Java HashMap
Java中文社群 人气:0前言:
本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类:
- 程序问题:比如 HashMap 在 JDK 1.7 中,并发插入时可能会发生死循环或数据覆盖的问题。
- 业务问题:比如 HashMap 无序性造成查询结果和预期结果不相符的问题。
接下来我们一个一个来看。
1.死循环问题
死循环问题发生在 JDK 1.7 版本中,形成的原因是 JDK 1.7 HashMap 使用的是头插法,那么在并发扩容时可能就会导致死循环的问题,具体产生的过程如下流程所示。
HashMap 正常情况下的扩容实现如下图所示:
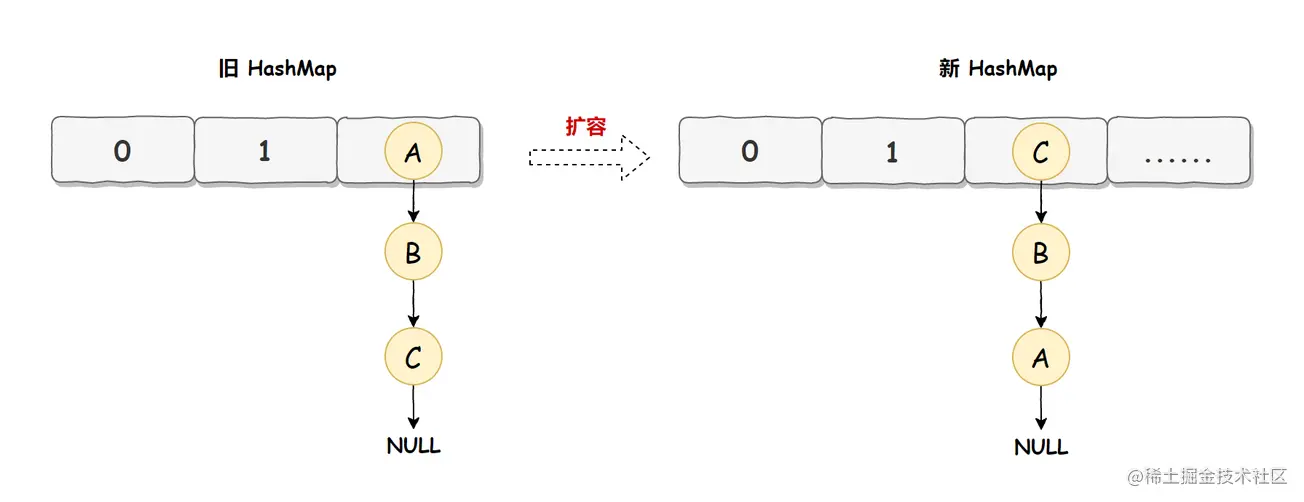
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?
1.1 死循环执行流程一
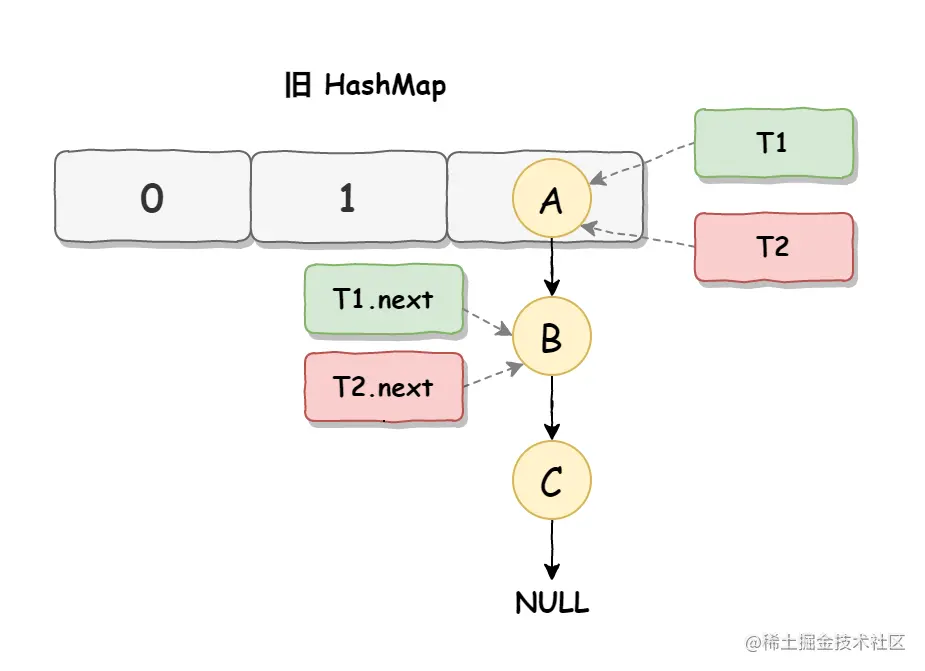
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,
如下图所示:
1.2 死循环执行流程二
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示:
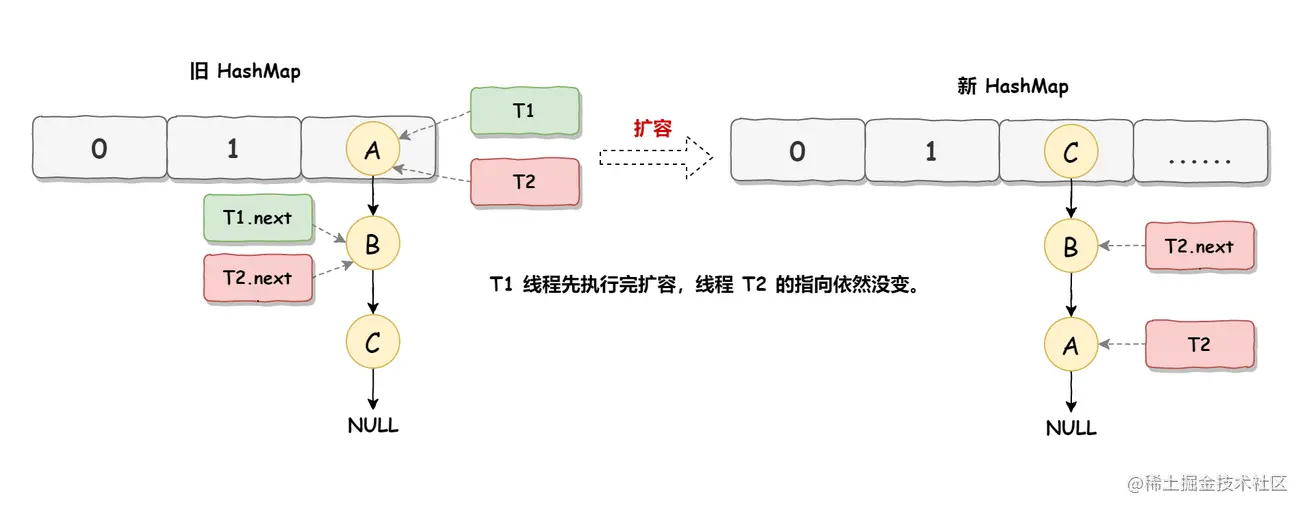
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
1.3 死循环执行流程三
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示:
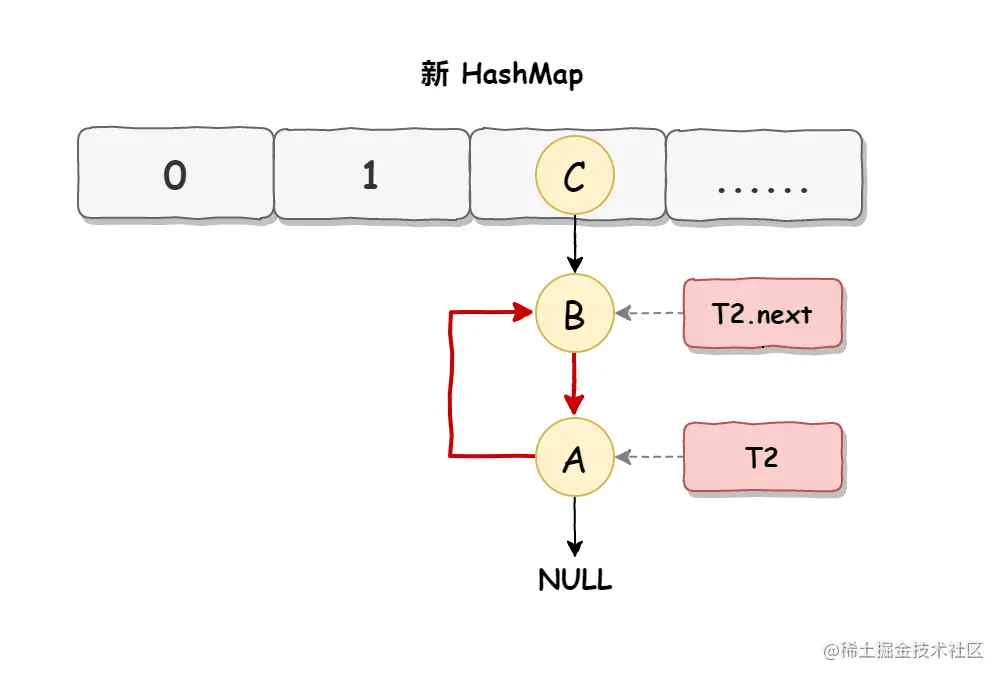
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
1.4 解决方案
使用线程安全的容器来替代 HashMap,比如 ConcurrentHashMap 或 Hashtable,因为 ConcurrentHashMap 的性能远高于 Hashtable,因此推荐使用 ConcurrentHashMap 来替代 HashMap。
2.数据覆盖问题
数据覆盖问题发生在并发添加元素的场景下,它不止出现在 JDK 1.7 版本中,其他版本中也存在此问题
数据覆盖产生的流程如下:
- 线程 T1 进行添加时,判断某个位置可以插入元素,但还没有真正的进行插入操作,自己时间片就用完了。
- 线程 T2 也执行添加操作,并且 T2 产生的哈希值和 T1 相同,也就是 T2 即将要存储的位置和 T1 相同,因为此位置尚未插入值(T1 线程执行了一半),于是 T2 就把自己的值存入到当前位置了。
- T1 恢复执行之后,因为非空判断已经执行完了,它感知不到此位置已经有值了,于是就把自己的值也插入到了此位置,那么 T2 的值就被覆盖了。
具体执行流程如下图所示。
2.1 数据覆盖执行流程一
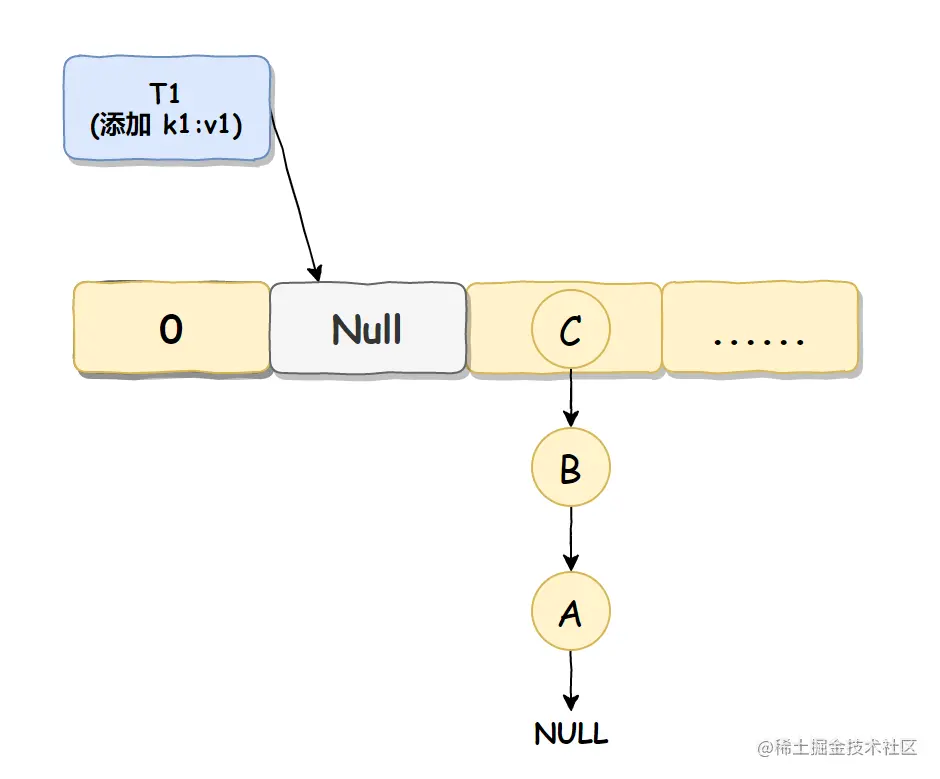
线程 T1 准备将数据 k1:v1 插入到 Null 处,但还没有真正的执行,自己的时间片就用完了,进入休眠状态了,
如下图所示:
2.2 数据覆盖执行流程二
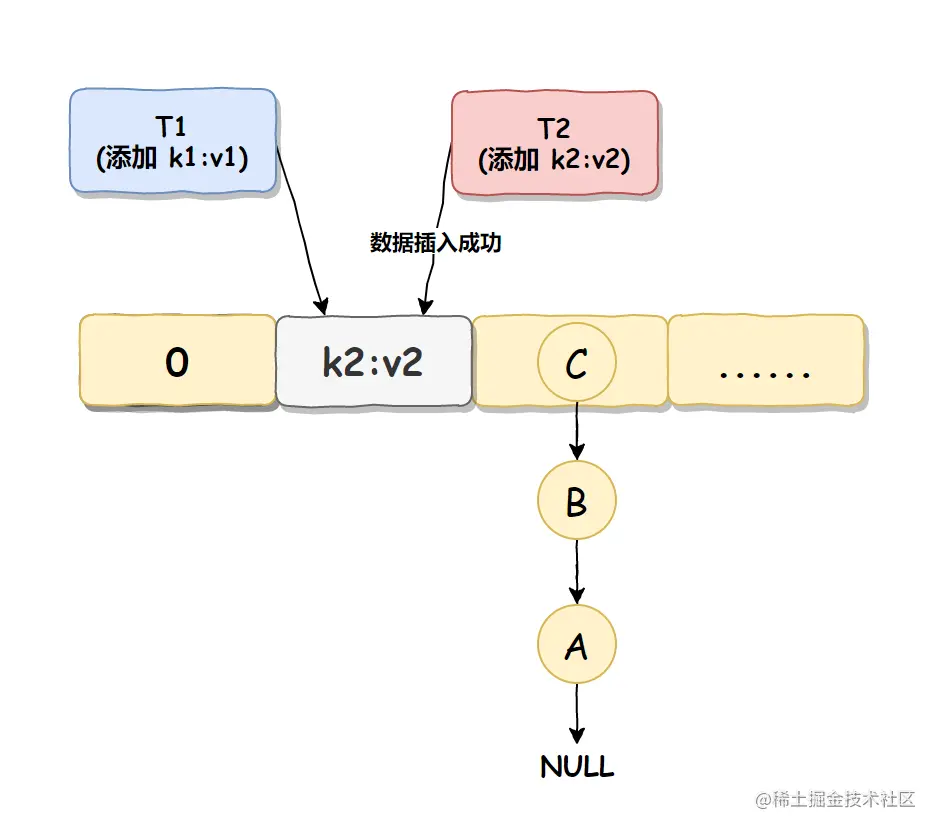
线程 T2 准备将数据 k2:v2 插入到 Null 处,因为此处现在并未有值,如果此处有值的话,它会使用链式法将数据插入到下一个没值的位置上,但判断之后发现此处并未有值,那么就直接进行数据插入了,
如下图所示:
2.3 数据覆盖执行流程三
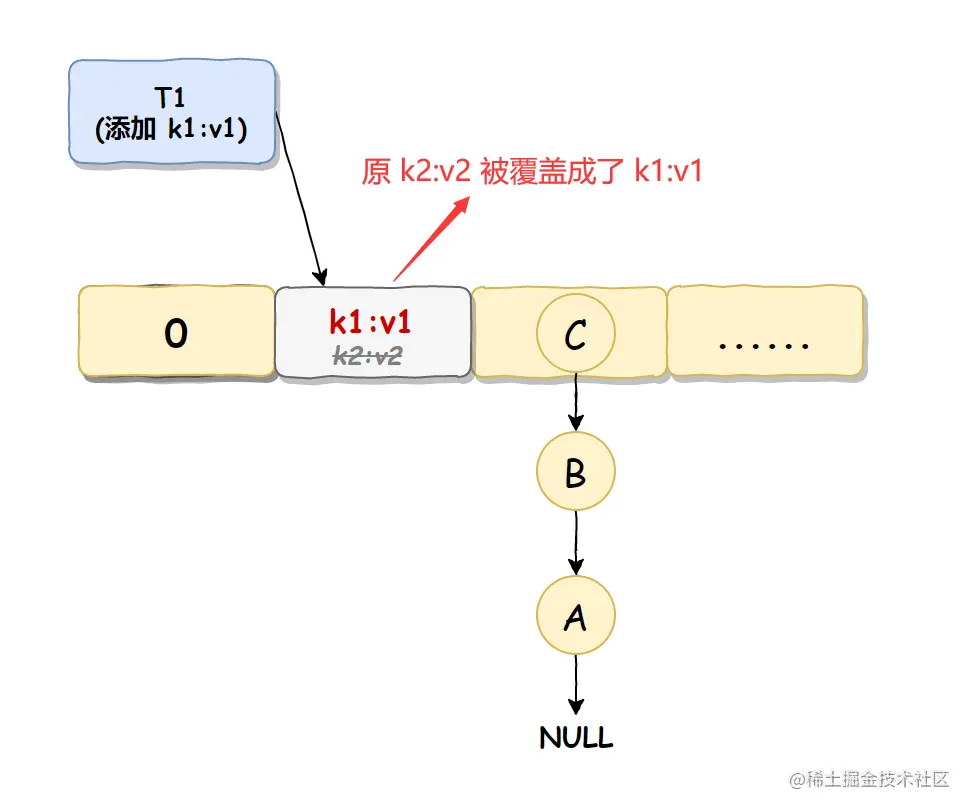
线程 T2 执行完成之后,线程 T1 恢复执行,因为线程 T1 之前已经判断过此位置没值了,所以会直接插入,此时线程 T2 插入的值就被覆盖了,
如下图所示:
2.4 解决方案
解决方案和第一个解决方案相同,使用 ConcurrentHashMap 来替代 HashMap 就可以解决此问题了。
3.无序性问题
这里的无序性问题指的是 HashMap 添加和查询的顺序不一致,导致程序执行的结果和程序员预期的结果不相符,
如以下代码所示:
HashMap<String, String> map = new HashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});我们添加的顺序:
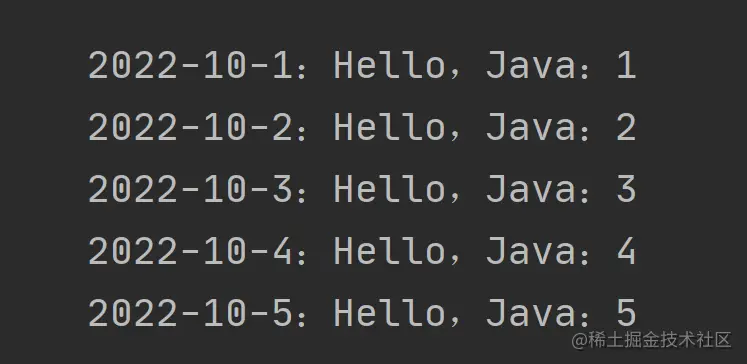
我们期望查询的顺序和添加的顺序是一致的,然而以上代码输出的结果却是:
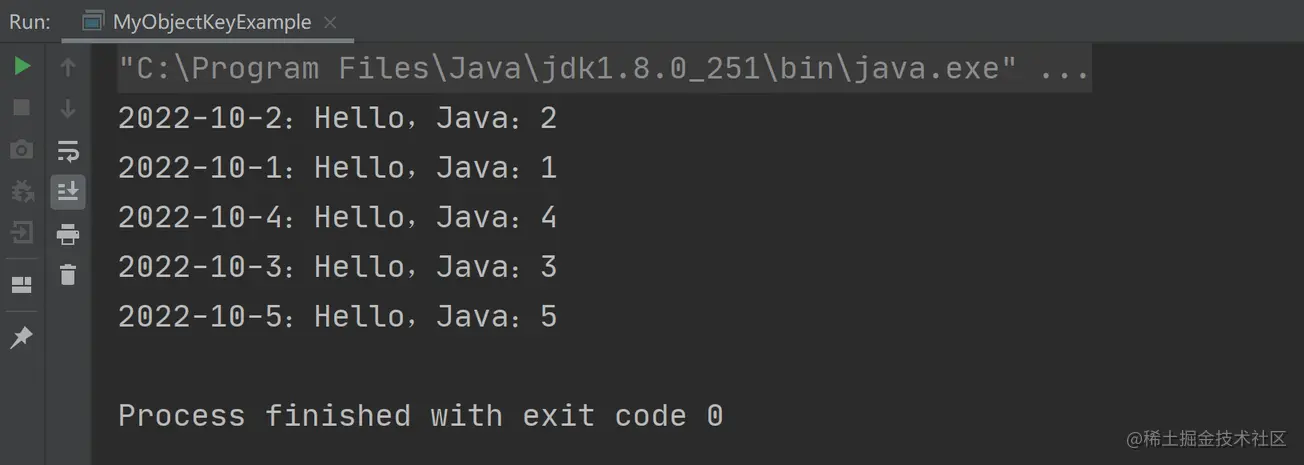
执行结果和我们预期结果不相符,这就是 HashMap 的无序性问题。我们期望输出的结果是 Hello,Java 1、2、3、4、5,而得到的顺序却是 2、1、4、3、5。
3.1 解决方案
想要解决 HashMap 无序问题,我们只需要将 HashMap 替换成 LinkedHashMap 就可以了,
如下代码所示:
LinkedHashMap<String, String> map = new LinkedHashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-10-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
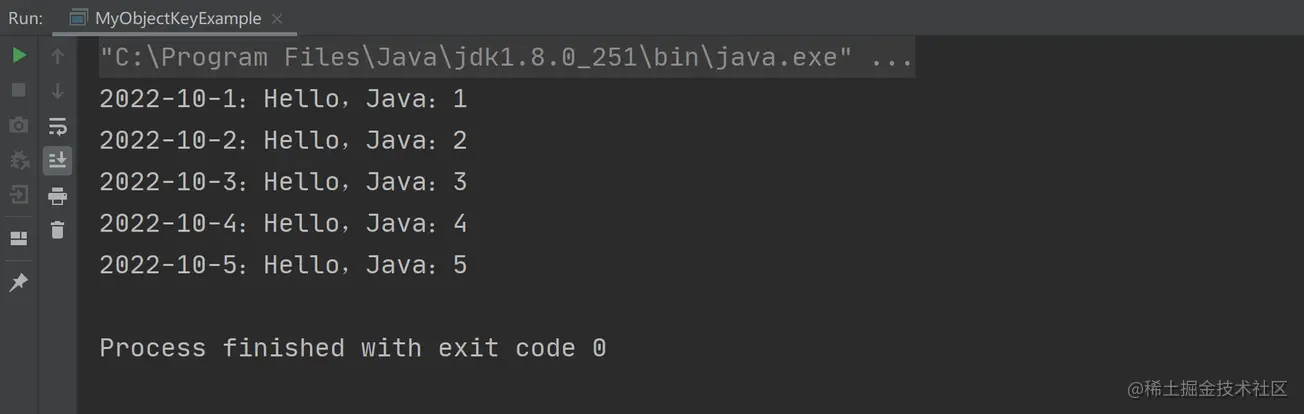
});以上程序的执行结果如下图所示:
总结
本文演示了 3 个 HashMap 的经典问题,其中死循环和数据覆盖是发生在并发添加元素时,而无序问题是添加元素的顺序和查询的顺序不一致的问题,这些问题本质来说都是对 HashMap 使用不当才会造成的问题,比如在多线程情况下就应该使用 ConcurrentHashMap,想要保证插入顺序和查询顺序一致就应该使用 LinkedHashMap,但刚开始时我们对 HashMap 不熟悉,所以才会造成这些问题,不过了解了它们之后,就能更好的使用它和更好的应对面试了。
加载全部内容