Tensorflow TFRecord生成与读取
blackmanba_084b 人气:0一、为什么使用TFRecord?
正常情况下我们训练文件夹经常会生成 train, test 或者val文件夹,这些文件夹内部往往会存着成千上万的图片或文本等文件,这些文件被散列存着,这样不仅占用磁盘空间,并且再被一个个读取的时候会非常慢,繁琐。占用大量内存空间(有的大型数据不足以一次性加载)。此时我们TFRecord格式的文件存储形式会很合理的帮我们存储数据。TFRecord内部使用了“Protocol Buffer”二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个TFRecord文件,来提高处理效率。
二、 生成TFRecord简单实现方式
我们可以分成两个部分来介绍如何生成TFRecord,分别是TFRecord生成器以及样本Example模块。
- TFRecord生成器
writer = tf.python_io.TFRecordWriter(record_path) writer.write(tf_example.SerializeToString()) writer.close()
这里面writer就是我们TFrecord生成器。接着我们就可以通过writer.write(tf_example.SerializeToString())来生成我们所要的tfrecord文件了。这里需要注意的是我们TFRecord生成器在写完文件后需要关闭writer.close()。这里tf_example.SerializeToString()是将Example中的map压缩为二进制文件,更好的节省空间。那么tf_example是如何生成的呢?那就是下面所要介绍的样本Example模块了。
- Example模块
首先们来看一下Example协议块是什么样子的。
message Example {
Features features = 1;
};
message Features {
map<string, Feature> feature = 1;
};
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
我们可以看出上面的tf_example可以写入的数据形式有三种,分别是BytesList, FloatList以及Int64List的类型。那我们如何写一个tf_example呢?下面有一个简单的例子。
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
tf_example = tf.train.Example(
features=tf.train.Features(feature={
'image/encoded': bytes_feature(encoded_jpg),
'image/format': bytes_feature('jpg'.encode()),
'image/class/label': int64_feature(label),
'image/height': int64_feature(height),
'image/width': int64_feature(width)}))
下面我们来好好从外部往内部分解来解释一下上面的内容。
(1)tf.train.Example(features = None) 这里的features是tf.train.Features类型的特征实例。
(2)tf.train.Features(feature = None) 这里的feature是以字典的形式存在,*key:要保存数据的名字 value:要保存的数据,但是格式必须符合tf.train.Feature实例要求。
三、 生成TFRecord文件完整代码实例
首先我们需要提供数据集

图片文件夹
通过图片文件夹我们可以知道这里面总共有七种分类图片,类别的名称就是每个文件夹名称,每个类别文件夹存储各自的对应类别的很多图片。下面我们通过一下代码(generate_annotation_json.py和generate_tfrecord.py)生成train.record。
- generate_annotation_json.py
# -*- coding: utf-8 -*-
# @Time : 2018/11/22 22:12
# @Author : MaochengHu
# @Email : wojiaohumaocheng@gmail.com
# @File : generate_annotation_json.py
# @Software: PyCharm
import os
import json
def get_annotation_dict(input_folder_path, word2number_dict):
label_dict = {}
father_file_list = os.listdir(input_folder_path)
for father_file in father_file_list:
full_father_file = os.path.join(input_folder_path, father_file)
son_file_list = os.listdir(full_father_file)
for image_name in son_file_list:
label_dict[os.path.join(full_father_file, image_name)] = word2number_dict[father_file]
return label_dict
def save_json(label_dict, json_path):
with open(json_path, 'w') as json_path:
json.dump(label_dict, json_path)
print("label json file has been generated successfully!")
- generate_tfrecord.py
# -*- coding: utf-8 -*-
# @Time : 2018/11/23 0:09
# @Author : MaochengHu
# @Email : wojiaohumaocheng@gmail.com
# @File : generate_tfrecord.py
# @Software: PyCharm
import os
import tensorflow as tf
import io
from PIL import Image
from generate_annotation_json import get_annotation_dict
flags = tf.app.flags
flags.DEFINE_string('images_dir',
'/data2/raycloud/jingxiong_datasets/six_classes/images',
'Path to image(directory)')
flags.DEFINE_string('annotation_path',
'/data1/humaoc_file/classify/data/annotations/annotations.json',
'Path to annotation')
flags.DEFINE_string('record_path',
'/data1/humaoc_file/classify/data/train_tfrecord/train.record',
'Path to TFRecord')
FLAGS = flags.FLAGS
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def process_image_channels(image):
process_flag = False
# process the 4 channels .png
if image.mode == 'RGBA':
r, g, b, a = image.split()
image = Image.merge("RGB", (r,g,b))
process_flag = True
# process the channel image
elif image.mode != 'RGB':
image = image.convert("RGB")
process_flag = True
return image, process_flag
def process_image_reshape(image, resize):
width, height = image.size
if resize is not None:
if width > height:
width = int(width * resize / height)
height = resize
else:
width = resize
height = int(height * resize / width)
image = image.resize((width, height), Image.ANTIALIAS)
return image
def create_tf_example(image_path, label, resize=None):
with tf.gfile.GFile(image_path, 'rb') as fid:
encode_jpg = fid.read()
encode_jpg_io = io.BytesIO(encode_jpg)
image = Image.open(encode_jpg_io)
# process png pic with four channels
image, process_flag = process_image_channels(image)
# reshape image
image = process_image_reshape(image, resize)
if process_flag == True or resize is not None:
bytes_io = io.BytesIO()
image.save(bytes_io, format='JPEG')
encoded_jpg = bytes_io.getvalue()
width, height = image.size
tf_example = tf.train.Example(
features=tf.train.Features(
feature={
'image/encoded': bytes_feature(encode_jpg),
'image/format': bytes_feature(b'jpg'),
'image/class/label': int64_feature(label),
'image/height': int64_feature(height),
'image/width': int64_feature(width)
}
))
return tf_example
def generate_tfrecord(annotation_dict, record_path, resize=None):
num_tf_example = 0
writer = tf.python_io.TFRecordWriter(record_path)
for image_path, label in annotation_dict.items():
if not tf.gfile.GFile(image_path):
print("{} does not exist".format(image_path))
tf_example = create_tf_example(image_path, label, resize)
writer.write(tf_example.SerializeToString())
num_tf_example += 1
if num_tf_example % 100 == 0:
print("Create %d TF_Example" % num_tf_example)
writer.close()
print("{} tf_examples has been created successfully, which are saved in {}".format(num_tf_example, record_path))
def main(_):
word2number_dict = {
"combinations": 0,
"details": 1,
"sizes": 2,
"tags": 3,
"models": 4,
"tileds": 5,
"hangs": 6
}
images_dir = FLAGS.images_dir
#annotation_path = FLAGS.annotation_path
record_path = FLAGS.record_path
annotation_dict = get_annotation_dict(images_dir, word2number_dict)
generate_tfrecord(annotation_dict, record_path)
if __name__ == '__main__':
tf.app.run()
* 这里需要说明的是generate_annotation_json.py是为了得到图片标注的label_dict。通过这个代码块可以获得我们需要的图片标注字典,key是图片具体地址, value是图片的类别,具体实例如下:
{
"/images/hangs/862e67a8-5bd9-41f1-8c6d-876a3cb270df.JPG": 6,
"/images/tags/adc264af-a76b-4477-9573-ac6c435decab.JPG": 3,
"/images/tags/fd231f5a-b42c-43ba-9e9d-4abfbaf38853.JPG": 3,
"/images/hangs/2e47d877-1954-40d6-bfa2-1b8e3952ebf9.jpg": 6,
"/images/tileds/a07beddc-4b39-4865-8ee2-017e6c257e92.png": 5,
"/images/models/642015c8-f29d-4930-b1a9-564f858c40e5.png": 4
}
- 如何运行代码
(1)首先我们的文件夹构成形式是如下结构,其中images_root是图片根文件夹,combinations, details, sizes, tags, models, tileds, hangs分别存放不同类别的图片文件夹。
-<images_root>
-<combinations>
-图片.jpg
-<details>
-图片.jpg
-<sizes>
-图片.jpg
-<tags>
-图片.jpg
-<models>
-图片.jpg
-<tileds>
-图片.jpg
-<hangs>
-图片.jpg
(2)建立文件夹TFRecord,并将generate_tfrecord.py和generate_annotation_json.py这两个python文件放入文件夹内,需要注意的是我们需要将 generate_tfrecord.py文件中字典word2number_dict换成自己的字典(即key是放不同类别的图片文件夹名称,value是对应的分类number)
word2number_dict = {
"combinations": 0,
"details": 1,
"sizes": 2,
"tags": 3,
"models": 4,
"tileds": 5,
"hangs": 6
}
(3)直接执行代码 python3/python2 ./TFRecord/generate_tfrecord.py --image_dir="images_root地址" --record_path="你想要保存record地址(.record文件全路径)"即可。如下是一个实例:
python3 generate_tfrecord.py --image_dir /images/ --record_path /classify/data/train_tfrecord/train.record
TFRecord读取
上面我们介绍了如何生成TFRecord,现在我们尝试如何通过使用队列读取读取我们的TFRecord。
读取TFRecord可以通过tensorflow两个个重要的函数实现,分别是tf.train.string_input_producer和 tf.TFRecordReader的tf.parse_single_example解析器。如下图
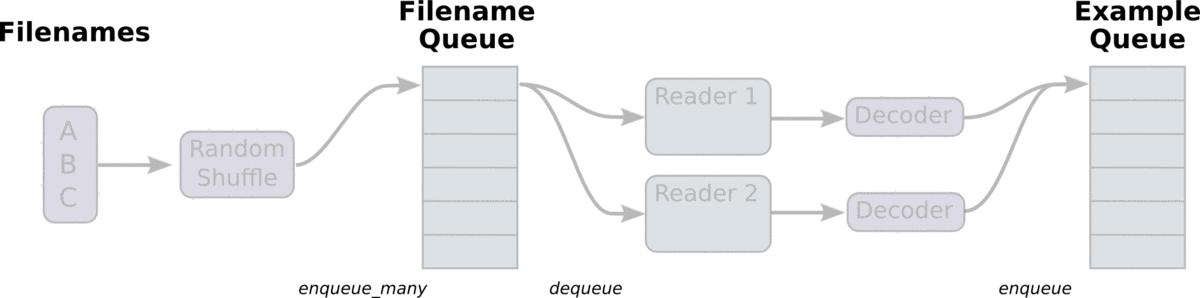
AnimatedFileQueues.gif
四、 读取TFRecord的简单实现方式
解析TFRecord有两种解析方式一种是利用tf.parse_single_example, 另一种是通过tf.contrib.slim(* 推荐使用)。
第一种方式(tf.parse_single_example)解析步骤如下:
(1).第一步,我们将train.record文件读入到队列中,如下所示:filename_queue = tf.train.string_input_producer([tfrecords_filename])
(2) 第二步,我们需要通过TFRecord将生成的队列读入
reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) #返回文件名和文件
(3)第三步, 通过解析器tf.parse_single_example将我们的example解析出来。
第二种方式(tf.contrib.slim)解析步骤如下:
(1) 第一步, 我们要设置decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers), 其中key_to_features这个字典需要和TFrecord文件中定义的字典项匹配,items_to_handlers中的关键字可以是任意值,但是它的handler的初始化参数必须要来自于keys_to_features中的关键字。
(2) 第二步, 我们要设定dataset = slim.dataset.Dataset(params), 其中params包括:
a. data_source: 为tfrecord文件地址
b. reader: 一般设置为tf.TFRecordReader阅读器
c. decoder: 为第一步设置的decoder
d. num_samples: 样本数量
e. items_to_description: 对样本及标签的描述
f. num_classes: 分类的数量
(3) 第三步, 我们设置provider = slim.dataset_data_provider.DatasetDataProvider(params), 其中params包括 :
a. dataset: 第二步骤我们生成的数据集
b. num_reader: 并行阅读器数量
c. shuffle: 是否打乱
d. num_epochs:每个数据源被读取的次数,如果设为None数据将会被无限循环的读取
e. common_queue_capacity:读取数据队列的容量,默认为256
f. scope:范围
g. common_queue_min:读取数据队列的最小容量。
(4) 第四步, 我们可以通过provider.get得到我们需要的数据了。
3. 对不同图片大小的TFRecord读取并resize成相同大小reshape_same_size函数来对图片进行resize,这样我们可以对我们的图片进行batch操作了,因为有的神经网络训练需要一个batch一个batch操作,不同大小的图片在组成一个batch的时候会报错,因此我们我通过后期处理可以更好的对图片进行batch操作。
或者直接通过resized_image = tf.squeeze(tf.image.resize_bilinear([image], size=[FLAG.resize_height, FLAG.resize_width]))即可。
五、tf.contrib.slim模块读取TFrecord文件完整代码实例
# -*- coding: utf-8 -*-
# @Time : 2018/12/1 11:06
# @Author : MaochengHu
# @Email : wojiaohumaocheng@gmail.com
# @File : read_tfrecord.py
# @Software: PyCharm
import os
import tensorflow as tf
flags = tf.app.flags
flags.DEFINE_string('tfrecord_path', '/data1/humaoc_file/classify/data/train_tfrecord/train.record', 'path to tfrecord file')
flags.DEFINE_integer('resize_height', 800, 'resize height of image')
flags.DEFINE_integer('resize_width', 800, 'resize width of image')
FLAG = flags.FLAGS
slim = tf.contrib.slim
def print_data(image, resized_image, label, height, width):
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(10):
print("______________________image({})___________________".format(i))
print_image, print_resized_image, print_label, print_height, print_width = sess.run([image, resized_image, label, height, width])
print("resized_image shape is: ", print_resized_image.shape)
print("image shape is: ", print_image.shape)
print("image label is: ", print_label)
print("image height is: ", print_height)
print("image width is: ", print_width)
coord.request_stop()
coord.join(threads)
def reshape_same_size(image, output_height, output_width):
"""Resize images by fixed sides.
Args:
image: A 3-D image `Tensor`.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
Returns:
resized_image: A 3-D tensor containing the resized image.
"""
output_height = tf.convert_to_tensor(output_height, dtype=tf.int32)
output_width = tf.convert_to_tensor(output_width, dtype=tf.int32)
image = tf.expand_dims(image, 0)
resized_image = tf.image.resize_nearest_neighbor(
image, [output_height, output_width], align_corners=False)
resized_image = tf.squeeze(resized_image)
return resized_image
def read_tfrecord(tfrecord_path, num_samples=14635, num_classes=7, resize_height=800, resize_width=800):
keys_to_features = {
'image/encoded': tf.FixedLenFeature([], default_value='', dtype=tf.string,),
'image/format': tf.FixedLenFeature([], default_value='jpeg', dtype=tf.string),
'image/class/label': tf.FixedLenFeature([], tf.int64, default_value=0),
'image/height': tf.FixedLenFeature([], tf.int64, default_value=0),
'image/width': tf.FixedLenFeature([], tf.int64, default_value=0)
}
items_to_handlers = {
'image': slim.tfexample_decoder.Image(image_key='image/encoded', format_key='image/format', channels=3),
'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[]),
'height': slim.tfexample_decoder.Tensor('image/height', shape=[]),
'width': slim.tfexample_decoder.Tensor('image/width', shape=[])
}
decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers)
labels_to_names = None
items_to_descriptions = {
'image': 'An image with shape image_shape.',
'label': 'A single integer between 0 and 9.'}
dataset = slim.dataset.Dataset(
data_sources=tfrecord_path,
reader=tf.TFRecordReader,
decoder=decoder,
num_samples=num_samples,
items_to_descriptions=None,
num_classes=num_classes,
)
provider = slim.dataset_data_provider.DatasetDataProvider(dataset=dataset,
num_readers=3,
shuffle=True,
common_queue_capacity=256,
common_queue_min=128,
seed=None)
image, label, height, width = provider.get(['image', 'label', 'height', 'width'])
resized_image = tf.squeeze(tf.image.resize_bilinear([image], size=[resize_height, resize_width]))
return resized_image, label, image, height, width
def main():
resized_image, label, image, height, width = read_tfrecord(tfrecord_path=FLAG.tfrecord_path,
resize_height=FLAG.resize_height,
resize_width=FLAG.resize_width)
#resized_image = reshape_same_size(image, FLAG.resize_height, FLAG.resize_width)
#resized_image = tf.squeeze(tf.image.resize_bilinear([image], size=[FLAG.resize_height, FLAG.resize_width]))
print_data(image, resized_image, label, height, width)
if __name__ == '__main__':
main()
代码运行方式
python3 read_tfrecord.py --tfrecord_path /data1/humaoc_file/classify/data/train_tfrecord/train.record --resize_height 800 --resize_width 800
最终我们可以看到我们读取文件的部分内容:
______________________image(0)___________________ resized_image shape is: (800, 800, 3) image shape is: (2000, 1333, 3) image label is: 5 image height is: 2000 image width is: 1333 ______________________image(1)___________________ resized_image shape is: (800, 800, 3) image shape is: (667, 1000, 3) image label is: 0 image height is: 667 image width is: 1000 ______________________image(2)___________________ resized_image shape is: (800, 800, 3) image shape is: (667, 1000, 3) image label is: 3 image height is: 667 image width is: 1000 ______________________image(3)___________________ resized_image shape is: (800, 800, 3) image shape is: (800, 800, 3) image label is: 5 image height is: 800 image width is: 800 ______________________image(4)___________________ resized_image shape is: (800, 800, 3) image shape is: (1424, 750, 3) image label is: 0 image height is: 1424 image width is: 750 ______________________image(5)___________________ resized_image shape is: (800, 800, 3) image shape is: (1196, 1000, 3) image label is: 6 image height is: 1196 image width is: 1000 ______________________image(6)___________________ resized_image shape is: (800, 800, 3) image shape is: (667, 1000, 3) image label is: 5 image height is: 667 image width is: 1000
参考:
[1] TensorFlow 自定义生成 .record 文件
[2] TensorFlow基础5:TFRecords文件的存储与读取讲解及代码实现
[3] Slim读取TFrecord文件
加载全部内容