C语言 sizeof unsigned signed
沐曦希 人气:0最冤枉的关键字sizeof理解
sizeof:确定一种类型在开辟空间的时候的大小。
被误解为函数
sizeof是关键字而不是函数,可以借助编译器来确定它的身份。
#include<stdio.h>
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(int));
printf("%d\n", sizeof a);
printf("%d\n", sizeof int);//error
return 0;
}


sizeof(a)可以去掉()说明sizeof不是函数,是关键字(操作符),因为函数后面的括号是不能省略的。
sizeof在计算变量所占的空间大小时,可以省略括号,而计算类型大小时,不能省略括号。
注:sizeof操作符里面不能有其他运算,否则达不到预期的结果。
sizeof(int)*p 表示什么意思
#include<stdio.h>
int main()
{
int* p = NULL;
int arr[10] = { 0 };
int* parr[3];
printf("%d\n", sizeof(p));//p是指针变量,指针变量的大小是固定的4或者8
printf("%d\n", sizeof(*p));//指针变量所指的变量所占的内存的大小
printf("%d\n", sizeof(arr));//sizeof(arr)中arr指整个数组,即10个int类型元素。
printf("%d\n", sizeof(arr[10]));//数组越界
printf("%d\n", sizeof(&arr));//&arr取得是整个数组的地址
printf("%d\n", sizeof(&arr[0]));//取的是首元素的地址,相当于指针
printf("%d\n", sizeof(parr));//parr指整个数组。
return 0;
}
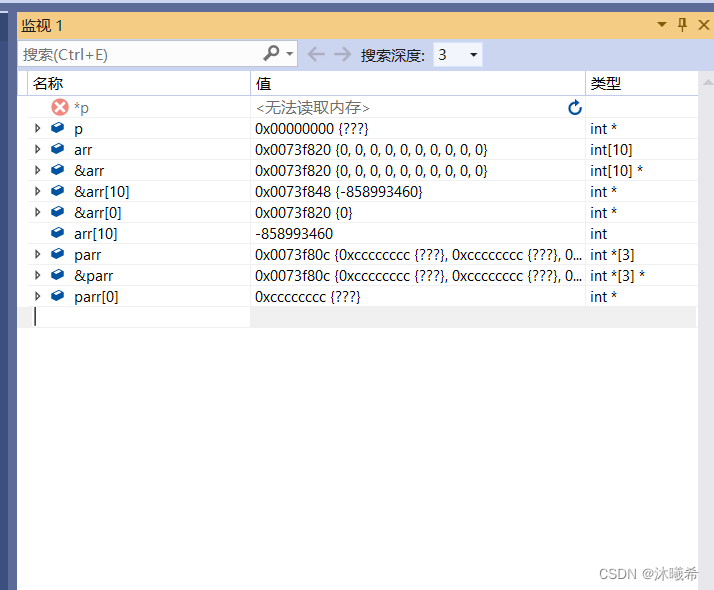
指针变量p所指向的变量类型为char,指针数组parr中存储的指针变量的类型为char时候:

signed与unsigned 关键字
有符号整数vs无符号整数
char
unsigned char//无符号的字符类型
//取值范围是0~255
//无符号表示二进制的最高位不表示正负,该整型只为正数。
//但可以储存负数,只是值会变成很大的正数
signed char//有符号字符
//取值范围是-128~127
//因为字符的本质是ASCII码值,在内存中以ASCII码值进行存储,所以划分到整型家族
short
unsigned short [int]//无符号短整型
signed short [int]//有符号短整型
int
unsigned int//无符号整型
signed int//有符号整型
long
unsigned long [int]//无符号长整型
signed long [int]//有符号整型
long long
unsigned long long [int]//无符号更长的整型
signed long long [int] //有符号更长的整型

char到底是signed char (取值范围-128~127)还是unsigned char(取值范围0~255)
标准是为定义的,取决于编译器的实现,小沐所使用的VS2019环境的char是signed char。
char a;// signed char a 或者 unsigned char a
int 标准定义是 signed int ,有符号整型,4个字节,32个比特位
int a = 10;//signed int a //转换成二进制是00000000000000000000000000001010
整形在内存的存储
一个变量的创建是要在内存中开辟空间的,空间的大小是根据不同的类型而决定的。
那么,数据在所开辟内存中到底是如何存储的呢?
计算机存储数值时时存储的该数值的二进制的补码的,而补码是通过原码和反码进行换算得到的。
任何数据在计算机中,都必须转换成二进制,计算机只认识二进制。
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码
反码+1就得到补码。
int a = 10; //00000000000000000000000000001010 a的原码 //00000000000000000000000000001010 a的反码 //00000000000000000000000000001010 a的补码 //0x0000000a int b = -10; //10000000000000000000000000001010 b的原码 //0x8000000a //11111111111111111111111111110101 b的反码 //0xfffffff5 //11111111111111111111111111110110 b的补码 //0xfffffff6
符号位+数据位
有符号数且正数,原码,反码和补码相同。
有符号数且负数,原码,反码和补码不相同,需要通过计算转换。计算机内存储的整型必须是补码,符号位要参与计算的。
无符号数:没有符号位,原码,反码和补码相同。
int a = 20;
int b = -10;
我们知道,编译器为 a 分配四个字节的空间。那如何存储呢?
首先,对于有符号数,一定要能表示该数据是正数还是负数。所以我们一般用最高比特位来进行充当符号位。
原码、反码、补码
计算机中的有符号数有三种表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位三种表示方法各不相同。
如果一个数据是负数,那么就要遵守下面规则进行转化:
原码:直接将二进制按照正负数的形式翻译成二进制就可以。
反码:将原码的符号位不变,其他位依次按位取反就可以得到了。
补码:反码+1就得到补码。
如果一个数据是正数,那么它的原反补都相同。
无符号数:不需要转化,也不需要符号位,原反补相同。
对于整形来说:数据存放内存中其实存放的是补码。
//字面值转补码
int a = 20;
//20是正整数
//0000 0000 0000 0000 0000 0000 0001 0100
int b = -10;
//-10是正整数
//1000 0000 0000 0000 0000 0000 0000 1010
//1111 1111 1111 1111 1111 1111 1111 0101
//1111 1111 1111 1111 1111 1111 1111 0110
补码转原码
方法一:先-1,在符号位不变,按位取反。
方法二:将原码到补码的过程在来一遍。
原反补转换需要通过计算机硬件来完成,

可以使用一条硬件电路就能完成原反补码的转换。
存储的本质
#include<stdio.h>
int main()
{
unsigned int a = -10;
//1000 0000 0000 0000 0000 0000 0000 1010-- -10的原码
//1111 1111 1111 1111 1111 1111 1111 0110-- -10的补码
printf("%d\n", a);
printf("%u\n", a);
return 0;
}
无符号整型变量a定义时,先有空间,再有内容,先将内容转换成二进制。 整型再存储的时候,空间不关心内容的。
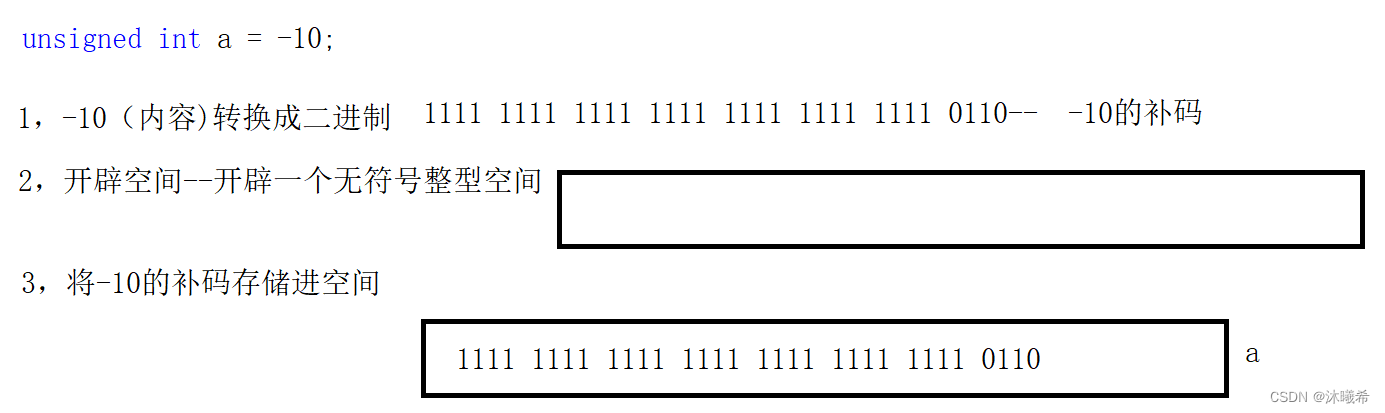
在将数据保存在空间内的时候,数据已经被转换成二进制的补码。
数据带上类型才有意义。类型觉得了如何解释空间内部保存的二进制序列。
变量的类型什么时候起效果?
在读取数据的过程中,变量的类型起效果。
//变量的存和取过程的结论:
//存:字面数据必须先转成补码,在放入空间当中。所以,所谓符号位,完全看数据本身是否携带±号。和变量是否有符号
无关!
//取:取数据一定要先看变量本身类型,然后才决定要不要看最高符号位。如果不需要,直接二进制转成十进制。如果需要,则需要转成原码,然后才能识别。(当然,最高符号位在哪里,又要明确大小端)
十进制二进制快速转化
口诀:1后面跟n个0,就是2的n次方
67->64++1-->2^6+2^1+2^0
0000 0000 0000 0000 0000 0000 00100 0011
1->2^0
10->2^1
100->2^2
1000->2^3
后面跟n给比特位就是2^n
2^9->1000000000
为什么存储的是补码
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)。此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
大小端
什么大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
例如:
0x11223344

为什么有大端和小端:
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
加载全部内容