Python Word转PDF
渴望力量的哈士奇 人气:0该章节我们将要学习如何将 word 文件转为 PDF文件,其实网上有很多种生成 PDF 的教程,不过绝大多数都是以 windows 为主的,并且兼容有很多的问题。windows、mac、linux 同时兼容的情况比较少,所以今天的章节我们就来学习一下如何在 windows、mac、linux 三种系统中都可以生成 PDF 的解决方案。
pdf 工具包 - pdfkit
pdfkit 包的安装:
pip install pdfkit
依赖工具:
下载符合与自己当前系统的安装包安装完成之后就可以达到兼容的效果了。
html 转 pdf
html 转 pdf 方法:
pdfkit.from_file(html文件, 保存路径) 利用 pdfkit.from_file() 函数传入 "html" 文件与 pdf 的保存路径
代码示例如下:
# coding:utf-8
import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf"
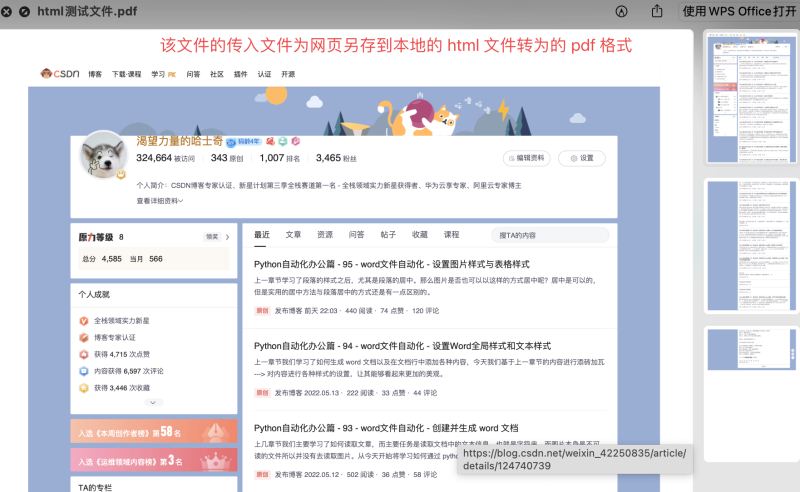
pdfkit.from_file('html测试文件.html', 'html测试文件.pdf')
运行结果如下:
网址 转 pdf
网址 转 pdf 方法:
pdfkit.from_url(网址, 保存路径) 利用 pdfkit.from_url() 函数传入 "网址" 文件与 pdf 的保存路径
“html” 文件与网址的区别在于实际上html文件有可能是我们本地开发生成的,也有可能是通过 “网页另存为” 的方式存储在本地的。所以 网址 与 html文件 还是有一点点区别的,但是它们的本质其实是一样的。
代码示例如下:
# coding:utf-8
import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf"
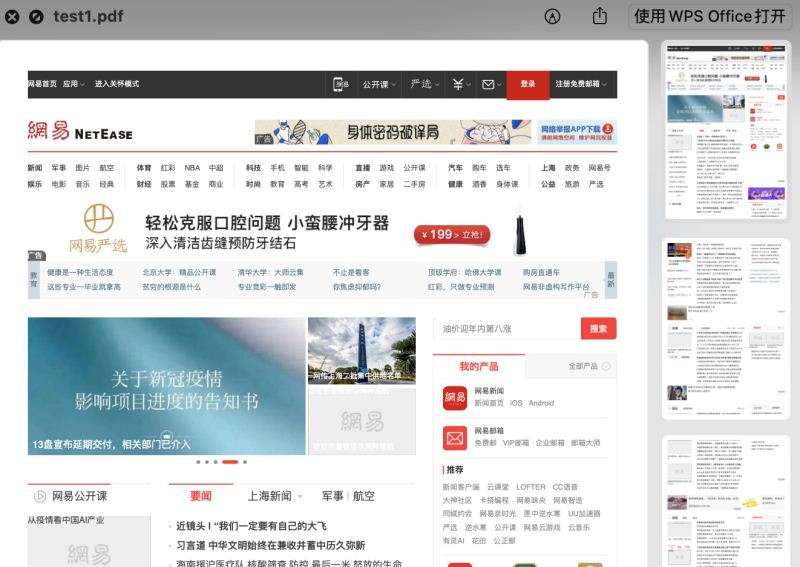
pdfkit.from_url('https://www.163.com', 'test1.pdf')
运行结果如下:
字符串生成pdf
网址 转 pdf 方法:
pdfkit.from_string(基于html的字符串, 保存路径) 利用 pdfkit.from_string() 函数传入 "网址" 文件与 pdf 的保存路径
基于html的字符串 其实就是前端的一种超文本文件格式,以这种前端规范生成的字符串其实就是 html 的字符串了
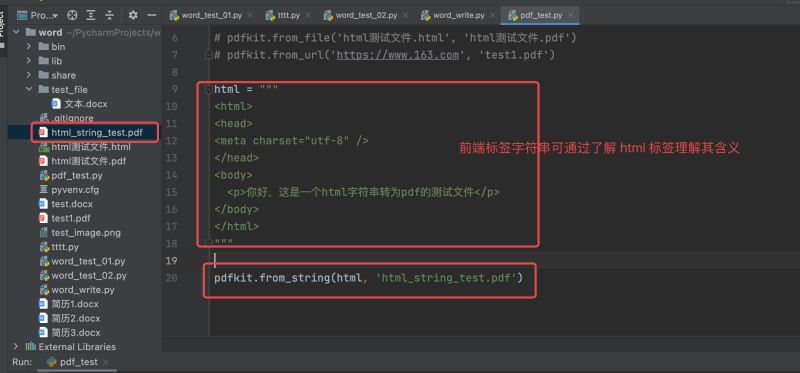
# coding:utf-8 import pdfkit # 需安装 pdfkit 第三方包 "pip install pdfkit" 以及第三方依赖 "wkhtmltopdf" html = """ <html> <head> <meta charset="utf-8" /> </head> <body> <p>你好,这是一个html字符串转为pdf的测试文件</p> </body> </html> """ pdfkit.from_string(html, 'html_string_test.pdf')
运行结果如下:

结合 pydocx 将 word 转 html 再转 pdf
首先需要安装 pydocx 依赖包 —> pip install pydocx
导入 PyDocX 函数 —> from pydocx import PyDocX
利用 PyDocX 将 word 文件转换为 html 格式(会生成一个 html 的字符串对象)
将 生成的 html 字符串 写入到一个 html 文件中
然后利用 pdfkit 包的 pdfkit.from_file() 函数将其转为 pdf 文件
代码示例如下:
# coding:utf-8
import pdfkit # pip install pdfkit
from pydocx import PyDocX # pip install pydocx
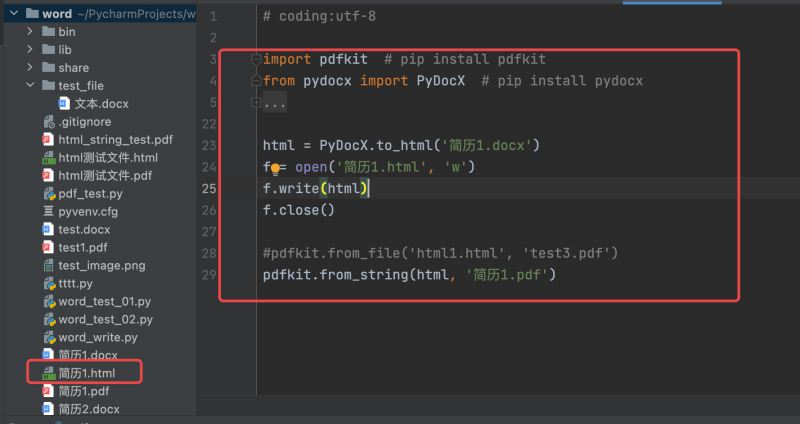
html = PyDocX.to_html('简历1.docx')
f = open('简历1.html', 'w')
f.write(html)
f.close()
#pdfkit.from_file('html1.html', 'test3.pdf')
pdfkit.from_string(html, '简历1.pdf')
运行结果如下:
加载全部内容