Pandas Dataframe应用自定义
tigeriaf 人气:0前言:
在进行数据分析时,难免需要对数据集应用一些我们自定义的一些函数,或者其他库的函数,得到我们想要的数据,这种情况下,可能大家第一时间想到的是使用for循环遍历Dataframe对象,取到指定行/列的数据再进行自定义函数的应用,当然这种方法完全可以实现,但是效率不高,接下来就来介绍一下在Pandas中如何对数据集高效的进行自定义函数的应用。
应用函数
apply 方法
apply()函数是一个自定义函数作用于某一行或几行,或者某一列或多列上的每一个元素, 使用格式如下:
df.apply(func, axis=0, *args, **kwargs)
参数如下:
- func:指定函数
- axis:指定作用于行还是列,默认为0,表示作用于列,设置为1表示作用于行
- *args&**kwargs:接收任意数量、类型的参数,这些参数被传递到函数func
例如,对下面Dataframe执行进行操作:
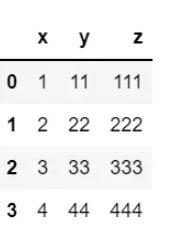
自定义"返回最大值"的函数并作用于该Dataframe:
def func(x):
return x.max()
df.apply(func)结果输出如下:

可见,结果返回了每列最大的值,如果想返回每行最大的值,设置axis=1即可。
当然apply()也支持传递lambda匿名函数。
applymap 方法
applymap()函数可以作用于DataFrame中的每一个元素,例如,转换DataFrame中数据的格式:
df.applymap(lambda x: '%.2f' % x)
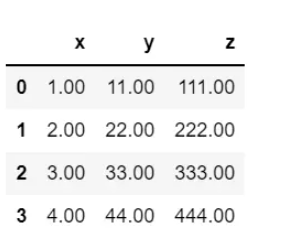
注意:Pandas还提供了一个map()方法,作用于Series对象,此类方法和Python原生的map()方法都很类似。
加载全部内容