Java时序数据压缩算法
buttercup 人气:0背景
今年在公司内部主导了两个的行情数据系统的构建,两者均使用到了常见的时序数据压缩算法。
这里简单总结一下过程中积累的一些经验。
让我们先来思考一个问题:压缩算法生效的前提是什么?
数据本身至少要符合以下两种特性其一:
- 数据存在冗余
- 数据符合特定的概率分布
在时序数据领域,数据冗余度与相似度较高,因此天生适合进行压缩。
但对于不同类型的数据,其所适用的压缩算法也大相径庭。
下面我们逐一介绍这些数据相应的压缩算法。
整数
整型数据是构建各种应用的基石,时序型应用也不例外。
在行情数据中,存在大量的整型数据,例如:逐笔成交中的时间戳、成交量。
根据压缩算法的不同,可以将整型数据分为以下 3 类:
- 无符号整型 —— Varint
- 有符号整型 —— ZigZag
- 时间戳 —— Delta2 + Simple8b
Varint
一个 32 位的无符号整型能表达 0 - 4294967295 之间的任意数字
但这些数字在日常生活中出现的概率并不是均匀分布的,一个著名的例子是本福特定律,该定律常被用于辨别数据的真伪。
通常情况下,较小的数字出现的概率会高于极大的数据。
以年龄为例,无论人口如何分布,大部分人的年龄都位于 0 ~ 100 之间。
表示 128 仅需要 7bit 足矣,如果使用 32bit 的无符号整型进行存储,意味着至少浪费了 24bit。
幸运的是,我们能通过一种自适应编码方式来减少这种浪费 —— Varint。
public class VarIntCodec {
static int encodeInt(int v, byte[] bytes, int offset) {
if (v < 0) {
throw new IllegalStateException();
} else if (v < 128) {
bytes[offset++] = (byte) v;
} else if (v < 16384) {
bytes[offset++] = (byte) (v | 0x80);
bytes[offset++] = (byte) ((v >>> 7) & 0x7F);
} else if (v < 2097152) {
bytes[offset++] = (byte) (v | 0x80);
bytes[offset++] = (byte) ((v >>> 7) | 0x80);
bytes[offset++] = (byte) (v >>> 14);
} else if (v < 268435456) {
bytes[offset++] = (byte) (v | 0x80);
bytes[offset++] = (byte) ((v >>> 7) | 0x80);
bytes[offset++] = (byte) ((v >>> 14) | 0x80);
bytes[offset++] = (byte) (v >>> 21);
} else {
bytes[offset++] = (byte) (v | 0x80);
bytes[offset++] = (byte) ((v >>> 7) | 0x80);
bytes[offset++] = (byte) ((v >>> 14) | 0x80);
bytes[offset++] = (byte) ((v >>> 21) | 0x80);
bytes[offset++] = (byte) (v >>> 28);
}
return offset;
}
static int decodeInt(byte[] bytes, int[] offset) {
int val;
int off = offset[0];
byte b0, b1, b2, b3;
if ((b0 = bytes[off++]) >= 0) {
val = b0;
} else if ((b1 = bytes[off++]) >= 0) {
val = (b0 & 0x7F) + (b1 << 7);
} else if ((b2 = bytes[off++]) >= 0) {
val = (b0 & 0x7F) + ((b1 & 0x7F) << 7) + (b2 << 14);
} else if ((b3 = bytes[off++]) >= 0) {
val = (b0 & 0x7F) + ((b1 & 0x7F) << 7) + ((b2 & 0x7F) << 14) + (b3 << 21);;
} else {
val = (b0 & 0x7F) + ((b1 & 0x7F) << 7) + ((b2 & 0x7F) << 14) + ((b3 & 0x7F) << 21) + (bytes[off++] << 28);
}
offset[0] = off;
return val;
}
}
通过观察代码可以得知,Varint 编码并不是没有代价的:每 8bit 需要需要牺牲 1bit 作为标记位。
对于值较大的数据,Varint 需要额外的空间进行编码,从而导致更大的空间消耗。
因此使用 Varint 的前提有两个:
- 数据较小
- 没有负数
ZigZag
Varint 编码负数的效率很低:
对于 big-endian 数据来说,Varint 是通过削减 leading-zero 来实现的压缩。
而负数的首个 bit 永远非零,因此不但无法压缩数据,反而会引入不必要的空间开销。
ZigZag 通过以下方式来弥补这一缺陷:
增加小负数的 leading-zero 数量,然后再进行 Varint 编码。
其原理很简单,增加一个 ZigZag 映射:
- Varint 编码前增加映射
(n << 1) ^ (n >> 31) - Varint 解码后增加映射
(n >>> 1) ^ -(n & 1)
当 n = -1 时,Varint 编码前映射:
n = -1 -> 11111111111111111111111111111111
a = n << 1 -> 11111111111111111111111111111110
b = n >> 31 -> 11111111111111111111111111111111
a ^ b -> 00000000000000000000000000000001
当 n = -1 时,Varint 解码后映射:
m = a ^ b -> 00000000000000000000000000000001
a = m >>> 1 -> 00000000000000000000000000000000
b = -(m & 1) -> 11111111111111111111111111111111
a ^ b -> 11111111111111111111111111111111
ZigZag 映射能够有效增加小负数的 leading-zero 数量,进而提高编码效率。
ZigZag 本身也并不是完美的的:
- 占用了部分非负数的编码空间
- 对于大负数没有优化效果
Delta2
时间戳是时序数据中的一类特殊的数据,其值往往比较大,因此不适用于 Varint 编码。
但是时间戳本身具有以下两个特性:
- 非负且单调递增
- 数据间隔较为固定
前面提到过:提高整型数据压缩率的一个重要手段是增加 leading-zero 数量。
说人话就是:尽可能存储较小的数字。
因此,相较于存储时间戳,存储前后两条数据的时间间隔是一个更好的选择。
第一种方式是使用 Delta 编码:
- 第一个数据点,直接存储 t0t0
- 第 n 个数据点,则存储 tn−t0tn−t0
但是 Delta 编码的数据冗余仍然较多,因此可以改进为 Delta2 编码:
- 第一个数据点,直接存储 t0t0
- 第 n 个数据点,则存储 tn−tn−1tn−tn−1
编码后的 int64 的时间戳,可以用 int32 甚至更小的数据类型进行存储。
Simple8b
朋友,你觉得 Varint 与 Delta2 已经是整型压缩的极限了吗?
某些特殊的时序事件,可能以很高的频率出现,比如行情盘口报价。
这类数据的时间戳进行 Delta2 编码后,可能会出现以下两种情况:
- 场景1:很多连续的 0 或 1 区间
- 场景2:大部分数据分布在 0 ~ 63 的范围内
对于场景1,游程编码(RLE)是个不错的选择,但普适性较差。
对于场景2,每个值仅需 6bit 存储即可,使用 Varint 编码仍有空间浪费。
Simple8b 算法能较好的处理这一问题,其核心思想是:
将尽可能多数字打包在一个 64bit 长整型中。

Simple8b 将 64 位整数分为两部分:
selector(4bit)用于指定剩余 60bit 中存储的整数的个数与有效位长度payload(60bit)则是用于存储多个定长的整数
根据一个查找表,将数据模式匹配到最优的 selector,然后将多个数据编码至 payload
Simple8b 维护了一个查找表,可以将数据模式匹配到最优的 selector,然后将多个数据编码至 payload。编码算法可以参考这个Go实现。
需要指出的是,这个开源实现使用回溯法进行编码,其复杂度为 O(n2)O(n2)( n 为输入数据长度)。该实现对于离线压缩来说已经足够,但对于实时压缩来说稍显不足。
我们在此代码的基础上,使用查表法维护了一个状态转移数组,将编码速度提升至 O(n)O(n),使其能够应用于实时压缩。
浮点数
浮点数是一类较难压缩的数据,IEEE 705 在编码上几乎没有浪费任何一个 bit,因此无法使用类似 Varint 的方式进行压缩:
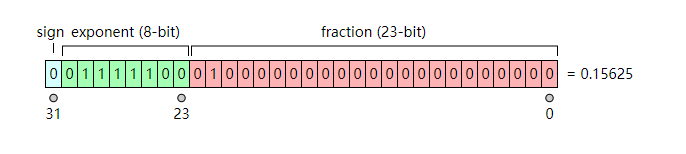
0131230signexponent (8-bit)fraction (23-bit)= 0.15625
目前常用的压缩方式可以分为两类:
- 有损压缩 —— 丢弃不必要的精度后,使用整数进行表示
- 无损压缩 —— XOR 编码
有损压缩
有损压缩需要配合业务领域知识来使用,因为首先要确定需要保留的精度。
当精度确定之后,就可以将浮点数转换为整数,然后使用 Varint 进行编码。
public static ScaledResult scaleDecimal(float[] floats, final int scaleLimit) throws CodecException {
BigDecimal[] decimals = new BigDecimal[floats.length];
for (int i=0; i<floats.length; i++) {
decimals[i] = new BigDecimal(Float.toString(floats[i]));
}
BigDecimal base = null;
int maxScale = 0;
for (BigDecimal decimal : decimals) {
Preconditions.checkState(decimal.signum() >= 0);
int scale = decimal.scale();
if (scale == 1 && maxScale == 0 && decimal.stripTrailingZeros().scale() <= 0) {
scale = 0;
}
maxScale = Math.max(maxScale, scale);
base = base == null || decimal.compareTo(base) < 0 ? decimal : base;
}
final int scale = Math.min(maxScale, scaleLimit);
final long scaledBase = base.scaleByPowerOfTen(scale).setScale(0, RoundingMode.HALF_UP).longValueExact();
long[] data = new long[decimals.length];
for (int i=0; i<decimals.length; i++) {
long scaledValue = decimals[i].scaleByPowerOfTen(scale).setScale(0, RoundingMode.HALF_UP).longValueExact();
data[i] = scaledValue - scaledBase;
}
return new ScaledResult(scale, scaledBase, data);
}
这个压缩算法的优点主要是直观,并且天然跨语言,比较适合前后端交互。
不过也存在以下局限性:
- 只能压缩精度已知的数据
- 数据中不能同时出现正数与负数
- 编码速度较慢
编码速度慢很大的原因,是在 float 转换为 BigDecimal 这一步使用Float.toString 保留数据精度。该方法不仅复杂,还生成了许多中间对象,因此效率自然不高。
一个 workaround 方式是使用高效的解析库 Ryu ,并将其返回值改为 BigDecimal,减少中间对象的生成。这一优化能够将编码速度提高约 5 倍。
无损压缩
有损压缩的一个缺点是泛用性较差,并且无法处理小数位较大的情况。
然而高冗余的浮点数据,在时序数据中比比皆是,比如某些机器监控指标,其值往往只在 0 ~ 1 之间波动。
2015 年 Fackbook 发表了一篇关于内存时序数据库的 论文,其中提出了一种基于异或算法的浮点数压缩算法。
Facebook 的研究人员在时序浮点数中发现个规律:
在同个时间序列中,大部分浮点数的占用的有效 bit 位是类似的,并且往往只有中间的一个连续区块存储着不同的数据。
因此他们想了个办法提取并只保存这部分数据:
1.将 float 转换为 bits
2.计算两个相邻 bits 的异或值 xor
3.记录 xor 的 leading-zero 与连续区块长度 block-size
4.记录 1 bit 的标记位 flag:
- 如果 leading-zero 与 block-size 与之前相同,记为 false
- 如果 leading-zero 与 block-size 与之前不同,记为 true
5.当 flag 为 true 时,记录 leading-zero 与 block-size
6.记录连续区块 block 数据,然后进入下个循环
由于大部分数据的 leading-zero 与连续区块长度 block-size 均相等,往往只需要存储 flag 与 block 数据,因此大多数情况都能有效的减少数据存储空间。
这个算法主要的难点是实现高效的 BitWriter,这个可以通过继承 ByteArrayOutputStream 并增加一个 long 类型的 buffer 实现。
abstract class BlockMeta<T extends BlockMeta<T>> {
short leadingZero;
short tailingZero;
int blockSize;
BlockMeta<T> withMeta(int leadingZero, int blockSize) {
this.leadingZero = (short) leadingZero;
this.tailingZero = (short) (length() - leadingZero - blockSize);
this.blockSize = blockSize;
return this;
}
abstract long value();
abstract int length();
boolean fallInSameBlock(BlockMeta<? extends BlockMeta<?>> block) {
return block != null && block.leadingZero == leadingZero && block.tailingZero == tailingZero;
}
}
static void encodeBlock(BitsWriter buffer, BlockMeta<?> block, BlockMeta<?> prevBlock) {
if (block.value() == 0) {
buffer.writeBit(false);
} else {
boolean ctrlBit;
buffer.writeBit(true);
buffer.writeBit(ctrlBit = ! block.fallInSameBlock(prevBlock));
if (ctrlBit) {
buffer.writeBits(block.leadingZero, 6);
buffer.writeBits(block.blockSize, 7);
}
buffer.writeBits(block.value(), block.blockSize);
}
}
static long decodeBlock(BitsReader reader, BlockMeta<?> blockMeta) {
if (reader.readBit()) {
boolean ctrlBit = reader.readBit();
if (ctrlBit) {
int leadingZero = (int) reader.readBits(6);
int blockSize = (int) reader.readBits(7);
blockMeta.withMeta(leadingZero, blockSize);
}
CodecException.malformedData(blockMeta == null);
long value = reader.readBits(blockMeta.blockSize);
return value << blockMeta.tailingZero;
}
return 0;
}
Facebook 声称,使用该算法压缩 2 小时的时序数据,每个数据点仅仅需 1.37 byte:
A two-hour block allows us to achieve a compression ratio of
1.37 bytes per data point.
经测试,该算法能够将分时数据压缩为原来的 33%,压缩率可达 60% 以上,效果显著。
字符串
时序数据中的字符串大致可以分为两类:
- 标签型 —— 数据字典
- 非标签型 —— Snappy
标签型
标签型字符串在时时序数据中更为常见,比如监控数据中的 IP 与 Metric 名称便是此类数据。
该类数据通常作为查询索引使用,其值也比较固定。因此通常使用数据字典进行压缩,将变长字符串转换为定长的整型索引。
- 一方面减少了空间占用
- 另一方面有利于构建高效的索引
当转换成整型后,还能进一步的利用 BloomFilter 与 Bitmap 等数据结构,进一步提升查询性能。
非标签型
非标签型的字符串较为少见,较少时序数据引擎支持该类型。
这类数据的值较为不可控,因此只能使用通用的压缩算法进行压缩。
为了兼顾效率,通常情况下会使用 snappy 或 lz4,两者不相伯仲。
通常情况下两者的压缩比较为接近,这方面 snappy 有微弱的优势。
不够 lz4 提供了更为灵活的压缩策略:
- 可调的压缩等级,允许使用者自行调配速度与压缩率
- 可以在压缩速度与解压速度上进行权衡,当解压与压缩机器性能不对称时较为有用
加载全部内容