对图像补全并分割成多块补丁
WUNNAN 人气:0题目
编写一个程序,按照输入的宽高,将测试图像分割成多个补丁块,超出图像边界的部分用黑色像素补齐
思路
按照输入的宽高,先判断原始图像与其取模是否为零,判断需不需要进行图像填充
如果需要进行图像填充,先计算出新图像的宽和高((整除后+1)* 指定宽高),然后新建一张全黑图像,将原图像默认为左上角位置粘贴进去
最后进行图像裁剪,使用两层for循环,步长设定为补丁的宽高,使用crop函数,指定补丁图片的左、上、右、下坐标
代码
import numpy as np
from PIL import Image
# 判断是否需要进行图像填充
def judge(img, wi, he):
width, height = img.size
# 默认新图像尺寸初始化为原图像
new_width, new_height = img.size
if width % wi != 0:
new_width = (width//wi + 1) * wi
if height % he != 0:
new_height = (height//he + 1) * he
# 新建一张新尺寸的全黑图像
new_image = Image.new('RGB', (new_width, new_height), (0, 0, 0))
# 将原图像粘贴在new_image上,默认为左上角坐标对应
new_image.paste(img, box=None, mask=None)
new_image.show()
return new_image
# 按照指定尺寸进行图片裁剪
def crop_image(image, patch_w, patch_h):
width, height = image.size
# 补丁计数
cnt = 0
for w in range(0, width, patch_w):
for h in range(0, height, patch_h):
cnt += 1
# 指定原图片的左、上、右、下
img = image.crop((w, h, w+patch_w, h+patch_h))
img.save("dog-%d.jpg" % cnt)
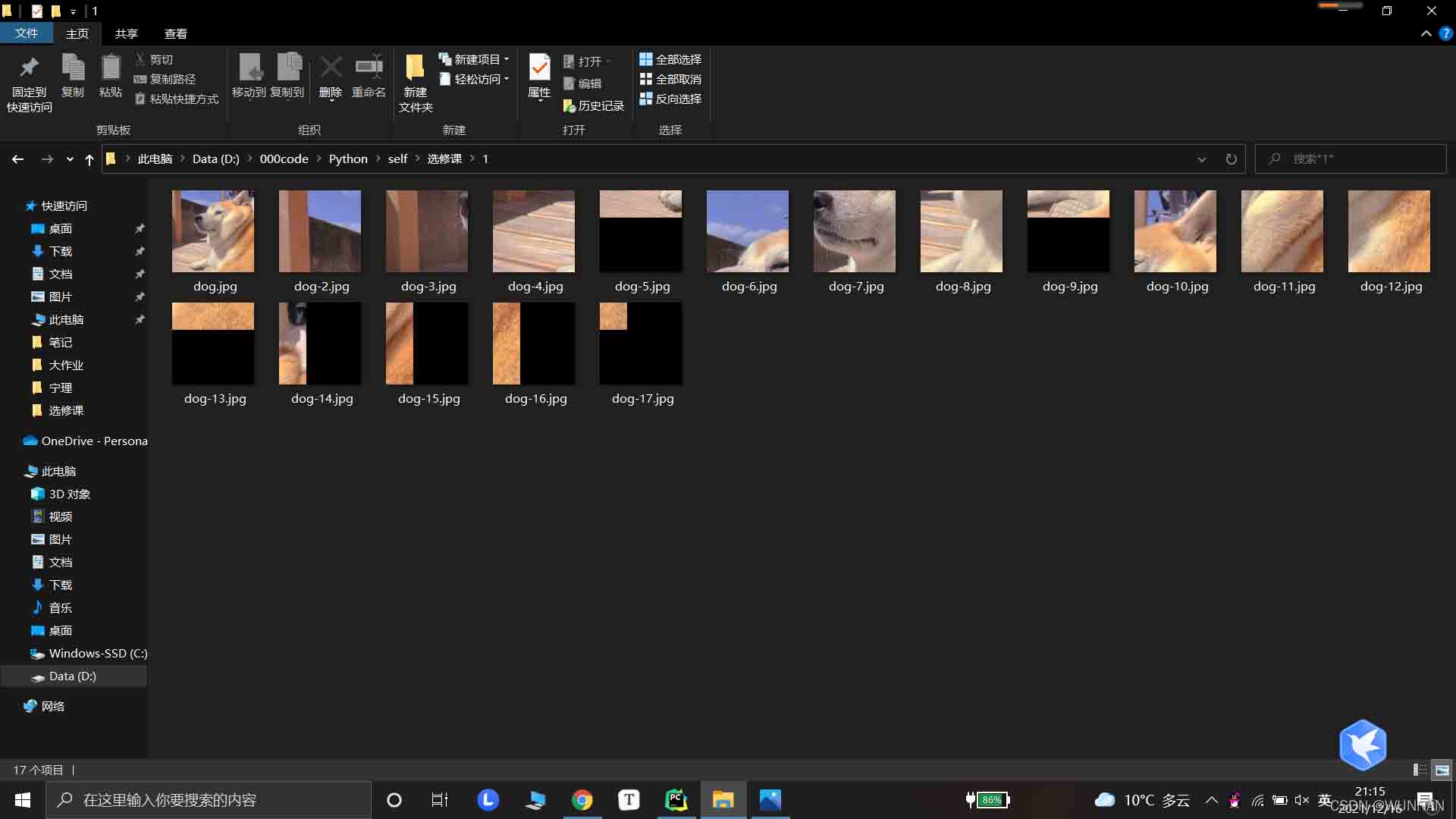
print("图片补丁裁剪结束,共有{}张补丁".format(cnt))
def main():
image_path = "dog.jpg"
img = Image.open(image_path)
# 查看图像形状
print("原始图像形状{}".format(np.array(img).shape))
# 输入指定的补丁宽高
print("输入补丁宽高:")
wi, he = map(int, input().split(" "))
# 进行图像填充
new_image = judge(img, wi, he)
# 图片补丁裁剪
crop_image(new_image, wi, he)
if __name__ == '__main__':
main()
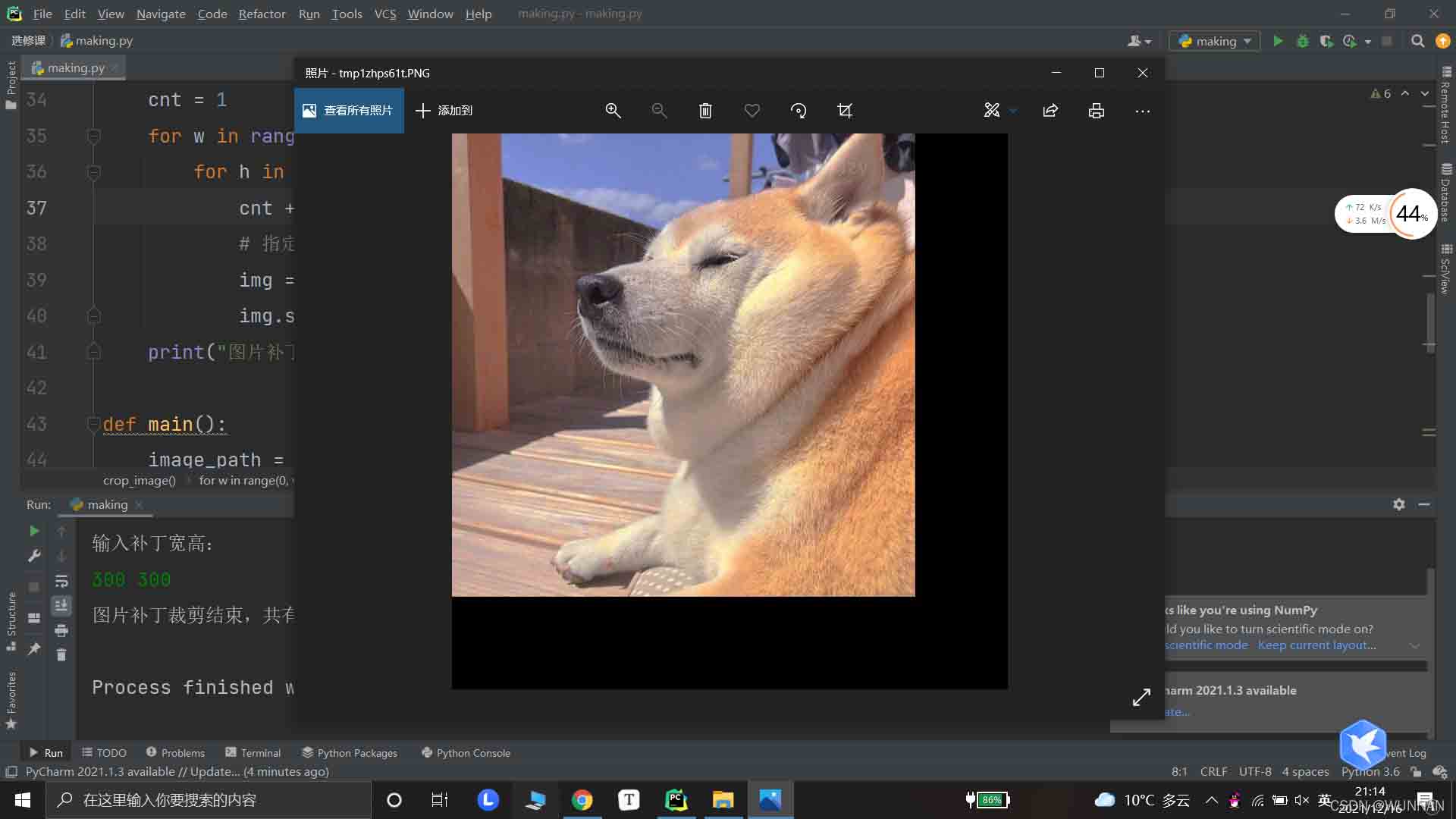
效果展示
原图像使用了黑色像素填充
图像裁剪,分割成小补丁
图像分割方法总结
图像分割是一种常用的图像处理方法,可分为传统方法和深度学习的方法。深度学习的方法比如:mask rcnn这类实例分割模型,效果比传统的图像分割方法要好的多,所以目前图像分割领域都是用深度学习来做的。但是深度学习也有它的缺点,模型大、推理速度慢、可解释性差、训练数据要求高等。本文在这里仅讨论传统的图像分割算法,可供学习和使用。
1、阈值分割
最简单的图像分割算法,只直接按照像素值进行分割,虽然简单,但是在一些像素差别较大的场景中表现不错,是一种简单而且稳定的算法。
def thresholdSegment(filename): gray = cv2.imread(filename, cv2.IMREAD_GRAYSCALE) ret1, th1 = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY) th2 = cv2.adaptiveThreshold( gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) th3 = cv2.adaptiveThreshold( gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2) ret2, th4 = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) images = [th1, th2, th4, th3] imgaesTitle = ['THRESH_BINARY', 'THRESH_MEAN', 'THRESH_OTSU', 'THRESH_GAUSSIAN'] plt.figure() for i in range(4): plt.subplot(2, 2, i+1) plt.imshow(images[i], 'gray') plt.title(imgaesTitle[i]) cv2.imwrite(imgaesTitle[i]+'.jpg', images[i]) plt.show() cv2.waitKey(0) return images
2、边界分割(边缘检测)
def edgeSegmentation(filename):
# 读取图片
img = cv2.imread(filename)
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 高斯模糊处理:去噪(效果最好)
blur = cv2.GaussianBlur(gray, (9, 9), 0)
# Sobel计算XY方向梯度
gradX = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=1, dy=0)
gradY = cv2.Sobel(gray, ddepth=cv2.CV_32F, dx=0, dy=1)
# 计算梯度差
gradient = cv2.subtract(gradX, gradY)
# 绝对值
gradient = cv2.convertScaleAbs(gradient)
# 高斯模糊处理:去噪(效果最好)
blured = cv2.GaussianBlur(gradient, (9, 9), 0)
# 二值化
_, dst = cv2.threshold(blured, 90, 255, cv2.THRESH_BINARY)
# 滑动窗口
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (107, 76))
# 形态学处理:形态闭处理(腐蚀)
closed = cv2.morphologyEx(dst, cv2.MORPH_CLOSE, kernel)
# 腐蚀与膨胀迭代
closed = cv2.erode(closed, None, iterations=4)
closed = cv2.dilate(closed, None, iterations=4)
# 获取轮廓
_, cnts, _ = cv2.findContours(
closed.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
rect = cv2.minAreaRect(c)
box = np.int0(cv2.boxPoints(rect))
draw_img = cv2.drawContours(img.copy(), [box], -1, (0, 0, 255), 3)
#cv2.imshow("Box", draw_img)
#cv2.imwrite('./test/monkey.png', draw_img)
images = [blured, dst, closed, draw_img]
imgaesTitle = ['blured', 'dst', 'closed', 'draw_img']
plt.figure()
for i in range(4):
plt.subplot(2, 2, i+1)
plt.imshow(images[i], 'gray')
plt.title(imgaesTitle[i])
#cv2.imwrite(imgaesTitle[i]+'.jpg', images[i])
plt.show()
cv2.waitKey(0)3、区域分割(区域生成)
def regionSegmentation(filename):
# 读取图片
img = cv2.imread(filename)
# 图片宽度
img_x = img.shape[1]
# 图片高度
img_y = img.shape[0]
# 分割的矩形区域
rect = (0, 0, img_x-1, img_y-1)
# 背景模式,必须为1行,13x5列
bgModel = np.zeros((1, 65), np.float64)
# 前景模式,必须为1行,13x5列
fgModel = np.zeros((1, 65), np.float64)
# 图像掩模,取值有0,1,2,3
mask = np.zeros(img.shape[:2], np.uint8)
# grabCut处理,GC_INIT_WITH_RECT模式
cv2.grabCut(img, mask, rect, bgModel, fgModel, 4, cv2.GC_INIT_WITH_RECT)
# grabCut处理,GC_INIT_WITH_MASK模式
#cv2.grabCut(img, mask, rect, bgModel, fgModel, 4, cv2.GC_INIT_WITH_MASK)
# 将背景0,2设成0,其余设成1
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
# 重新计算图像着色,对应元素相乘
img = img*mask2[:, :, np.newaxis]
cv2.imshow("Result", img)
cv2.waitKey(0)4、SVM分割(支持向量机)
def svmSegment(pic):
img = Image.open(pic)
img.show() # 显示原始图像
img_arr = np.asarray(img, np.float64)
#选取图像上的关键点RGB值(10个)
lake_RGB = np.array(
[[147, 168, 125], [151, 173, 124], [143, 159, 112], [150, 168, 126], [146, 165, 120],
[145, 161, 116], [150, 171, 130], [146, 112, 137], [149, 169, 120], [144, 160, 111]])
# 选取待分割目标上的关键点RGB值(10个)
duck_RGB = np.array(
[[81, 76, 82], [212, 202, 193], [177, 159, 157], [129, 112, 105], [167, 147, 136],
[237, 207, 145], [226, 207, 192], [95, 81, 68], [198, 216, 218], [197, 180, 128]] )
RGB_arr = np.concatenate((lake_RGB, duck_RGB), axis=0) # 按列拼接
# lake 用 0标记,duck用1标记
label = np.append(np.zeros(lake_RGB.shape[0]), np.ones(duck_RGB.shape[0]))
# 原本 img_arr 形状为(m,n,k),现在转化为(m*n,k)
img_reshape = img_arr.reshape(
[img_arr.shape[0]*img_arr.shape[1], img_arr.shape[2]])
svc = SVC(kernel='poly', degree=3) # 使用多项式核,次数为3
svc.fit(RGB_arr, label) # SVM 训练样本
predict = svc.predict(img_reshape) # 预测测试点
lake_bool = predict == 0.
lake_bool = lake_bool[:, np.newaxis] # 增加一列(一维变二维)
lake_bool_3col = np.concatenate(
(lake_bool, lake_bool, lake_bool), axis=1) # 变为三列
lake_bool_3d = lake_bool_3col.reshape(
(img_arr.shape[0], img_arr.shape[1], img_arr.shape[2])) # 变回三维数组(逻辑数组)
img_arr[lake_bool_3d] = 255.
img_split = Image.fromarray(img_arr.astype('uint8')) # 数组转image
img_split.show() # 显示分割之后的图像
img_split.save('split_duck.jpg') # 保存5、分水岭分割
def watershedSegment(filename): img = cv2.imread(filename) gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) # noise removal kernel = np.ones((3,3),np.uint8) opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2) # sure background area sure_bg = cv2.dilate(opening,kernel,iterations=3) # Finding sure foreground area dist_transform = cv2.distanceTransform(opening,cv2.DIST_L2,5) ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0) # Finding unknown region sure_fg = np.uint8(sure_fg) unknown = cv2.subtract(sure_bg,sure_fg) # Marker labelling ret, markers = cv2.connectedComponents(sure_fg) # Add one to all labels so that sure background is not 0, but 1 markers = markers+1 # Now, mark the region of unknown with zero markers[unknown==255]=0 markers = cv2.watershed(img,markers) img[markers == -1] = [255,0,0]
6、Kmeans分割
def kmeansSegment(filename,k):
f = open(filename,'rb') #二进制打开
data = []
img = Image.open(f) #以列表形式返回图片像素值
m,n = img.size #图片大小
for i in range(m):
for j in range(n): #将每个像素点RGB颜色处理到0-1范围内并存放data
x,y,z = img.getpixel((i,j))
data.append([x/256.0,y/256.0,z/256.0])
f.close()
img_data=np.mat(data)
row=m
col=n
label = KMeans(n_clusters=k).fit_predict(img_data) #聚类中心的个数为3
label = label.reshape([row,col]) #聚类获得每个像素所属的类别
pic_new = Image.new("L",(row,col)) #创建一张新的灰度图保存聚类后的结果
for i in range(row): #根据所属类别向图片中添加灰度值
for j in range(col):
pic_new.putpixel((i,j),int(256/(label[i][j]+1)))
pic_new.save('keans_'+str(k)+'.jpg')
plt.imshow(pic_new)
plt.show()以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容