Python读取Word内容
渴望力量的哈士奇 人气:4前言
前面几个章节我们学习了对于普通文件的操作,比如说文件的创建、复制粘贴、裁剪粘贴、文件名的重命名、删除等等。另外还学习了一些基本练习,如何查找文件、如何按照内容查找文件等等。
在本章节及后续,将开始学习一些特殊文件的自动化相关操作。如 word、excel、PPT,虽然说是特殊文件,其实也是实际工作中我们经常会用到的文件类型。
接下来我们就进入到 word 文件自动化操作的学习内容。
该章节涉及的新模块
python-docx
pdfkit
pydocx
利用 python 批量读取文件
word利器之python-docx
python-docx 是用于创建可修改 微软 Word 的一个 python 库,提供全套的 Word 操作,是最常用的 Word 工具。
使用前,先了解几个概念:
- Document:是一个 Word 文档 对象,不同于 VBA 中 Worksheet 的概念,Document 是独立的,打开不同的 Word 文档,就会有不同的 Document 对象,相互之间没有影响
- Paragraph:是段落,一个 Word 文档由多个段落组成,当在文档中输入一个回车键,就会成为新的段落,输入 shift + 回车,不会分段
- Run 表示一个节段,每个段落由多个 节段 组成,一个段落中具有相同样式的连续文本,组成一个节段,所以一个 段落 对象有个 Run 列表。
例如下图的 word 文档示意图:
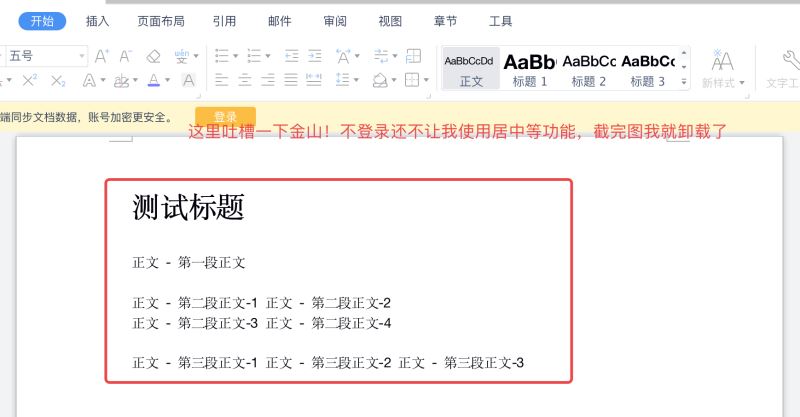
word 文档结构划分如下:

python-docx 安装
安装:
pip install python-docx 如果安装速度太慢的话,可以换一个国内的源地址(如下)
pip install -i http://pypi.tuna.tsinghua.edu.cn/simple python-docx
导入:
import docx
from docx import …
python-docx 之 Document
导入包与模块:
from docx import Document
使用方法:
Document(word文件地址)
返回值:
word文件对象
python-docx 之段落内容读取
实际上要想读取一个 word 文档,主要就是读取它的段落以及它的表格。无论是段落还是表格,它的内部都是字符串,我们的目的就是读取这些字符串的内容。
先看一下段落内容的读取方式:
来源:
document_obj.paragraphs 通过 document 对象的 paragraphs 函数返回一个段落的列表;如果 word 文件存在多个段落,就会有多个段落对象。
使用方法:
通过循环获取每个段落对象,并调用 text
演示案例脚本如下:
# coding:utf-8
import os
from docx import Document
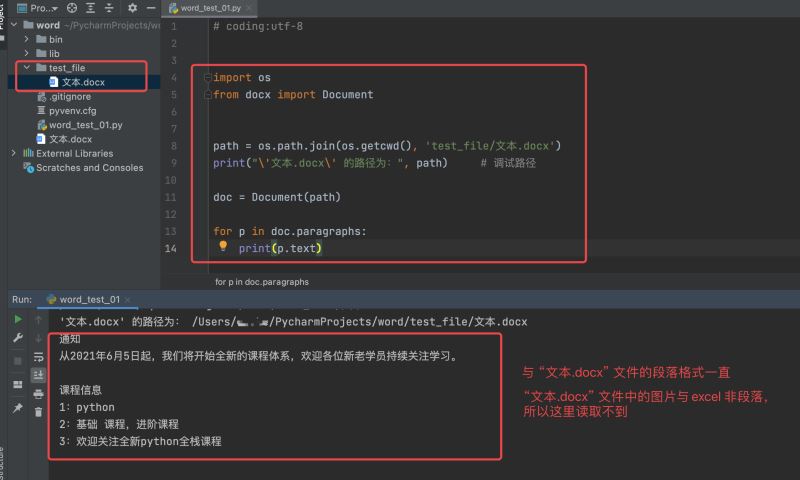
path = os.path.join(os.getcwd(), 'test_file/文本.docx')
print("\'文本.docx\' 的路径为:", path) # 调试路径
doc = Document(path)
for p in doc.paragraphs:
print(p.text)
运行结果如下:(PS:文本只是演示,本人非培训机构的!)

python-docx 之表格内容读取
接下来我们看一下如何读取 word 文件中的表格内容:
来源:
document_obj.tables 通过 document 对象的 paragraphs 函数返回一个表格的列表;里面是一个一个的表格的对象。
使用方法:
同样通过循环,获取行与列的内容
返回值:
每个表格字段(字符串)
演示案例代码如下:
# coding:utf-8
import os
from docx import Document
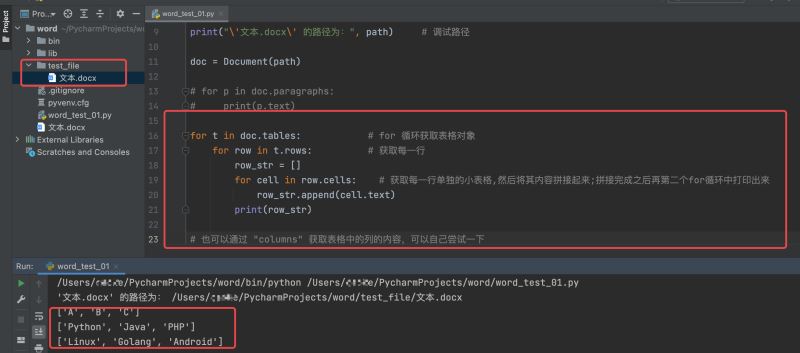
path = os.path.join(os.getcwd(), 'test_file/文本.docx')
print("\'文本.docx\' 的路径为:", path) # 调试路径
doc = Document(path)
# for p in doc.paragraphs:
# print(p.text)
for t in doc.tables: # for 循环获取表格对象
for row in t.rows: # 获取每一行
row_str = []
for cell in row.cells: # 获取每一行单独的小表格,然后将其内容拼接起来;拼接完成之后再第二个for循环中打印出来
row_str.append(cell.text)
print(row_str)
# 也可以通过 "columns" 获取表格中的列的内容,可以自己尝试一下
运行结果如下:
加载全部内容