python排序并标上序号
Jepson2017 人气:0python排序并标上序号
需求:利用python实现排序功能
测试数据:data.csv
"id","date","amount" "1","2019-02-08","6214.23" "1","2019-02-08","6247.32" "1","2019-02-09","85.63" "2","2019-02-14","943.18" "2","2019-02-15","369.76" "2","2019-02-18","795.15" "2","2019-02-19","715.65" "2","2019-02-21","537.71" "2","2019-02-24","1037.71" "3","2019-02-09","967.36" "3","2019-02-10","85.69" "3","2019-02-12","769.85" "3","2019-02-13","943.86" "3","2019-02-19","843.86" "3","2019-02-11","85.69" "3","2019-02-14","843.86" "1","2019-02-10","985.63" "1","2019-02-09","285.63" "1","2019-02-11","1285.63"
第一种常见排序: 将上面数据按照amount字段进行排序
import pandas as pd filename="data.csv" df=pd.read_csv(filename) #增加一个rank排序字段 df['rank']=df['amount'].rank(ascending=0, method='first')
说明:ascending :1 表示升序,0表示降序
method:此参数的作用是,当遇到两个值相同时,排序处理的方式。可以取的值有 first、max、min、dense
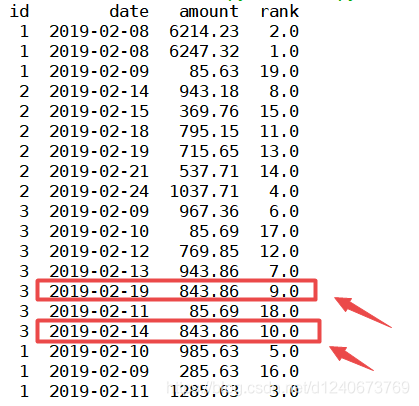
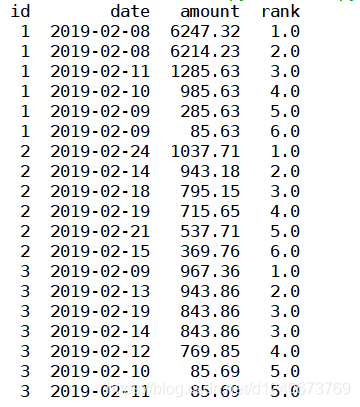
(1)method =‘first’ 时
表示排序时,序号不会重复且是连续的,遇到相同的值时,会按照数据的先后顺序标序号,如下图:
df['rank']=df['amount'].rank(ascending=0, method='first') print(df)
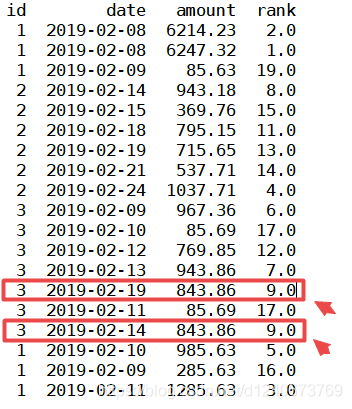
(2)method='min’时
表示排序时,遇到相同的值时,后面数的序号与最先出现的数的序号保持一致,如下图,843.86值重复两次,排名均为9,且排序中没有序号10(序号不连续)
df['rank']=df['amount'].rank(ascending=0, method='min') print(df)
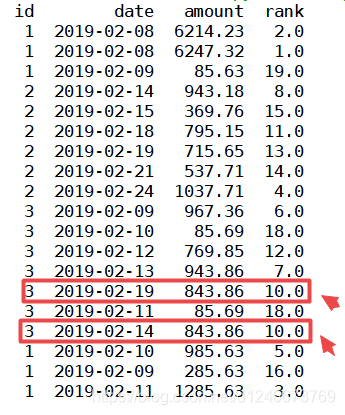
(3)method='max’时
表示排序时,遇到相同的值时,后面数的序号与最后出现的数的序号保持一致,如下图,843.86值重复两次,排名均为10,且排序中没有序号9(序号不连续)
df['rank']=df['amount'].rank(ascending=0, method='max') print(df)
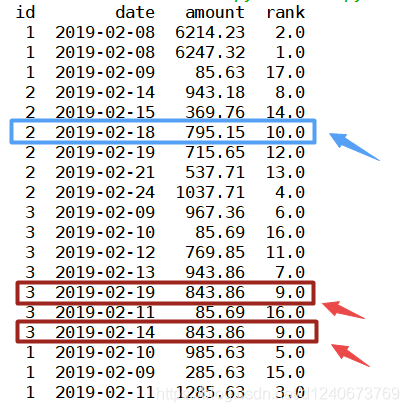
(4)method='dense’时
表示排序时,遇到相同的值时,重复值序号保持一致,如下图,843.86值重复两次,排名均为9,且下一个数序号为10,序号保持连续
df['rank']=df['amount'].rank(ascending=0, method='dense') print(df)
第二种常见排序:组内排序 ,将上面数据根据id分组,并按照amount字段进行组内排序
df['rank']=df['amount'].groupby(df['id']).rank(ascending=0, method='dense') #对结果按照id和rank进行升序排列 data=df.sort_values(by=['id','rank'],ascending=(1,1))
Python常见排序算法汇总
所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。排序算法,就是如何使得记录按照要求排列的方法。
排序的稳定性
经过某种排序后,如果两个记录序号同等,且两者在原无序记录中的先后秩序依然保持不变,则称所使用的排序方法是稳定的,反之是不稳定的。
内排序和外排序
- 内排序:排序过程中,待排序的所有记录全部放在内存中
- 外排序:排序过程中,使用到了外部存储。
通常讨论的都是内排序。
影响内排序算法性能的三个因素:
- 时间复杂度:即时间性能,高效率的排序算法应该是具有尽可能少的关键字比较次数和记录的移动次数
- 空间复杂度:主要是执行算法所需要的辅助空间,越少越好。
- 算法复杂性。主要是指代码的复杂性。
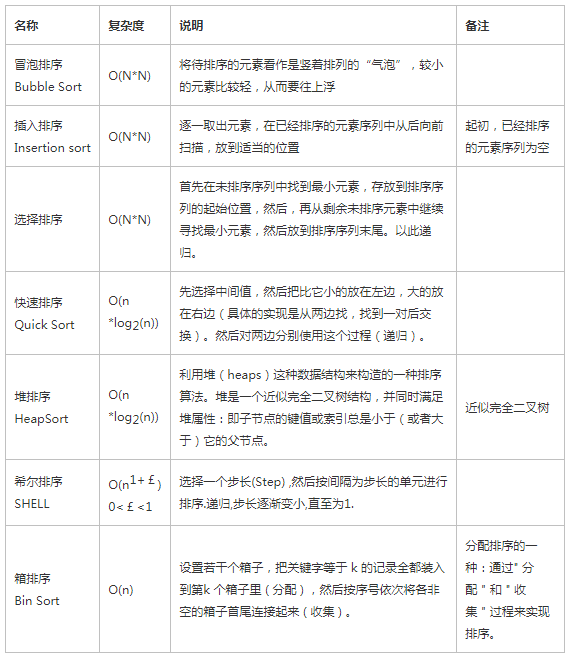
Python常用排序算法
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容