx')
df=pd.DataFrame(columns=['序号','刊名','主办单位','等级'])
sheetname=['考古文博','历史学','马克思主义理论','民族学与文化学','文学-外国文学','文学-中国文学','艺术学','语言学','哲学','宗教学','法学'
,'管理学','环境科学','教育学','经济学-财政科学','经济学-工业经济','经济学-金融','经济学-经济管理','经济学-经济综合','经济学-贸易经济'
,'经济学-农业经济','经济学-世界经济','人文地理学','社会学','体育学','统计学','图书馆情报与档案学','心理学','新闻学与传播学'
,'政治学-国际政治','政治学-中国政治','综合-高校综合性学报','综合-综合性人文社科期刊']
##由于存在一个表格跨页的情况,先将所有表格存放在一个DataFrame中,再根据序号拆分。
for page in pdf.pages[17:59]:
print (page)
# 获取当前页面的全部文本信息,包括表格中的文字
# print(page.extract_text())
for table in page.extract_tables():
#print(table)
df=df.append(pd.DataFrame(table[1:],columns=table[0]),ignore_index=True)
print (df)
writer=pd.ExcelWriter('output3.xlsx')
new_df=pd.DataFrame()
j=1
index=[]
#记录序号==1的行索引,用于后面的表格拆分
for i in range(len(df)):
if df.ix[i,0]=='1':
index.append(i)
print ("################")
index.append(len(df))
#print (index)
#按行索引将内容切片并逐个添加到表中
for t in range(len(index)-1):
new_df=df.ix[index[t]:index[t+1]-1,:]
#print (new_df)
new_df.to_excel(writer,sheet_name=sheetname[t],encoding='gb2312',index=None)
writer.save()
pdf.close()
print('finished') 加载全部内容