Python批量抠图
Ckend 人气:0前言


抠图前 vs Python自动抠图后
在日常的工作和生活中,我们经常会遇到需要抠图的场景,即便是只有一张图片需要抠,也会抠得我们不耐烦,倘若遇到许多张图片需要抠,这时候你的表情应该会很有趣。
Python能够成为这样的一种工具:在只有一张图片,需要细致地抠出人物的情况下,能帮你减少抠图步骤;在有多张图片需要抠的情况下,能直接帮你输出这些人物的基本轮廓,虽然不够细致,但也够用了。
DeepLabv3+ 是谷歌 DeepLab语义分割系列网络的最新作 ,这个模型可以用于人像分割,支持任意大小的图片输入。如果我们自己来实现这个模型,那可能会非常麻烦,但是幸运的是,百度的paddle hub已经帮我们实现了,我们仅需要加载模型对图像进行分割即可。
1.准备
为了实现这个实验,Python是必不可少的,如果你还没有安装Python,建议阅读我们的这篇文章哦:超详细Python安装指南。
然后,我们需要安装百度的paddlepaddle, 进入他们的官方网站就有详细的指引
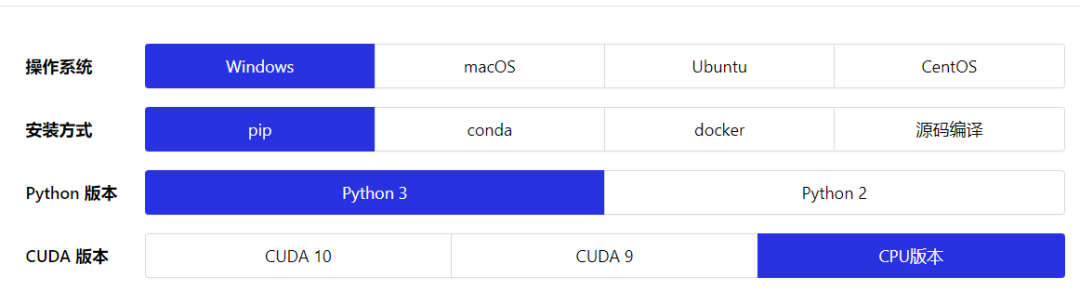
根据你自己的情况选择这些选项,最后一个CUDA版本,由于本实验不需要训练数据,也不需要太大的计算量,所以直接选择CPU版本即可。选择完毕,下方会出现安装指引,不得不说,Paddlepaddle这些方面做的还是比较贴心的(就是名字起的不好)。
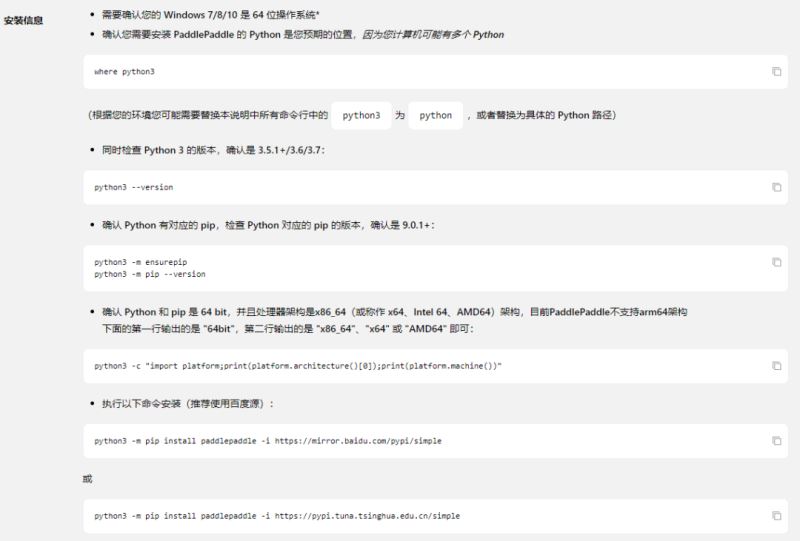
要注意,如果你的Python3环境变量里的程序名称是Python,记得将python3 xxx 语句改为Python xxx 如下进行安装:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
2.编写代码
整个步骤分为三步:
1.加载模型
2.指定待抠图的图片目录
3.抠图
import os
import sys
import paddlehub as hub
# 1.加载模型
humanseg = hub.Module(name="deeplabv3p_xception65_humanseg")
# 2.指定待抠图图片目录
path = './source/'
files = []
dirs = os.listdir(path)
for diretion in dirs:
files.append(path + diretion)
# 3.抠图
results = humanseg.segmentation(data={"image": files})
for result in results:
print(result['origin'])
print(result['processed'])
不多不少一共20行代码。抠图完毕后会在本地文件夹下产生一个叫做humanseg_output的文件夹。这里面存放的是已经抠图成功的图片。




3.结果分析
不得不承认,谷歌的算法就素厉害啊。只要背景好一点,抠出来的细节都和手动抠的细节不相上下,甚至优于人工手段。
不过在背景和人的颜色不相上下的情况下,会产生一些问题,比如下面这个结果:


背后那个大叔完全被忽略掉了(求大叔的内心阴影面积)。尽管如此,这个模型是我迄今为止见过的最强抠图模型,没有之一。
加载全部内容