git版本控制系统
繁华似锦Fighting 人气:01、什么是版本控制系统
版本控制是一种记录一个或若干个文件内容变化,以便将来查阅特定版本修订情况的系统。版本控制系统不仅可以应用于软件源代码的文本文件,而且可以对任何类型的文件进行版本控制。
有了它你就可以将某个文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较不同版本文件的变化细节,查出最后是谁修改了哪个地方。也就是无论文件最后被修改成什么样子,你都可以轻松恢复到原先的样子,但是额外增加的工作量却微乎其微。
2、我们为什么要用版本控制
世界上无数大大小小的开发项目,都在使用各种各样的版本控制系统,原因在于它的优点对于一个项目开发来说是无比重要。
比如一个最简单的开发团队,也许就两三个人,他们共同完成一个软件的开发。每个人都在修改、添加、删除着自己本地硬盘上的代码,当他们需要把这些代码汇总起来时,麻烦出现了。到底谁改了哪些文件?具体是文件里的哪部分被改动过?A人员修改的内容会不会把B人员的修改的内容覆盖掉,汇总工作就变得很危险,需要非常小心,一旦出错后果不堪设想。显然此时效率将会是无比的低下,如果某个地方出错,可能整个汇总工作就要重来一遍。这只是两三人的小团队,如果是几十人几百人的大团队呢?那将会是噩梦。
如果这个团队采用了版本控制,那么版本控制软件在每次提交文件的时候,都会主动合并所有人的修改,并解决可能发生的冲突。每个人手里一直都是汇总好的代码,当开发进行到一定阶段,可以直接拿去测试,不需要再有额外的工作来浪费时间。
3、版本管理系统的演变
(1)本地版本控制系统
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。
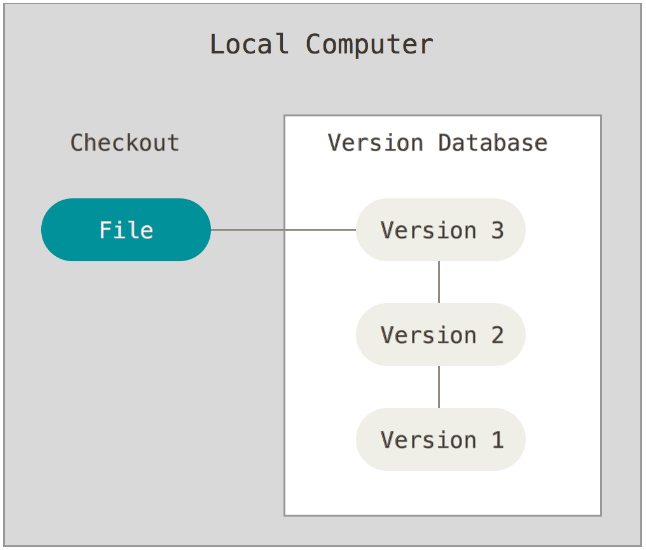
这种形式主要实现了基本的代码版本管理,但缺点是无法让多人同时对一个版本库进行修改。这个也和当时软件规模不够大有关,也没有这样的需求。
(2)集中化版本控制系统
接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。 这类系统,诸如 CVS、Subversion等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。 多年以来,这已成为版本控制系统的标准做法。
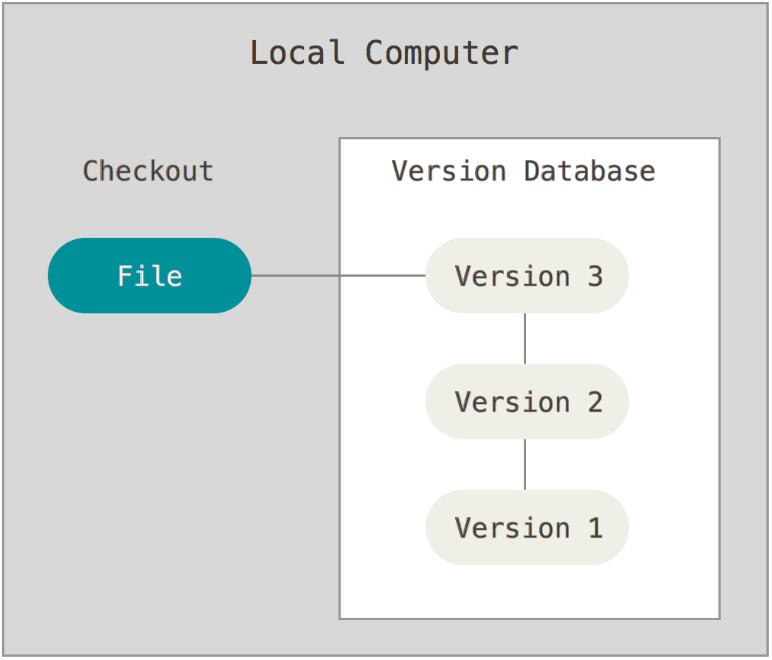
这种做法带来了许多好处,特别是相较于老式的本地 VCS 来说。 现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
事分两面,有好有坏,集中管理的服务器最显而易见的缺点是中央服务器的单点故障问题。 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据,包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。 本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
集中式版本控制系统另外一个大的问题就是必须联网才能工作,如果不能连接到中央服务器上,就不能对文件进行提交,还原,对比等操作。
(3)分布式版本控制系统
于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。 在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像,把本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
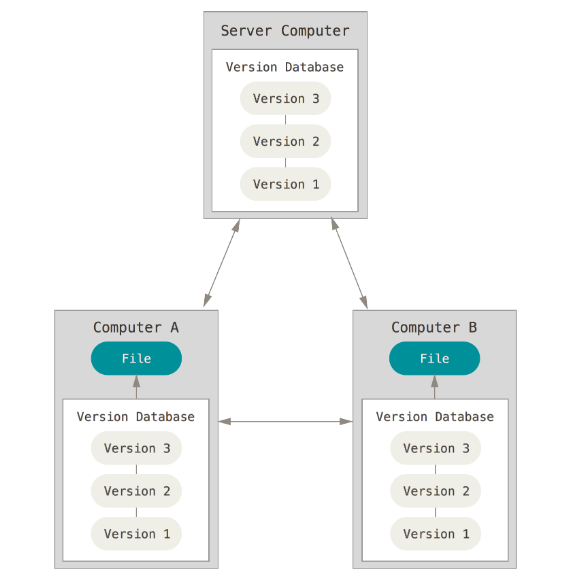
许多这类系统都可以指定和若干不同的远端代码仓库进行交互。因此你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
参考:
加载全部内容