Golang标准库unsafe
大摩羯先生 人气:0引言
当你阅读Golang源码时一定遇到过unsafe.Pointer、uintptr、unsafe.Sizeof等,是否很疑惑它们到底在做什么?如果不了解这些底层代码在发挥什么作用,一定也无法了解上层应用构建的来由了,本篇我们来剖析下Golang标准库的底层包unsafe!
unsafe包
我们基于Go1.16版本进行剖析,按照包的简介内容描述是:unsafe包含的是围绕Go程序安全相关的操作,导入unsafe包后构建的功能可能不被Go相关兼容性支持。
这里和Java中的unsafe包功能类似,unsafe包中功能主要面向Go语言标准库内部使用,一般业务开发中很少用到,除非是要做基础能力的铺建,对该包的使用应当是非常熟悉它的特性,对使用不当带来的负面影响也要非常清晰。
unsafe构成
type ArbitraryType int type Pointer *ArbitraryType func Sizeof(x ArbitraryType) uintptr func Offsetof(x ArbitraryType) uintptr func Alignof(x ArbitraryType) uintptr
可以看到,包的构成比较简单,下面我们主要结合源码中注释内容来展开剖析和学习。
type ArbitraryType int
Arbitrary翻译: 随心所欲,任意的
type ArbitraryType int
ArbitraryType没有什么实质作用,它表示任意一种类型,实际上不是unsafe包的一部分。它表示任意Go表达式的类型。
type Pointer *ArbitraryType
type Pointer *ArbitraryType
Pointer是unsafe包的核心。
灵活转换
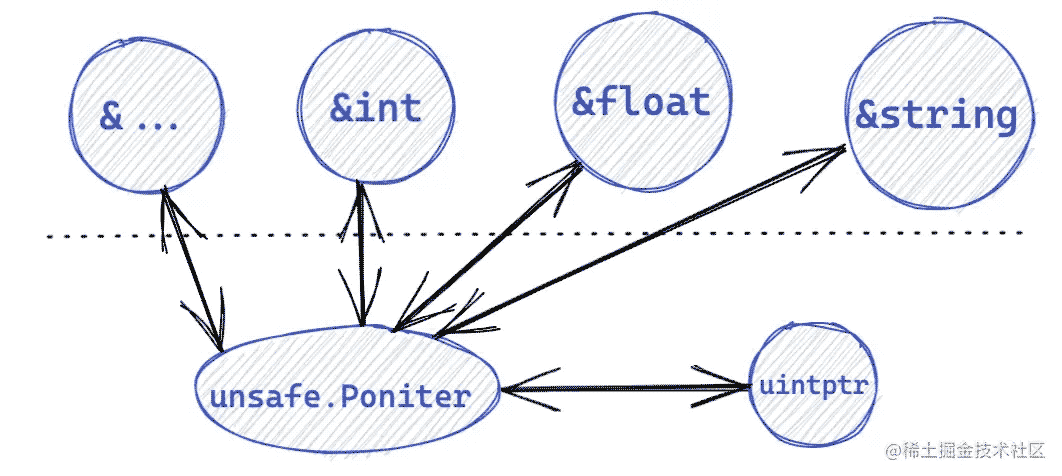
它表示指向任意类型的指针,有四种特殊操作可用于类型指针,而其他类型不可用,大概的转换关系如下:
- 任何类型的指针值都可以转换为
Pointer Pointer可以转换为任何类型的指针值- 任意
uintptr可以转换为Pointer Pointer也可以转换为任意uintptr
潜在的危险性
正是因为它有能力和各种数据类型之间建立联系完成转换,Pointer通常被认为是较为危险的,它能允许程序侵入系统并读取和写入任意内存,使用时应格外小心!!!
源码注释中列举了提到了一些正确和错误使用的例子。它还提到更为重要的一点是:不使用这些模式的代码可能现在或者将来变成无效。即使下面的有效模式也有重要的警告。试图来理解下这句话的核心就是,它不能对你提供什么保证!
对于编码的正确性还可以通过运行Golang提供的工具“go vet”可以帮助找到不符合这些模式的指针用法,但“go vet”并不能保证代码一定一定是有效的。
go vet是golang中自带的静态分析工具,可以帮助检测编写代码中一些隐含的错误并给出提示。比如下面故意编写一个带有错误的代码,fmt.Printf中%d需要填写数值类型,为了验证go vet效果,故意填写字符串类型看看静态分析效果。
代码样例:
func TestErr(t *testing.T) {
fmt.Printf("%d","hello world")
}
运行:
`go vet unsafe/unsafe_test.go`
控制台输出提示:
unsafe/unsafe_test.go:9:2: Printf format %d has arg "hello world" of wrong type string
✅ 正确的使用姿势
以下涉及Pointer的模式是有效的,这里给出几个例子:
- (1) 指针 *T1 转化为 指针 *T2. T1、T2两个变量共享等值的内存空间布局,在不超过数据范围的前提下,可以允许将一种类型的数据重新转换、解释为其他类型的数据。
下面我们操作一个样例:声明并开辟一个内存空间,然后基于该内存空间进行不同类型数据的转换。
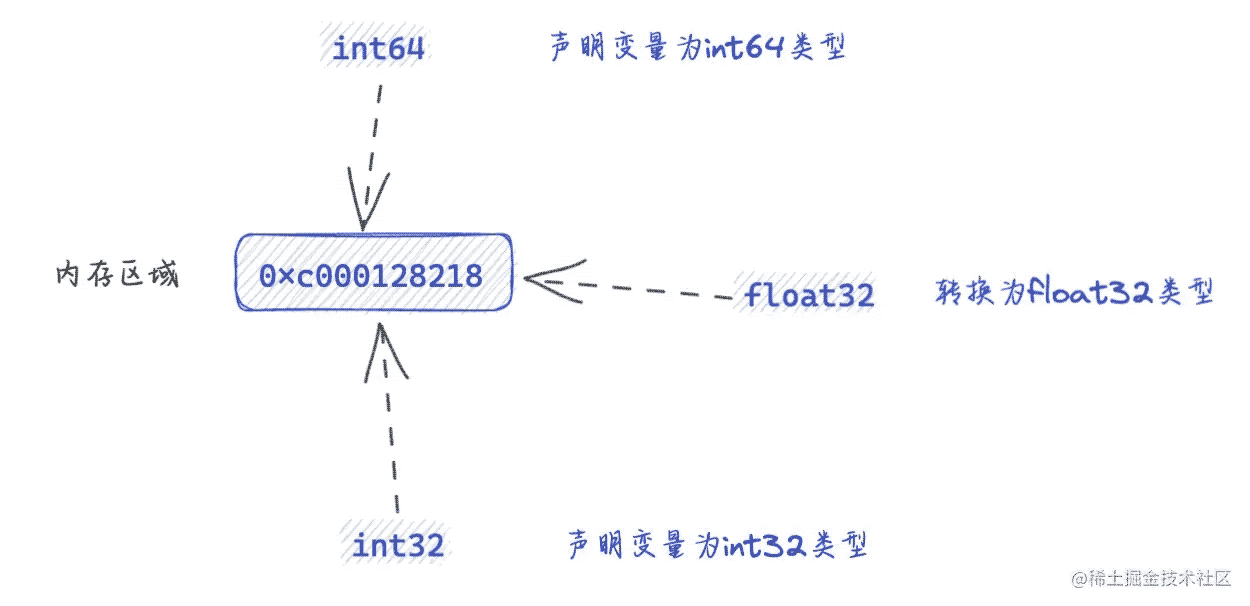
代码如下:
// 步骤:
// (1) 声明为一个int64类型
// (2) int64 -> float32
//(3) float32 -> int32
func TestPointerTypeConvert(t *testing.T) {
// (1) 声明为一个int64类型
int64Value := int64(20)
// int64数据打印
fmt.Println("int64类型的值:", int64Value)
//打印:int64类型的值: 20
fmt.Println("int64类型的指针地址:", &int64Value)
//打印:int64类型的指针地址: 0xc000128218
// (2) int64 -> float32
float32Ptr := (*float32)(unsafe.Pointer(&int64Value))
fmt.Println("float32类型的值:", *(*float32)(unsafe.Pointer(&int64Value)))
//打印:float32类型的值: 2.8e-44
fmt.Println("float32类型的指针地址:", (*float32)(unsafe.Pointer(&int64Value)))
//打印:float32类型的指针地址: 0xc000128218
// (3) float32 -> int32
fmt.Println("int32类型的指针:", (*int32)(unsafe.Pointer(float32Ptr)))
//打印:int32类型的指针: 0xc000128218
fmt.Println("int32类型的值:", *(*int32)(unsafe.Pointer(float32Ptr)))
//打印:int32类型的值: 20
}
小结 Pointer利用能够和不同数据类型之间进行转换的灵活特性,可以有效进行完成数据转换、指针复制的功能
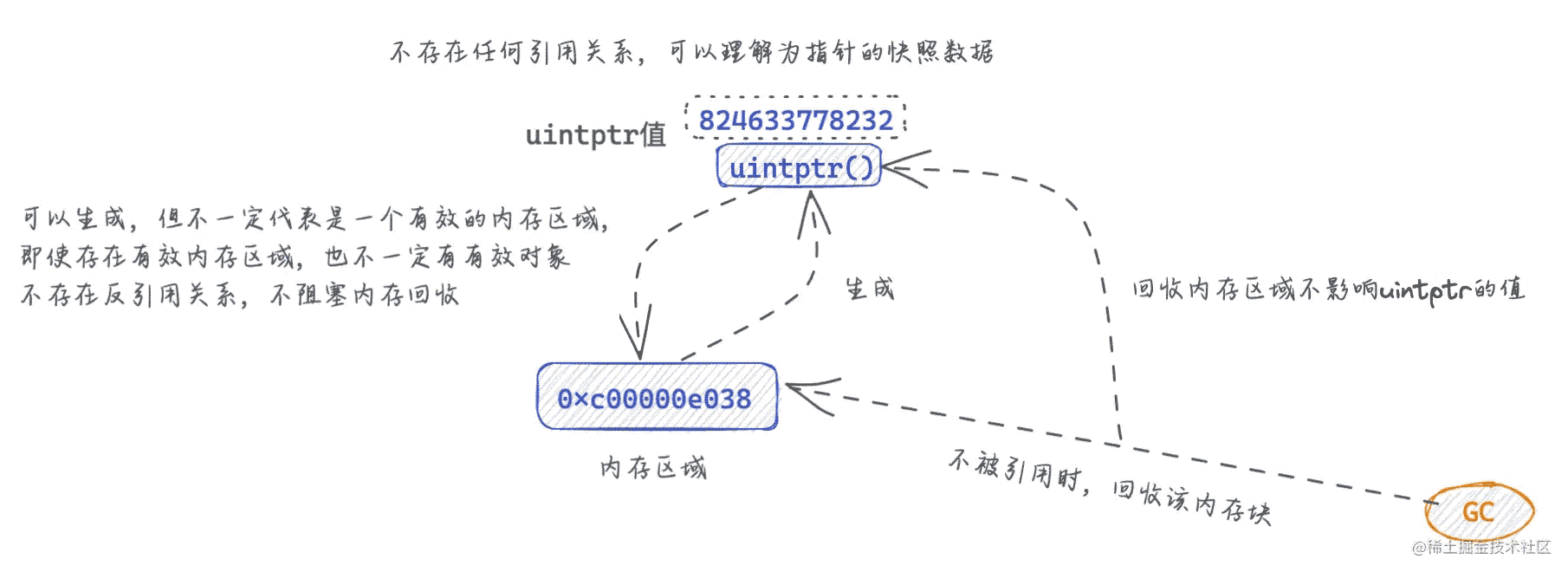
(2) Pointer 转换为 uintptr(不包括返回的转换)
- 将指针转换为
uintptr将生成指向的值的内存地址,该地址为整数。 - 这种
uintptr通常用于打印。将uintptr转换回指针通常无效,uintptr是整数,而不是引用。 - 将指针转换为
uintptr将创建一个没有指针语义的整数值。即使uintptr包含某个对象的地址,如果对象移动,垃圾收集器不会更新uintptr的值,uintptr也不会阻止对象被回收。 - 其余模式枚举从
uintptr到指针的唯一有效转换。
(3) Pointer 转换为 uintptr(包含返回的转换,使用算术) 如果变量p指向一个分配的对象,它可以通过该对象转换为uintptr,添加偏移量,并转换回指针。
// (1) 声明一个数组,持有两个元素
// (2) 输出第1个元素指针信息
// (3) 输出第2个元素指针信息
// (4) 通过第一个元素指针地址加上偏移量可以得到第二个元素地址
// (5) 还原第二个元素的值
func TestUintptrWithOffset(t *testing.T) {
// (1) 声明一个数组,持有两个元素
p := []int{1,2}
// (2) 输出第1个元素指针信息
fmt.Println("p[0]的指针地址:",&p[0])
// p[0]的指针地址 0xc0000a0160
ptr0 := uintptr(unsafe.Pointer(&p[0]))
fmt.Println(ptr0)
// 824634376544
// (3) 输出第2个元素指针信息
fmt.Println("p[1]的指针地址:",&p[1])
// p[1]的指针地址 0xc0000a0168
ptr1 := uintptr(unsafe.Pointer(&p[1]))
fmt.Println(ptr1)
// 824634376552
// (4) 通过第一个元素指针地址加上偏移量可以得到第二个元素指针地址
offset := uintptr(unsafe.Pointer(&p[0])) + 8 //int类型占8字节
ptr1ByOffset := unsafe.Pointer(offset)
fmt.Println("p[0]的指针地址 + offset偏移量可以得到p[1]的指针地址:",ptr1ByOffset)
// p[0]的指针地址 + offset偏移量可以得到p[1]的指针地址 0xc0000a0168
// (5) 还原第二个元素的值
fmt.Println("通过偏移量得到的指针地址还原值:",*(*int)(ptr1ByOffset))
// 通过偏移量得到的指针地址还原值:2
}
小结
最常见的用途是访问结构或数组元素中的字段:
- 从指针添加、减去偏移量都是可操作的
- 使用
&^对指针进行舍入也是有效的,通常用于对齐 - 要保证内存偏移量指向正确,指向有效的原始分配的对象的偏移量上
❌ 错误的使用姿势
与C中不同的是,将指针指向到其原始分配结束之后是无效的:
//❌ 无效:分配空间外的端点
func TestOverOffset(t *testing.T) {
// 声明字符串变量str
str := "abc"
// 在str的内存偏移量基础上增加了额外的一个偏移量得到一个新的内存偏移量,该内存地址是不存在的
newStr := unsafe.Pointer(uintptr(unsafe.Pointer(&str)) + unsafe.Sizeof(str))
// 这里由于不存在该内存偏移量的对象,肯定求不到值,这里的表现是一直阻塞等待
fmt.Println(*(*string)(newStr))
}
注意,两个转换必须出现在同一个表达式中,它们之间只有中间的算术运算。
//❌ 无效:在转换回指针之前,uintptr不能存储在变量中 u := uintptr(p) p = unsafe.Pointer(u + offset) //推荐如下这种方式,不要依靠中间变量来传递uintptr p = unsafe.Pointer(uintptr(p) + offset)
请注意,指针必须指向已分配的对象,因此它不能是零。
//❌ 无效:零指针的转换 u := unsafe.Pointer(nil) p := unsafe.Pointer(uintptr(u) + offset)
- (4) 调用
syscall.Syscall时将指针转换为uintptrsyscall包中的Syscall函数将其uintptr参数直接传递给操作系统,然后操作系统可能会根据调用的详细信息,将其中一些重新解释为指针。也就是说,系统调用实现隐式地将某些参数从uintptr转换回指针。
如果必须将指针参数转换为uintptr以用作参数,则该转换必须出现在调用表达式本身之中:
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))
编译器处理在程序集中实现的函数调用的参数列表中转换为uintptr的指针,方法是安排保留引用的已分配对象(如果有),并在调用完成之前不移动,即使仅从类型来看,调用期间似乎不再需要该对象。
要使编译器识别此模式,转换必须出现在参数列表中:
//❌ 无效:在系统调用期间隐式转换回指针之前,uintptr不能存储在变量中,和上面提到的问题类似 u := uintptr(unsafe.Pointer(p)) syscall.Syscall(SYS_READ, uintptr(fd), u, uintptr(n))
(5) 从uintptr到Pointer,包含反射(Reflect)、反射值指针(Reflect.Value.Pointer)、反射值地址(Reflect.Value.UnsafeAddr)的转换结果
包reflect的值方法名为Pointer和UnsafeAddr,返回类型为uintptr,而不是unsafe。防止调用者在不首先导入“unsafe”的情况下将结果更改为任意类型的指针。然而,这意味着结果是脆弱的,必须在调用后立即在同一表达式中转换为Pointer
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))
与上述情况一样,在转换之前存储结果是无效的
//❌ 无效:在转换回指针之前,uintptr不能存储在变量中,和上面提到的问题类似 u := reflect.ValueOf(new(int)).Pointer() p := (*int)(unsafe.Pointer(u))
(6)reflect.SliceHeader或reflect.StringHeader的数据字段与Pointer的转换 与前一种情况一样,reflect.SliceHeader、reflect.StringHeader将字段数据声明为uintptr,以防止调用方在不首先导入“unsafe”的情况下将结果更改为任意类型。
然而,这意味着SliceHeader和StringHeader仅在解释实际切片(slice)或字符串值(string)的内容时有效。
var s string hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // case 1 hdr.Data = uintptr(unsafe.Pointer(p)) // case 6 (this case) hdr.Len = n
在此用法中,hdr.Data实际上是引用字符串头中底层指针的另一种方式,而不是uintptr变量本身。
一般来说,reflect.SliceHeader和reflect.StringHeader应该仅用作那些指向实际为切片(slice)、字符串(string)的*reflect.SliceHeader和*reflect.StringHeader,而不是普通的结构体。程序不应声明或分配这些结构类型的变量。
// ❌ 无效: 直接声明的Header不会将数据作为引用。 var hdr reflect.StringHeader hdr.Data = uintptr(unsafe.Pointer(p)) hdr.Len = n s := *(*string)(unsafe.Pointer(&hdr)) // p可能已经被回收
func Sizeof(x ArbitraryType) uintptr
Sizeof返回类型v本身数据所占用的字节数。返回值是“顶层”的数据占有的字节数。例如,若v是一个切片,它会返回该切片描述符的大小,而非该切片底层引用的内存的大小。
Go语言中非聚合类型通常有一个固定的大小
引用类型或包含引用类型的大小在32位平台上是4字节,在64位平台上是8字节。
| 类型 | 分类 | 大小 |
|---|---|---|
| bool | 非聚合 | 1个字节 |
| intN, uintN, floatN, complexN | 非聚合 | N/8个字节(例如float64是8个字节) |
| int, uint, uintptr | 非聚合 | 1个机器字 (32位系统:1机器字=4字节; 64位系统:1机器字=8字节) |
| *T | 聚合 | 1个机器字 |
| string | 聚合 | 2个机器字(data,len) |
| []T | 聚合 | 3个机器字(data,len,cap) |
| map | 聚合 | 1个机器字 |
| func | 聚合 | 1个机器字 |
| chan | 聚合 | 1个机器字 |
| interface | 聚合 | 2个机器字(type,value) |
type Model struct {
//Field...
}
func TestSizeOf(t *testing.T) {
boolSize := false
intSize := 1
int8Size := int8(1)
int16Size := int16(1)
int32Size := int32(1)
int64Size := int64(1)
arrSize := make([]int, 0)
mapSize := make(map[string]string, 0)
structSize := &Model{}
funcSize := func() {}
chanSize := make(chan int, 10)
stringSize := "abcdefg"
fmt.Println("bool sizeOf:", unsafe.Sizeof(boolSize))
//bool sizeOf: 1
fmt.Println("int sizeOf:", unsafe.Sizeof(intSize))
//int sizeOf: 8
fmt.Println("int8 sizeOf:", unsafe.Sizeof(int8Size))
//int8 sizeOf: 1
fmt.Println("int16 sizeOf:", unsafe.Sizeof(int16Size))
//int16 sizeOf: 2
fmt.Println("int32 sizeOf:", unsafe.Sizeof(int32Size))
//int32 sizeOf: 4
fmt.Println("int64 sizeOf:", unsafe.Sizeof(int64Size))
//int64 sizeOf: 8
fmt.Println("arrSize sizeOf:", unsafe.Sizeof(arrSize))
//arrSize sizeOf: 24
fmt.Println("structSize sizeOf:", unsafe.Sizeof(structSize))
//structSize sizeOf: 8
fmt.Println("mapSize sizeOf:", unsafe.Sizeof(mapSize))
//mapSize sizeOf: 8
fmt.Println("funcSize sizeOf:", unsafe.Sizeof(funcSize))
//funcSize sizeOf: 8
fmt.Println("chanSize sizeOf:", unsafe.Sizeof(chanSize))
//chanSize sizeOf: 8
fmt.Println("stringSize sizeOf:", unsafe.Sizeof(stringSize))
//stringSize sizeOf: 16
}
func Offsetof(x ArbitraryType) uintptr
Offsetof返回类型v所代表的结构体字段f在结构体中的偏移量,它必须为结构体类型的字段的形式。换句话说,它返回该结构起始处与该字段起始处之间的字节数。
内存对齐 计算机在加载和保存数据时,如果内存地址合理地对齐的将会更有效率。由于地址对齐这个因素,一个聚合类型的大小至少是所有字段或元素大小的总和,或者更大因为可能存在内存空洞。\
内存空洞 编译器自动添加的没有被使用的内存空间,用于保证后面每个字段或元素的地址相对于结构或数组的开始地址能够合理地对齐

下面通过排列bool、string、int16类型字段的不同顺序来演示下内存对齐时填充的内存空洞。
type BoolIntString struct {
A bool
B int16
C string
}
type StringIntBool struct {
A string
B int16
C bool
}
type IntStringBool struct {
A int16
B string
C bool
}
type StringBoolInt struct {
A string
B bool
C int16
}
func TestOffsetOf(t *testing.T) {
bis := &BoolIntString{}
isb := &IntStringBool{}
sbi := &StringBoolInt{}
sib := &StringIntBool{}
fmt.Println(unsafe.Offsetof(bis.A)) // 0
fmt.Println(unsafe.Offsetof(bis.B)) // 2
fmt.Println(unsafe.Offsetof(bis.C)) // 8
fmt.Println("")
fmt.Println(unsafe.Offsetof(isb.A)) // 0
fmt.Println(unsafe.Offsetof(isb.B)) // 8
fmt.Println(unsafe.Offsetof(isb.C)) // 24
fmt.Println("")
fmt.Println(unsafe.Offsetof(sbi.A)) // 0
fmt.Println(unsafe.Offsetof(sbi.B)) // 16
fmt.Println(unsafe.Offsetof(sbi.C)) // 18
fmt.Println("")
fmt.Println(unsafe.Offsetof(sib.A)) // 0
fmt.Println(unsafe.Offsetof(sib.B)) // 16
fmt.Println(unsafe.Offsetof(sib.C)) // 18
}
以上是针对单个结构体内的内存对齐的测试演示,当多个结构体组合在一起时还会产生内存对齐,感兴趣可以自行实践并打印内存偏移量来观察组合后产生的内存空洞。
func Alignof(x ArbitraryType) uintptr
Alignof返回类型v的对齐方式(即类型v在内存中占用的字节数);若是结构体类型的字段的形式,它会返回字段f在该结构体中的对齐方式。
type Fields struct {
Bool bool
String string
Int int
Int8 int8
Int16 int16
Int32 int32
Float32 float32
Float64 float64
}
func TestAlignof(t *testing.T) {
fields := &Fields{}
fmt.Println(unsafe.Alignof(fields.Bool)) // 1
fmt.Println(unsafe.Alignof(fields.String))// 8
fmt.Println(unsafe.Alignof(fields.Int)) // 8
fmt.Println(unsafe.Alignof(fields.Int8)) // 1
fmt.Println(unsafe.Alignof(fields.Int16)) // 2
fmt.Println(unsafe.Alignof(fields.Int32)) // 4
fmt.Println(unsafe.Alignof(fields.Float32)) // 4
fmt.Println(unsafe.Alignof(fields.Float64)) // 8
}
不同类型有着不同的内存对齐方式,总体上都是以最小可容纳单位进行对齐的,这样可以在兼顾以最小的内存空间填充来换取内存计算的高效性。
参考
加载全部内容