python实现kmeans聚类
嘟嘟肚腩仔 人气:0一、先上手撸代码!
1、首先是导入所需要的库和数据
import pandas as pd
import numpy as np
import random
import math
import matplotlib.pyplot as plt
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('13信科学生成绩.xlsx')
data = np.array(df)
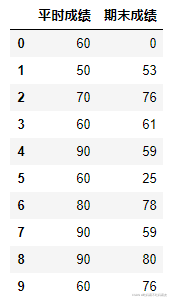
df.head(10)先给大伙们看看数据集长啥样:
用matplotlib简单的可视化一下初始数据:
# 输入数据
x = data.T[0]
y = data.T[1]
plt.scatter(x, y, s=50, c='r') # 画散点图
plt.xlabel('平时') # 横坐标轴标题
plt.ylabel('期末') # 纵坐标轴标题
plt.show()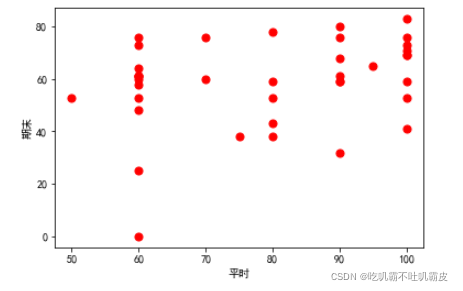
2、接下来就是kmeans的核心算法了
k=3
i = 1
min1 = data.min(axis = 0)
max1 = data.max(axis = 0)
#在数据最大最小值中随机生成k个初始聚类中心,保存为t
centre = np.empty((k,2))
for i in range(k):
centre[i][0] = random.randint(min1[0],max1[0])#平时成绩
centre[i][1] = random.randint(min1[1],max1[1])#期末成绩
while i<500:
#计算欧氏距离
def euclidean_distance(List,t):
return math.sqrt(((List[0] - t[0])**2 + (List[1] - t[1])**2))
#每个点到每个中心点的距离矩阵
dis = np.empty((len(data),k))
for i in range(len(data)):
for j in range(k):
dis[i][j] = euclidean_distance(data[i],centre[j])
#初始化分类矩阵
classify = []
for i in range(k):
classify.append([])
#比较距离并分类
for i in range(len(data)):
List = dis[i].tolist()
index = List.index(dis[i].min())
classify[index].append(i)
#构造新的中心点
new_centre = np.empty((k,2))
for i in range(len(classify)):
new_centre[i][0] = np.sum(data[classify[i]][0])/len(classify[i])
new_centre[i][1] = np.sum(data[classify[i]][1])/len(classify[i])
#比较新的中心点和旧的中心点是否一样
if (new_centre == centre).all():
break
else:
centre = new_centre
i = i + 1
# print('迭代次数为:',i)
print('聚类中心为:',new_centre)
print('分类情况为:',classify)注意!!!这里的k是指分成k类,读者可以自行选取不同的k值做实验

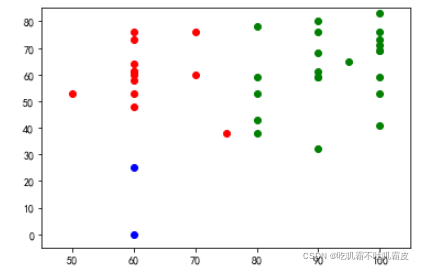
3、可视化部分(将不用类用不同颜色区分开来~~)
mark = ['or', 'ob', 'og', 'ok','sb', 'db', '<b', 'pb'] #红、蓝、绿、黑四种颜色的圆点
#mark=['sb', 'db', '<b', 'pb']
plt.figure(3)#创建图表1
for i in range(0,k):
x=[]
y=[]
for j in range(len(classify[i])):
x.append(data[classify[i][j]][0])
y.append(data[classify[i][j]][1])
plt.xlim(xmax=105,xmin=45)
plt.ylim(ymax=85,ymin=-5)
plt.plot(x,y,mark[i])
#plt.show()一起来康康可视化结果8!!
二、接下来是调库代码!(sklearn)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
df = pd.read_excel('13信科学生成绩.xlsx')
data = np.array(df)
y_pred=KMeans(n_clusters=3,random_state=9).fit_predict(data)
plt.scatter(data[:,0],data[:,1],c=y_pred)
plt.show()
print(metrics.calinski_harabasz_score(data,y_pred))可视化结果和手撸的结果略有差别,有可能是数据集的问题,也有可能是k值选取的问题,各位亲们不需要担心!!!
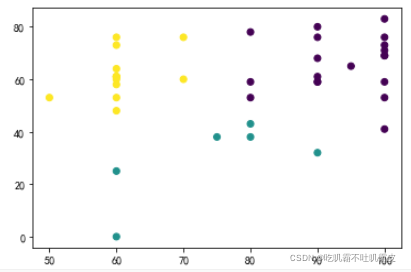
附:对k-means算法的认识
1.优点
(1)算法快速、简单。
(2)对大数据集有较高的效率并且是可伸缩性的。
(3)时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) ,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
2.缺点
(1)聚类是一种无监督的学习方法,在 K-means 算法中 K 是事先给定的,K均值算法需要用户指定创建的簇数k,但这个 K 值的选定是非常难以估计的。
(2)在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。
(3)从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围,而这导致K均值算法在大数据集上收敛较慢。
总结
加载全部内容