Java序列化
Pymjl 人气:0前言
前段时间在写RPC框架的时候用到了Kryo、Hessian、Protostuff三种序列化方式。但是当时因为急于实现功能,就只是简单的的看了一下如何使用这三种序列化方式,并没有去深入研究各自的特性,以及优点和缺点。知道现在就将RPC框架写完了之后,才有时间静下心来对三种方式做一个对比,总结。
Kryo、Hessain、Protostuff都是第三方开源的序列化/反序列化框架,要了解其各自的特性,我们首先需要知道序列化/反序列化是什么:
序列化:就是将对象转化成字节序列的过程。
反序列化:就是讲字节序列转化成对象的过程。
seriallization 序列化 : 将对象转化为便于传输的格式, 常见的序列化格式:二进制格式,字节数组,json字符串,xml字符串。
deseriallization 反序列化:将序列化的数据恢复为对象的过程
如果对序列化相关概念还不是很清楚的同学可以参照美团技术团队的序列化和反序列化
笔记参考图:
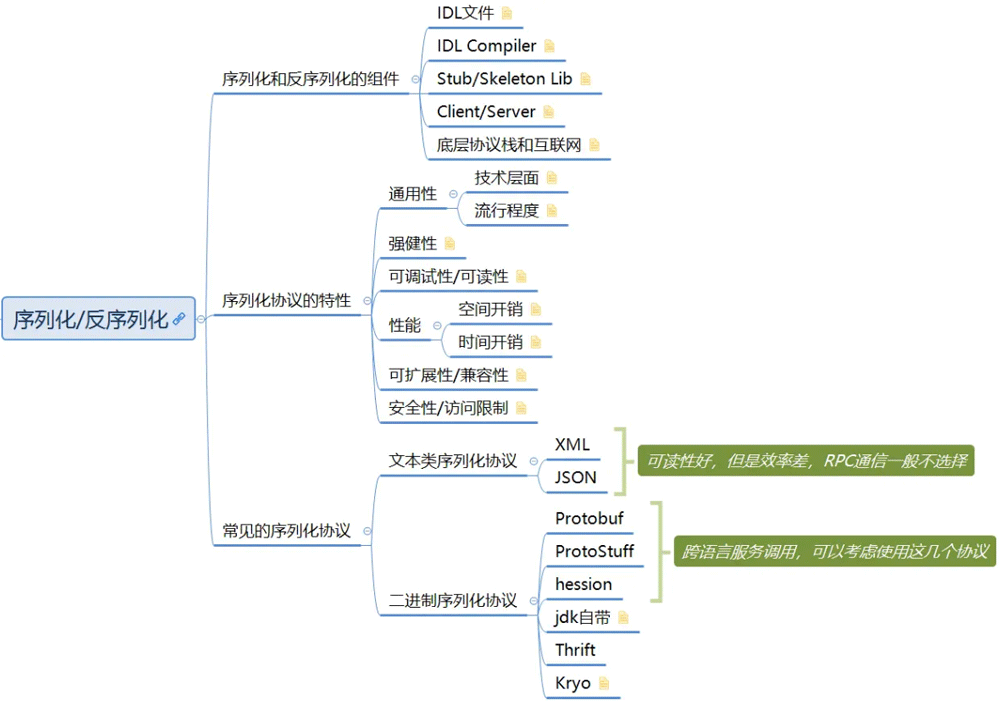
性能对比
前期准备
- 我们先创建一个新的Maven项目
- 然后导入依赖
<dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> <version>5.8.2</version> <scope>test</scope> </dependency> <!-- 代码简化 --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> </dependency> <!--kryo--> <dependency> <groupId>com.esotericsoftware</groupId> <artifactId>kryo-shaded</artifactId> <version>4.0.2</version> </dependency> <dependency> <groupId>commons-codec</groupId> <artifactId>commons-codec</artifactId> <version>1.10</version> </dependency> <!--protostuff--> <dependency> <groupId>io.protostuff</groupId> <artifactId>protostuff-core</artifactId> <version>1.7.2</version> </dependency> <dependency> <groupId>io.protostuff</groupId> <artifactId>protostuff-runtime</artifactId> <version>1.7.2</version> </dependency> <!--hessian2--> <dependency> <groupId>com.caucho</groupId> <artifactId>hessian</artifactId> <version>4.0.62</version> </dependency>
工具类:
kryo
package cuit.pymjl.utils;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import org.apache.commons.codec.binary.Base64;
import org.objenesis.strategy.StdInstantiatorStrategy;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.UnsupportedEncodingException;
/**
* @author Pymjl
* @version 1.0
* @date 2022/4/18 20:07
**/
@SuppressWarnings("all")
public class KryoUtils {
private static final String DEFAULT_ENCODING = "UTF-8";
//每个线程的 Kryo 实例
private static final ThreadLocal<Kryo> KRYO_LOCAL = new ThreadLocal<Kryo>() {
@Override
protected Kryo initialValue() {
Kryo kryo = new Kryo();
/**
* 不要轻易改变这里的配置!更改之后,序列化的格式就会发生变化,
* 上线的同时就必须清除 Redis 里的所有缓存,
* 否则那些缓存再回来反序列化的时候,就会报错
*/
//支持对象循环引用(否则会栈溢出)
kryo.setReferences(true); //默认值就是 true,添加此行的目的是为了提醒维护者,不要改变这个配置
//不强制要求注册类(注册行为无法保证多个 JVM 内同一个类的注册编号相同;而且业务系统中大量的 Class 也难以一一注册)
kryo.setRegistrationRequired(false); //默认值就是 false,添加此行的目的是为了提醒维护者,不要改变这个配置
//Fix the NPE bug when deserializing Collections.
((Kryo.DefaultInstantiatorStrategy) kryo.getInstantiatorStrategy())
.setFallbackInstantiatorStrategy(new StdInstantiatorStrategy());
return kryo;
}
};
/**
* 获得当前线程的 Kryo 实例
*
* @return 当前线程的 Kryo 实例
*/
public static Kryo getInstance() {
return KRYO_LOCAL.get();
}
//-----------------------------------------------
// 序列化/反序列化对象,及类型信息
// 序列化的结果里,包含类型的信息
// 反序列化时不再需要提供类型
//-----------------------------------------------
/**
* 将对象【及类型】序列化为字节数组
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字节数组
*/
public static <T> byte[] writeToByteArray(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream);
Kryo kryo = getInstance();
kryo.writeClassAndObject(output, obj);
output.flush();
return byteArrayOutputStream.toByteArray();
}
/**
* 将对象【及类型】序列化为 String
* 利用了 Base64 编码
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字符串
*/
public static <T> String writeToString(T obj) {
try {
return new String(Base64.encodeBase64(writeToByteArray(obj)), DEFAULT_ENCODING);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
/**
* 将字节数组反序列化为原对象
*
* @param byteArray writeToByteArray 方法序列化后的字节数组
* @param <T> 原对象的类型
* @return 原对象
*/
@SuppressWarnings("unchecked")
public static <T> T readFromByteArray(byte[] byteArray) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArray);
Input input = new Input(byteArrayInputStream);
Kryo kryo = getInstance();
return (T) kryo.readClassAndObject(input);
}
/**
* 将 String 反序列化为原对象
* 利用了 Base64 编码
*
* @param str writeToString 方法序列化后的字符串
* @param <T> 原对象的类型
* @return 原对象
*/
public static <T> T readFromString(String str) {
try {
return readFromByteArray(Base64.decodeBase64(str.getBytes(DEFAULT_ENCODING)));
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
//-----------------------------------------------
// 只序列化/反序列化对象
// 序列化的结果里,不包含类型的信息
//-----------------------------------------------
/**
* 将对象序列化为字节数组
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字节数组
*/
public static <T> byte[] writeObjectToByteArray(T obj) {
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Output output = new Output(byteArrayOutputStream);
Kryo kryo = getInstance();
kryo.writeObject(output, obj);
output.flush();
return byteArrayOutputStream.toByteArray();
}
/**
* 将对象序列化为 String
* 利用了 Base64 编码
*
* @param obj 任意对象
* @param <T> 对象的类型
* @return 序列化后的字符串
*/
public static <T> String writeObjectToString(T obj) {
try {
return new String(Base64.encodeBase64(writeObjectToByteArray(obj)), DEFAULT_ENCODING);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
/**
* 将字节数组反序列化为原对象
*
* @param byteArray writeToByteArray 方法序列化后的字节数组
* @param clazz 原对象的 Class
* @param <T> 原对象的类型
* @return 原对象
*/
@SuppressWarnings("unchecked")
public static <T> T readObjectFromByteArray(byte[] byteArray, Class<T> clazz) {
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArray);
Input input = new Input(byteArrayInputStream);
Kryo kryo = getInstance();
return kryo.readObject(input, clazz);
}
/**
* 将 String 反序列化为原对象
* 利用了 Base64 编码
*
* @param str writeToString 方法序列化后的字符串
* @param clazz 原对象的 Class
* @param <T> 原对象的类型
* @return 原对象
*/
public static <T> T readObjectFromString(String str, Class<T> clazz) {
try {
return readObjectFromByteArray(Base64.decodeBase64(str.getBytes(DEFAULT_ENCODING)), clazz);
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e);
}
}
}Hessian
package cuit.pymjl.utils;
import com.caucho.hessian.io.Hessian2Input;
import com.caucho.hessian.io.Hessian2Output;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* @author Pymjl
* @version 1.0
* @date 2022/7/2 12:39
**/
public class HessianUtils {
/**
* 序列化
*
* @param obj obj
* @return {@code byte[]}
*/
public static byte[] serialize(Object obj) {
Hessian2Output ho = null;
ByteArrayOutputStream baos = null;
try {
baos = new ByteArrayOutputStream();
ho = new Hessian2Output(baos);
ho.writeObject(obj);
ho.flush();
return baos.toByteArray();
} catch (Exception ex) {
ex.printStackTrace();
throw new RuntimeException("serialize failed");
} finally {
if (null != ho) {
try {
ho.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != baos) {
try {
baos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 反序列化
*
* @param bytes 字节
* @param clazz clazz
* @return {@code T}
*/
public static <T> T deserialize(byte[] bytes, Class<T> clazz) {
Hessian2Input hi = null;
ByteArrayInputStream bais = null;
try {
bais = new ByteArrayInputStream(bytes);
hi = new Hessian2Input(bais);
Object o = hi.readObject();
return clazz.cast(o);
} catch (Exception ex) {
throw new RuntimeException("deserialize failed");
} finally {
if (null != hi) {
try {
hi.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != bais) {
try {
bais.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}Protostuff
package cuit.pymjl.utils;
import io.protostuff.LinkedBuffer;
import io.protostuff.ProtostuffIOUtil;
import io.protostuff.Schema;
import io.protostuff.runtime.RuntimeSchema;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author Pymjl
* @version 1.0
* @date 2022/6/28 21:00
**/
public class ProtostuffUtils {
/**
* 避免每次序列化都重新申请Buffer空间
* 这个字段表示,申请一个内存空间用户缓存,LinkedBuffer.DEFAULT_BUFFER_SIZE表示申请了默认大小的空间512个字节,
* 我们也可以使用MIN_BUFFER_SIZE,表示256个字节。
*/
private static final LinkedBuffer BUFFER = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
/**
* 缓存Schema
* 这个字段表示缓存的Schema。那这个Schema是什么呢?就是一个组织结构,就好比是数据库中的表、视图等等这样的组织机构,
* 在这里表示的就是序列化对象的结构。
*/
private static final Map<Class<?>, Schema<?>> SCHEMA_CACHE = new ConcurrentHashMap<>();
/**
* 序列化方法,把指定对象序列化成字节数组
*
* @param obj 对象
* @return byte[]
*/
@SuppressWarnings("unchecked")
public static <T> byte[] serialize(T obj) {
Class<T> clazz = (Class<T>) obj.getClass();
Schema<T> schema = getSchema(clazz);
byte[] data;
try {
data = ProtostuffIOUtil.toByteArray(obj, schema, BUFFER);
} finally {
BUFFER.clear();
}
return data;
}
/**
* 反序列化方法,将字节数组反序列化成指定Class类型
*
* @param data 字节数组
* @param clazz 字节码
* @return
*/
public static <T> T deserialize(byte[] data, Class<T> clazz) {
Schema<T> schema = getSchema(clazz);
T obj = schema.newMessage();
ProtostuffIOUtil.mergeFrom(data, obj, schema);
return obj;
}
@SuppressWarnings("unchecked")
private static <T> Schema<T> getSchema(Class<T> clazz) {
Schema<T> schema = (Schema<T>) SCHEMA_CACHE.get(clazz);
if (schema == null) {
schema = RuntimeSchema.getSchema(clazz);
if (schema == null) {
SCHEMA_CACHE.put(clazz, schema);
}
}
return schema;
}
}创建一个实体类进行测试:
package cuit.pymjl.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serial;
import java.io.Serializable;
/**
* @author Pymjl
* @version 1.0
* @date 2022/7/2 12:32
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements Serializable {
@Serial
private static final long serialVersionUID = -91809837793898L;
private String name;
private String password;
private int age;
private String address;
private String phone;
}序列化后字节所占空间大小比较
编写测试类:
public class MainTest {
@Test
void testLength() {
Student student = new Student("pymjl", "123456", 18, "北京", "123456789");
int kryoLength = KryoUtils.writeObjectToByteArray(student).length;
int hessianLength = HessianUtils.serialize(student).length;
int protostuffLength = ProtostuffUtils.serialize(student).length;
System.out.println("kryoLength: " + kryoLength);
System.out.println("hessianLength: " + hessianLength);
System.out.println("protostuffLength: " + protostuffLength);
}
}运行截图:
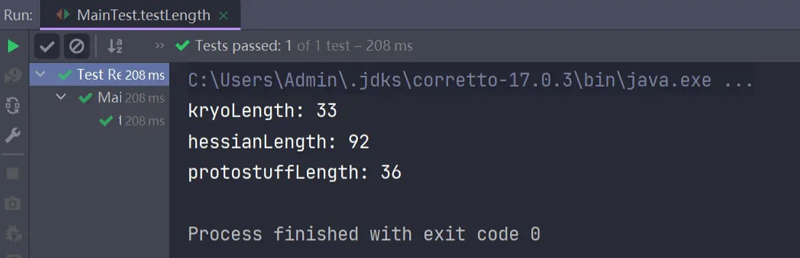
由图可知,Hessian序列化后字节所占的空间都显著比其他两种方式要大得多
其他比较
- Hessian使用固定长度存储int和long,而kryo使用变长的int和long保证这种基本数据类型序列化后尽量小,实际应用中,很大的数据不会经常出现。
- Kryo进行序列化的时候,需要传入完整类名或者利用 register() 提前将类注册到Kryo上,其类与一个int型的ID相关联,序列中只存放这个ID,因此序列体积就更小,而Hessian则是将所有类字段信息都放入序列化字节数组中,直接利用字节数组进行反序列化,不需要其他参与,因为存的东西多处理速度就会慢点
- Kryo使用不需要实现Serializable接口,Hessian则需实现
- Kryo数据类的字段增、减,序列化和反序列化时无法兼容,而Hessian则兼容,Protostuff是只能在末尾添加新字段才兼容
- Kryo和Hessian使用涉及到的数据类中必须拥有无参构造函数
- Hessian会把复杂对象的所有属性存储在一个Map中进行序列化。所以在父类、子类存在同名成员变量的情况下,Hessian序列化时,先序列化子类,然后序列化父类,因此反序列化结果会导致子类同名成员变量被父类的值覆盖
- Kryo不是线程安全的,要通过ThreadLocal或者创建Kryo线程池来保证线程安全,而Protostuff则是线程安全的
- Protostuff和Kryo序列化的格式有相似之处,都是利用一个标记来记录字段类型,因此序列化出来体积都比较小
小结
| 优点 | 缺点 | |
|---|---|---|
| Kryo | 速度快,序列化后体积小 | 跨语言支持较复杂 |
| Hessian | 默认支持跨语言 | 较慢 |
| Protostuff | 速度快,基于protobuf | 需静态编译 |
| Protostuff-Runtime | 无需静态编译,但序列化前需预先传入schema | 不支持无默认构造函数的类,反序列化时需用户自己初始化序列化后的对象,其只负责将该对象进行赋值 |
| Java | 使用方便,可序列化所有类 | 速度慢,占空间 |
加载全部内容