Elasticsearches集群搭建数据分片
Jeff的技术栈 人气:0Elasticsearch高级之集群搭建,数据分片
es使用两种不同的方式来发现对方:
广播
单播
也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成
广播方式
当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328。而其他的es实例使用同样的集群名称响应了这个请求。
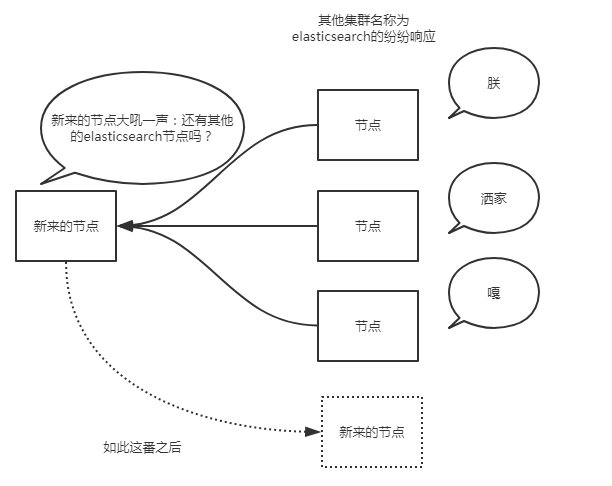
一般这个默认的集群名称就是上面的cluster_name对应的elasticsearch。通常而言,广播是个很好地方式。想象一下,广播发现就像你大吼一声:别说话了,再说话我就发红包了!然后所有听见的纷纷响应你。
但是,广播也有不好之处,过程不可控。
- 在本地单独的目录中,再复制一份elasticsearch文件
- 分别启动bin目录中的启动文件
- 在浏览器里输入:http://127.0.0.1:9200/_cluster/health?pretty
- 通过number_of_nodes可以看到,目前集群中已经有了两个节点了
单播方式
当节点的ip(想象一下我们的ip地址是不是一直在变)不经常变化的时候,或者es只连接特定的节点。单播发现是个很理想的模式。使用单播时,我们告诉es集群其他节点的ip及(可选的)端口及端口范围。我们在elasticsearch.yml配置文件中设置:
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]
大家就像交换微信名片一样,相互传传就加群了.....
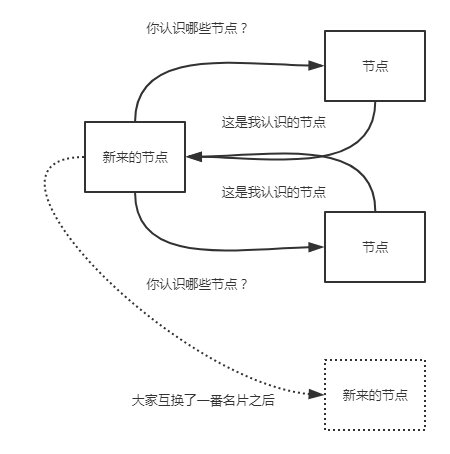
一般的,我们没必要关闭单播发现,如果你需要广播发现的话,配置文件中的列表保持空白即可。
#现在,我们为这个集群增加一些单播配置,打开各节点内的\config\elasticsearch.yml文件。每个节点的配置如下(原配置文件都被注释了,可以理解为空,我写好各节点的配置,直接粘贴进去,没有动注释的,出现问题了好恢复): #1 elasticsearch2节点,,集群名称是my_es1,集群端口是9300;节点名称是node1,监听本地9200端口,可以有权限成为主节点和读写磁盘(不写就是默认的)。 cluster.name: my_es1 node.name: node1 network.host: 127.0.0.1 http.port: 9200 transport.tcp.port: 9300 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 2 elasticsearch3节点,集群名称是my_es1,集群端口是9302;节点名称是node2,监听本地9202端口,可以有权限成为主节点和读写磁盘。 cluster.name: my_es1 node.name: node2 network.host: 127.0.0.1 http.port: 9202 transport.tcp.port: 9302 node.master: true node.data: true discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 3 elasticsearch3节点,集群名称是my_es1,集群端口是9303;节点名称是node3,监听本地9203端口,可以有权限成为主节点和读写磁盘。 cluster.name: my_es1 node.name: node3 network.host: 127.0.0.1 http.port: 9203 transport.tcp.port: 9303 discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"] # 4 elasticsearch4节点,集群名称是my_es1,集群端口是9304;节点名称是node4,监听本地9204端口,仅能读写磁盘而不能被选举为主节点。 cluster.name: my_es1 node.name: node4 network.host: 127.0.0.1 http.port: 9204 transport.tcp.port: 9304 node.master: false node.data: true discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
由上例的配置可以看到,各节点有一个共同的名字my_es1,但由于是本地环境,所以各节点的名字不能一致,我们分别启动它们,它们通过单播列表相互介绍,发现彼此,然后组成一个my_es1集群。谁是老大则是要看谁先启动了!
选取主节点
无论是广播发现还是到单播发现,一旦集群中的节点发生变化,它们就会协商谁将成为主节点,elasticsearch认为所有节点都有资格成为主节点。
如果集群中只有一个节点,那么该节点首先会等一段时间,如果还是没有发现其他节点,就会任命自己为主节点。
对于节点数较少的集群,我们可以设置主节点的最小数量,虽然这么设置看上去集群可以拥有多个主节点。
实际上这么设置是告诉集群有多少个节点有资格成为主节点。
怎么设置呢?修改配置文件中的:
discovery.zen.minimum_master_nodes: 3
一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2。这么着是为了防止脑裂(split brain)问题。
什么是脑裂
脑裂这个词描述的是这样的一个场景:
(通常是在重负荷或网络存在问题时)elasticsearch集群中一个或者多个节点失去和主节点的通信,然后各节点就开始选举新的主节点,继续处理请求。
这个时候,可能有两个不同的集群在相互运行着,这就是脑裂一词的由来,因为单一集群被分成了两部分。
为了防止这种情况的发生,我们就需要设置集群节点的总数,规则就是节点总数除以2再加一(半数以上)。这样,当一个或者多个节点失去通信,小老弟们就无法选举出新的主节点来形成新的集群。因为这些小老弟们无法满足设置的规则数量。
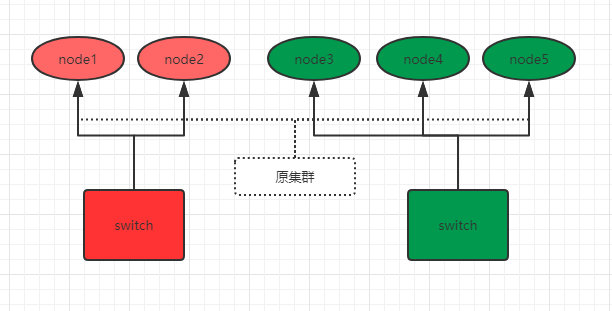
我们通过下图来说明如何防止脑裂。比如现在,有这样一个5个节点的集群,并且都有资格成为主节点:
为了防止脑裂,我们对该集群设置参数:
discovery.zen.minimum_master_nodes: 3 # 3=5/2+1
之前原集群的主节点是node1,由于网络和负荷等原因,原集群被分为了两个switch:node1 、2和node3、4、5。
因为minimum_master_nodes参数是3,所以node3、4、5可以组成集群,并且选举出了主节点node3。
而node1、2节点因为不满足minimum_master_nodes条件而无法选举,只能一直寻求加入集群(还记得单播列表吗?),要么网络和负荷恢复正常后加入node3、4、5组成的集群中,要么就是一直处于寻找集群状态,这样就防止了集群的脑裂问题。
除了设置minimum_master_nodes参数,有时候还需要设置node_master参数,比如有两个节点的集群,如果出现脑裂问题,那么它们自己都无法选举,因为都不符合半数以上。
这时我们可以指定node_master,让其中一个节点有资格成为主节点,另外一个节点只能做存储用。当然这是特殊情况。
那么,主节点是如何知道某个节点还活着呢?这就要说到错误识别了。
错误识别
其实错误识别,就是当主节点被确定后,建立起内部的ping机制来确保每个节点在集群中保持活跃和健康,这就是错误识别。
主节点ping集群中的其他节点,而且每个节点也会ping主节点来确认主节点还活着,如果没有响应,则宣布该节点失联。想象一下,老大要时不常的看看(循环)小弟们是否还活着,而小老弟们也要时不常的看看老大还在不在,不在了就赶紧再选举一个出来!
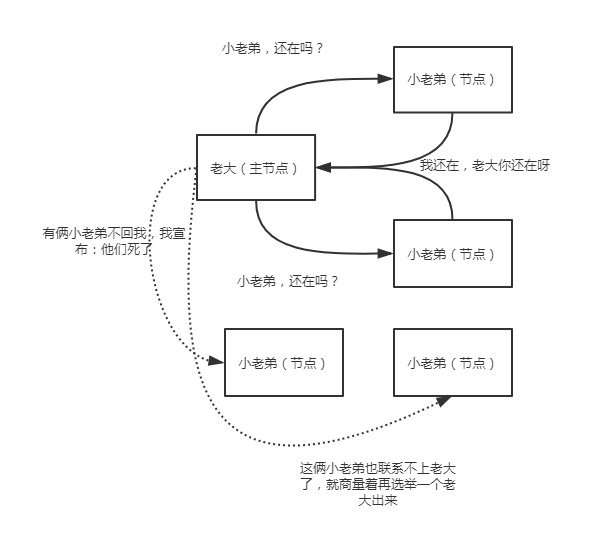
但是,怎么看?多久没联系算是失联?这些细节都是可以设置的,不是一拍脑门子,就说某个小老弟挂了!在配置文件中,可以设置:
discovery.zen.fd.ping_interval: 1 discovery.zen.fd.ping_timeout: 30 discovery_zen.fd.ping_retries: 3
每个节点每隔discovery.zen.fd.ping_interval的时间(默认1秒)发送一个ping请求,等待discovery.zen.fd.ping_timeout的时间(默认30秒),并尝试最多discovery.zen.fd.ping_retries次(默认3次),无果的话,宣布节点失联,并且在需要的时候进行新的分片和主节点选举。
根据开发环境,适当修改这些值。
加载全部内容