Pandas删除指定值所在行
DonngZH 人气:24前言
使用pandas对数据操作,筛选数据时,根据任务要求有时不仅要某列中存在空值的行,并且要删除某列中指定值所在行。
1.data.dropna()
默认参数: data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
1-1 axis确定删除存在缺失值的行或者是列
#删除含有缺失值的行 axis=0或axis='index' #删除含有缺失值的列 axis=1或axis='columns'
1-2 how 确定存在缺失值时,是否删除行或者列
how='all'或how=‘any'。 how='all'时表示删除全是缺失值的行(列) how='any'时表示删除只要含有缺失值的行(列)
1-3 thresh=n表示保留至少含有n个非na数值的行
data.dropna(thresh=2)
1-4 subset确定要在哪些列中查找缺失值
#在source和target两列中查找缺失值 data.drop(subset = ["source","target"])
1-5 inplace确定是否直接在原DataFrame修改
#删除缺失值后不在原data上修改 inplace = False #删除缺失值后在原data上修改 inplace = True
2.data.drop
默认参数:
data.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors='raise',
)2-1 labels 指定行或者列的名称
#参数axis为0表示在0轴(列)上搜索名为“姓名”的对象,然后删除对象“姓名”对应的行。
data.drop("姓名",axis = 0)
#参数axis为0表示在1轴(行)上搜索名为“姓名”的对象,然后删除对象“姓名”对应的列。
data.drop("姓名",axis = 1)2-2 index 指定要删除的行
#删除data中索引为0和1的行 data.drop(index = [0,1])
2-3 columns 指定要删除的列
#删除data中列名为“source”和“target”的列 data.drop(columns=['source', 'target'])
3.实例
任务需求:删掉“ZH_Term_len”列中值为0的全部行。

3-1 统计0的数量
#统计“ZH_Term_len”一列中有多少个0 data["ZH_Term_len"].value_counts()

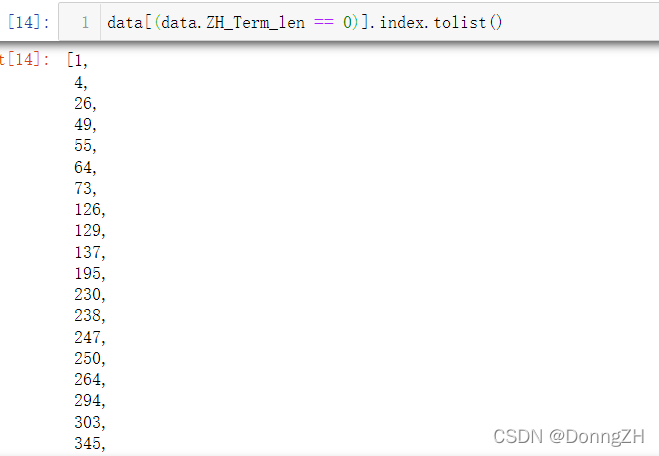
3-2 找出0的索引
data[(data.ZH_Term_len == 0)].index.tolist()
3-3 使用drop函数以及index参数删除所在的行
data = data.drop(index = data[(data.ZH_Term_len == 0)].index.tolist())
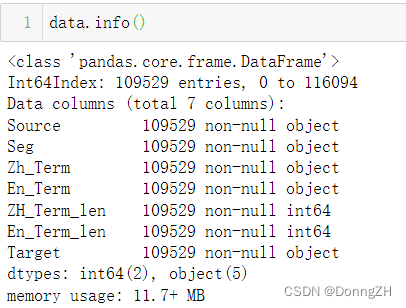
3-4 查看数据
data.info()
3-5 将索引重新排序
#会将标签重新从零开始顺序排序,使用参数设置drop=True删除旧的索引序列 data = data.reset_index(drop=True)
3-6 统计“ZH_Term_len”列中值的数量

统计后发现,“ZH_Term_len”列中值为0的行已经全部被删除掉。
总结
加载全部内容