Java BM算法
Carol淋 人气:0简介
本篇文章主要分为两个大的部分,第一部分通过图解的方式讲解BM算法,第二部分则代码实现一个简易的BM算法。
基本概念
bm是一个字符串匹配算法,有实验统计,该算法是著名kmp算法性能的3~4倍,其中有两个关键概念,坏字符和好后缀。
首先举一个例子
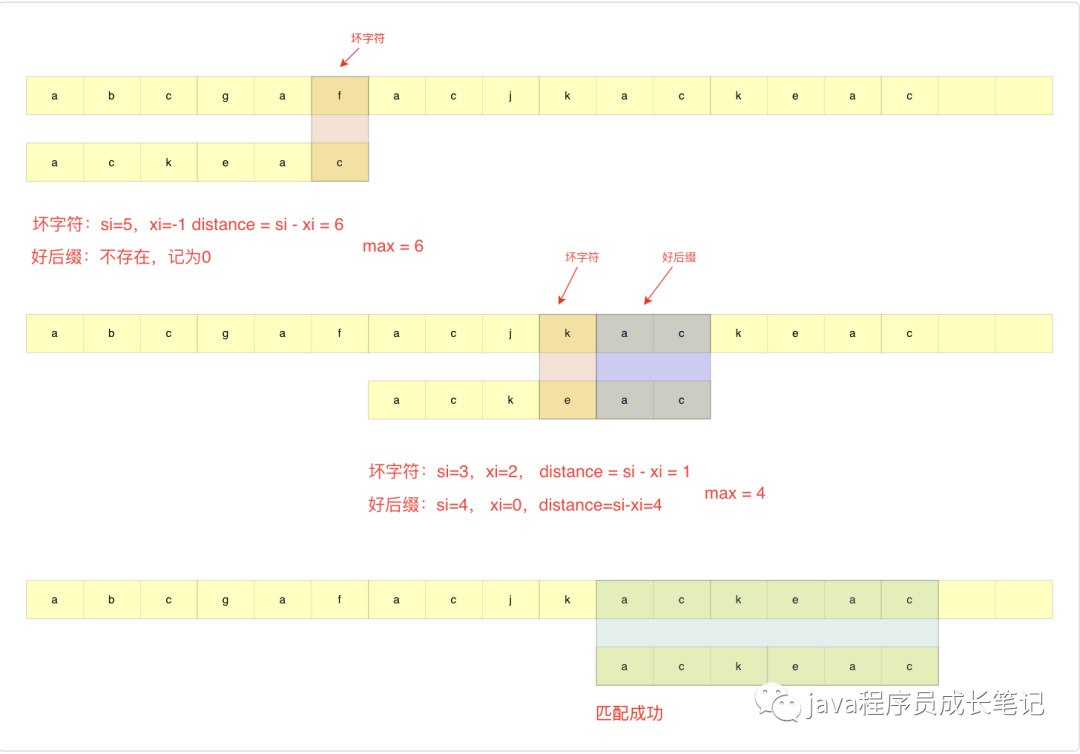
需要进行匹配的主串:a b c a g f a c j k a c k e a c
匹配的模式串:a c k e a c
坏字符
如下图所示,从模式串最后一个字符开始匹配,主串中第一个出现的不匹配的字符叫做坏字符。
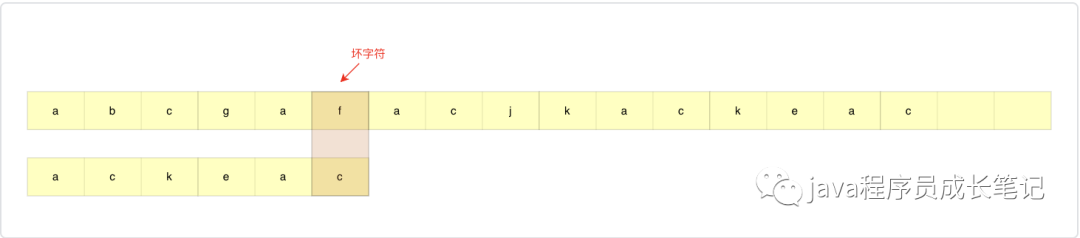
好后缀
如下图所示,从模式串最后一个字符开始匹配,匹配到的主串中的字符为好后缀。

工作过程
坏字符
依旧是这张图,接下来我们按从简单情况到复杂情况进行分析。
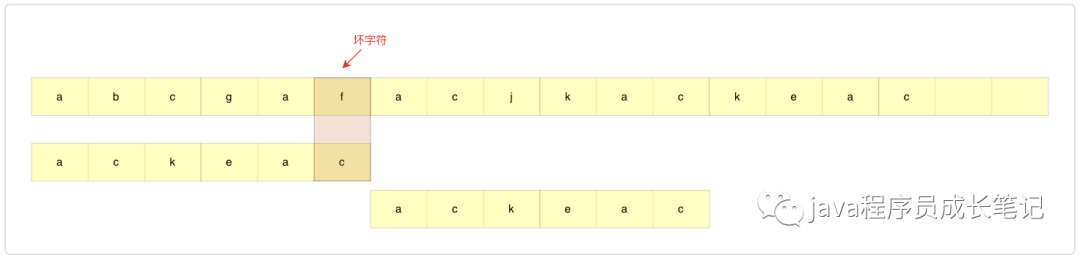
step1: 找到坏字符f,该字符对应模式串中位置si=5,如果当前没有找到坏字符,即完全匹配,直接返回。
step2: 查找字符f在模式串中出现位置,在当前模式串中,f没有出现,证明之前没有情况可以匹配,模式串直接滑到f后面位置。此次结束,否则step3。
step3: 举个例子吧,如果主串和模式串如下,f为坏字符,模式串中存在f,记位置xi=3,这时候不能直接滑到f的后面,这时候应该将模式串中的f和主串中的f对齐,如果是下面这个例子,此时直接匹配成功。如果模式串中不止存在一个f我们如何选择呢?用哪个f与模式串f对齐?答案是模式串中靠后的,如果使用靠前的,可能会多滑。
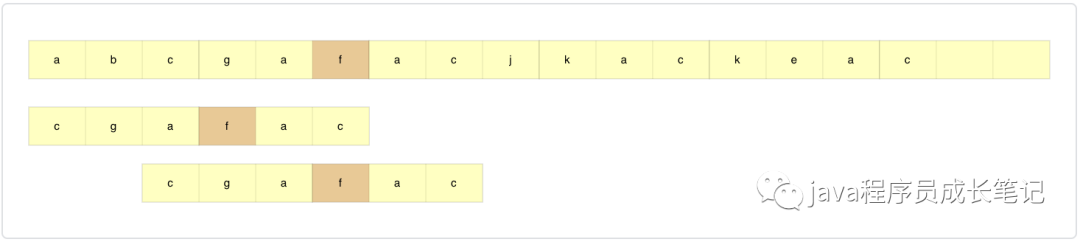
在坏字符匹配方法中,模式串往后滑动的距离应该是si-xi(如果坏字符在模式串中不存在,xi=-1)。
但是坏字符方法可能存在一个问题,看下面这个例子,坏字符a,对应匹配串中位置si=0,但是在匹配串中靠后出现位置xi=2,si-xi=-2,匹配串还往前移动,这样就会出现问题,但是当我们把下面的好后缀讲了之后,这个问题就迎刃而解了。

好后缀
首先看这张图,这时候我们暂时不管坏字符方法(坏字符为k),由简单情况到复杂情况进行分析。

step1:找到好后缀ac,起始位置si=4
step2:在模式串中查找其他位置是否存在好后缀ac(如果存在多个,为了不过度滑动,仍然选择靠后的一个),找到开头的ac,起始位置xi=0,滑动模式串使得找到的开头ac与好后缀ac匹配,滑动距离si-xi=4。此次结束,否则step3。
step3:还是先举个例子,假设模式串如下图所示,此时好后缀为ac,但是在整个模式串其他地方不存在ac,此时如果我们直接将模式串滑到ac之后,则会出现问题,实际上我们只需要滑到c的位置即可。一般化的场景我们需要怎么操作呢?对于好后缀,如果匹配串的前缀能够和好后缀的后缀匹配上,则我们直接滑到匹配位置。计算方式:好后缀后缀起始位置-0。
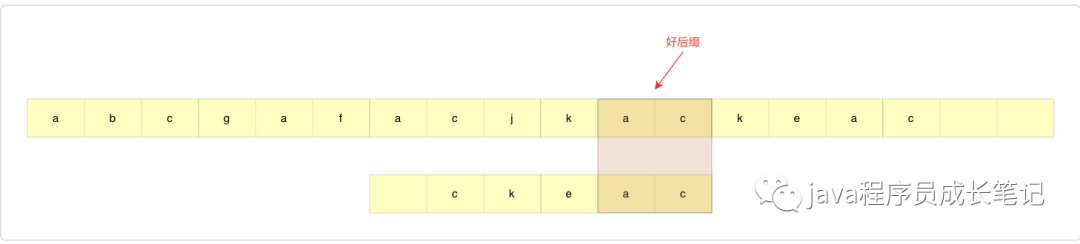
思考一下:如果匹配串中间出现与好后缀后缀匹配的情况,是否需要考虑?答案是否定的,当中间出现的时候,滑动过去肯定匹配不上。
BM算法
说完了BM算法中的两个重要概念之后,BM算法具体怎样实现的呢?
其实BM算法就是坏字符和好后缀的结合,具体就是匹配串向前滑动距离取两者计算出来的较大值。
具体步骤我们用图来演示一遍

代码实现
在上面,我们说到了,在BM算法中有两个关键概念--坏字符和好后缀,所以我们的代码实现将分为三个步骤。
- 利用坏字符算法,计算匹配串可以滑动的距离
- 利用好后缀算法,计算匹配串可以滑动的距离
- 结合坏字符算法和好后缀算法,实现BM算法,查看匹配串在主串中存在的位置
step1: 坏字符算法,经过之前的分析,我们找到坏字符之后,需要查找匹配串中是否出现过坏字符,如果出现多个,我们滑动匹配串,将靠后的坏字符与主串坏字符对齐。如果不存在,则完全匹配。如果我们每次找到坏字符都去查找一次匹配串中是否出现过,效率不高,所以我们可以用一个hash表保存匹配串中出现的字符以及最后出现的位置,提高查找效率。

我们设定的只有小写字母,可以直接利用一个26大小的数组存储,数组下标存储出现的字符(字符-‘a’),数组值存储出现的位置。
int[] modelStrIndex;
private void badCharInit(char[] modelStr) {
modelStrIndex = new int[26];
//-1表示该字符在匹配串中没有出现过
for (int i = 0 ; i < 26 ; i ++) {
modelStrIndex[i] = -1;
}
for (int i = 0 ; i < modelStr.length ; i++) {
//直接依次存入,出现相同的直接覆盖,
//保证保存的时候靠后出现的位置
modelStrIndex[modelStr[i] - 'a'] = i;
}
}查找坏字符出现位置badCharIndex,未出现,匹配成功,直接返回0。
查找匹配串中出现的坏字符位置modelStrIndex,未出现,滑动到坏字符位置之后,直接返回匹配串的长度。
返回badCharIndex - modelStrIndex。
注:坏字符是指与匹配串字符不匹配的主串字符,是看的主串,但是我们计算的位置,是匹配串中的位置。
/**
* @param mainStr 主串
* @param modelStr 模式串
* @param start 模式串在主串中的起始位置
* @return 模式串可滑动距离,如果为0则匹配上
*/
private int badChar(char[] mainStr, char[] modelStr, int start) {
//坏字符位置
int badCharIndex = -1;
char badChar = '\0';
//开始从匹配串后往前进行匹配
for (int i = modelStr.length - 1 ; i >= 0 ; i --) {
int mainStrIndex = start + i;
//第一个出现不匹配的即为坏字符
if (mainStr[mainStrIndex] != modelStr[i]) {
badCharIndex = i;
badChar = mainStr[mainStrIndex];
break;
}
}
if (-1 == badCharIndex) {
//不存在坏字符,需匹配成功,要移动距离为0
return 0;
}
//查看坏字符在匹配串中出现的位置
if (modelStrIndex[badChar - 'a'] > -1) {
//出现过
return badCharIndex - modelStrIndex[badChar - 'a'];
}
return modelStr.length;
}step2:好后缀算法,经过之前的分析,我们在实现好后缀算法的时候,有一个后缀前缀匹配的过程,这里我们仍然可以事先进行处理。将匹配串一分为二,分别匹配前缀和后缀字串。ps:开始我的处理是两个数组,将前缀后缀存下来,需要的时候进行匹配,但是在写文章的时候,我突然回过神来,我已经处理了一遍了,为什么不直接标记是否匹配呢?
初始化匹配串前缀后缀是否匹配数组,标志当前长度的前缀后缀是否匹配。
//对应位置的前缀后缀是否匹配
boolean[] isMatch;
public void goodSuffixInit(char[] modelStr) {
isMatch = new boolean[modelStr.length / 2];
StringBuilder prefixStr = new StringBuilder();
List<Character> suffixChar = new ArrayList<>(modelStr.length / 2);
for (int i = 0 ; i < modelStr.length / 2 ; i ++) {
prefixStr.append(modelStr[i]);
suffixChar.add(0, modelStr[modelStr.length - i - 1]);
isMatch[i] = this.madeSuffix(suffixChar).equals(prefixStr.toString());
}
}
/**
* 组装后缀数据
* @param characters
* @return
*/
private String madeSuffix(List<Character> characters) {
StringBuilder sb = new StringBuilder();
for (Character ch : characters) {
sb.append(ch);
}
return sb.toString();
}step3: 结合坏字符和好后缀算法实现BM算法,起始就是每一次匹配,同时调用坏字符和好后缀算法,如果返回移动距离为0,表示已经匹配成功,直接返回当前匹配的起始距离。其余情况下,滑动坏字符和好后缀算法返回的较大值。如果主串匹配完还没有匹配成功,则返回-1。
注:加了一些日志打印匹配过程
public int bmStrMatch(char[] mainStr, char[] modelStr) {
//初始化坏字符和好后缀需要的数据
this.badCharInit(modelStr);
this.goodSuffixInit(modelStr);
int start = 0;
while (start + modelStr.length <= mainStr.length) {
//坏字符计算的需要滑动的距离
int badDistance = this.badChar(mainStr, modelStr, start);
//好后缀计算的需要滑动的距离
int goodSuffixDistance = this.goodSuffix(mainStr, modelStr, start);
System.out.println("badDistance = " +badDistance + ", goodSuffixDistance = " + goodSuffixDistance);
//任意一个匹配成功即成功(可以计算了坏字符和好后缀之后分别判断一下)
//减少一次操作
if (0 == badDistance || 0 == goodSuffixDistance) {
System.out.println("匹配到的位置 :" + start);
return start;
}
start += Math.max(badDistance, goodSuffixDistance);
System.out.println("滑动至:" + start);
}
return -1;
}最后
使用前面使用的例子,我们来实际调用一下
public static void main(String[] args) {
BoyerMoore moore = new BoyerMoore();
char[] mainStr = new char[]{'a','b', 'c', 'a', 'g', 'f', 'a', 'c', 'j', 'k', 'a', 'c', 'k', 'e', 'a', 'c'};
char[] modelStr = new char[]{'a', 'c', 'k', 'e', 'a', 'c'};
System.out.println(moore.bmStrMatch(mainStr, modelStr));
}调用结果

加载全部内容